package com.jikexueyuan.javajichu;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
/**
* 集合类的概念 集合类是一些特殊的类,
* 专门用来存放其他类对象的"容器"
* 主要是完成一些数据库和数据结构的功能
* 集合可以理解为一个动态数组,不同的是集合当中的所有内容可以进行扩充
* 特点:性能高容易扩展和修改
*
* List集合 Map集合的区别
* 1.list集合没有键值,Map有键值
* 键值是为了唯一标识事物而单独添加的属性,一定不要用事物本身的属性来做键值
* 能唯一表示某一事物的称之为键值
* 比如:一张身份证----一个人,身份证是外在加的属性
*
* ArrayList和Vector的区别与HashMap与Hashtable的区别
* ArrayList和HashMap都是线程异步的执行效率高但是安全性低。
* Vector和Hashtable都是线程同步的执行效率低但是安全性高
*/
public class JiHeLei {
public static void main(String[] args) {
//ArrayList List集合
ArrayList<XueSheng> list=new ArrayList<XueSheng>();//泛型
list.add(new XueSheng("小明",20, "男"));//集合就像数据库可以存放多个对象
list.add(new XueSheng("小可",23, "女"));
XueSheng sheng3=new XueSheng("小每",24, "女");
list.add(sheng3);
XueSheng sheng5=new XueSheng("小芳", 18, "女");
list.add(1, sheng5);//集合添加数据的功能,这里表示把sheng5对象添加到下标为1的数据当中
list.remove(3);//集合删除数据功能,这里表示把下标为三的数据删除掉
System.out.println("第一个集合大小"+list.size());
//遍历查看当前集合 集合的下标跟数据库跟数组的下标相同都是从0开始的
for (int i = 0; i < list.size(); i++) {
XueSheng sheng4=list.get(i);//get方法就是获取到当前集合的下标,当前的位置,//如果没有泛型当前方法泽需要强转
System.out.println("第"+(i+1)+"个学生的名字叫"+sheng4.getName());
}
//HashMap集合 Map集合
HashMap<String, XueSheng> map=new HashMap<String, XueSheng>();
XueSheng x1=new XueSheng("学生1",12, "男");
XueSheng x2=new XueSheng("学生2",11, "男");
XueSheng x3=new XueSheng("学生3",13, "男");
XueSheng x4=new XueSheng("学生4",14, "男");
map.put("001",x1);
map.put("002", x2);
map.put("003", x3);
map.put("004", x4);
System.out.println("第二个集合大小"+map.size());
if(map.containsKey("002")){//不需要遍历即可查询数据
XueSheng xs=map.get("002");
System.out.println("学生的名字叫"+xs.getName());
}
//HashMap遍历查询
Iterator<String> it=map.keySet().iterator();//把所有键值都给取出来
while(it.hasNext()){
String key=it.next().toString();
XueSheng xss=map.get(key);
System.out.println("学生的名字叫"+xss.getName());
}
}
}
class XueSheng {
public String name;
public int age;
public String sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public XueSheng(String name, int age, String sex) {
super();
this.name = name;
this.age = age;
this.sex = sex;
}
}1.java集合类图
1.1 
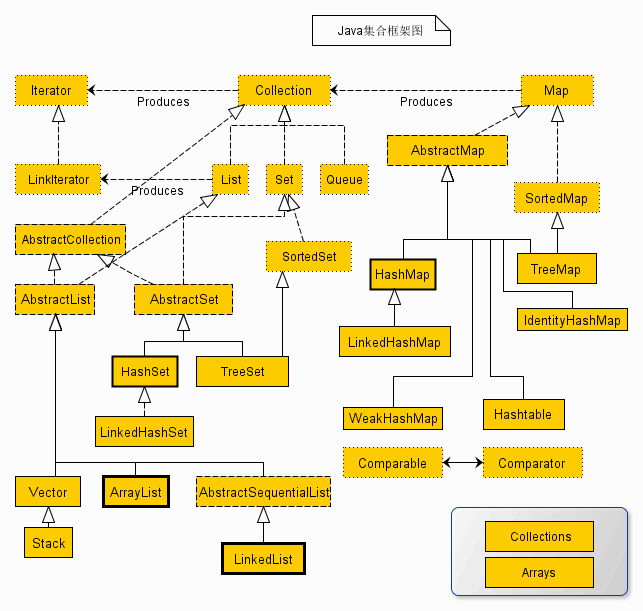
上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。
发现一个特点,上述所有的集合类,都实现了Iterator接口,这是一个用于遍历集合中元素的接口,主要包含hashNext(),next(),remove()三种方法。它的一个子接口LinkedIterator在它的基础上又添加了三种方法,分别是add(),previous(),hasPrevious()。也就是说如果是先Iterator接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历后的元素不会在遍历到,通常无序集合实现的都是这个接口,比如HashSet,HashMap;而那些元素有序的集合,实现的一般都是LinkedIterator接口,实现这个接口的集合可以双向遍历,既可以通过next()访问下一个元素,又可以通过previous()访问前一个元素,比如ArrayList。
还有一个特点就是抽象类的使用。如果要自己实现一个集合类,去实现那些抽象的接口会非常麻烦,工作量很大。这个时候就可以使用抽象类,这些抽象类中给我们提供了许多现成的实现,我们只需要根据自己的需求重写一些方法或者添加一些方法就可以实现自己需要的集合类,工作流昂大大降低。
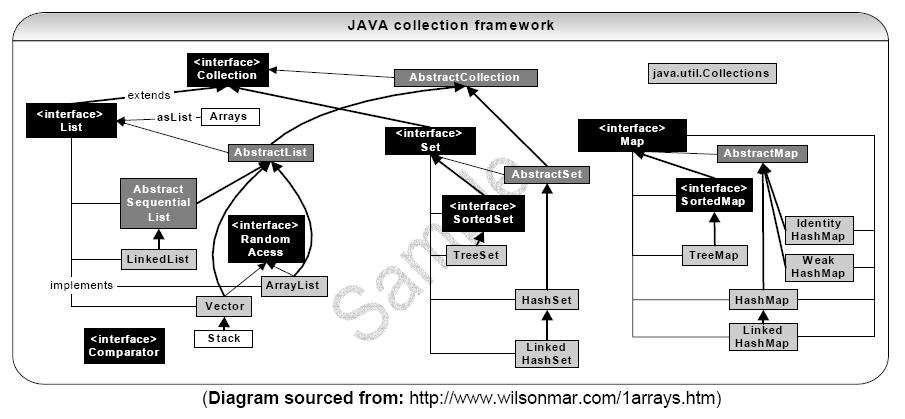
2.详解
2.1HashSet
HashSet是Set接口的一个子类,主要的特点是:里面不能存放重复元素,而且采用散列的存储方法,所以没有顺序。这里所说的没有顺序是指:元素插入的顺序与输出的顺序不一致。
代码实例:HashSetDemo
package edu.sjtu.erplab.collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class HashSetDemo {
public static void main(String[] args) {
Set<String> set=new HashSet<String>();
set.add("a");
set.add("b");
set.add("c");
set.add("c");
set.add("d");
//使用Iterator输出集合
Iterator<String> iter=set.iterator();
while(iter.hasNext())
{
System.out.print(iter.next()+" ");
}
System.out.println();
//使用For Each输出结合
for(String e:set)
{
System.out.print(e+" ");
}
System.out.println();
//使用toString输出集合
System.out.println(set);
}
}代码实例:SetTest
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
public class SetTest {
public static void main(String[] args) throws FileNotFoundException {
Set<String> words=new HashSet<String>();
//通过输入流代开文献
//方法1:这个方法不需要抛出异常
InputStream inStream=SetTest.class.getResourceAsStream("Alice.txt");
//方法2:这个方法需要抛出异常
//InputStream inStream = new FileInputStream("D:\\Documents\\workspace\\JAVAStudy\\src\\edu\\sjtu\\erplab\\collection\\Alice.txt");
Scanner in=new Scanner(inStream);
while(in.hasNext())
{
words.add(in.next());
}
Iterator<String> iter=words.iterator();
for(int i=0;i<5;i++)
{
if(iter.hasNext())
System.out.println(iter.next());
}
System.out.println(words.size());
}
}2.2ArrayList
ArrayList是List的子类,它和HashSet想法,允许存放重复元素,因此有序。集合中元素被访问的顺序取决于集合的类型。如果对ArrayList进行访问,迭代器将从索引0开始,每迭代一次,索引值加1。然而,如果访问HashSet中的元素,每个元素将会按照某种随机的次序出现。虽然可以确定在迭代过程中能够遍历到集合中的所有元素,但却无法预知元素被访问的次序。
代码实例:ArrayListDemo
package edu.sjtu.erplab.collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
List<String> arrList=new ArrayList<String>();
arrList.add("a");
arrList.add("b");
arrList.add("c");
arrList.add("c");
arrList.add("d");
//使用Iterator输出集合
Iterator<String> iter=arrList.iterator();
while(iter.hasNext())
{
System.out.print(iter.next()+" ");
}
System.out.println();
//使用For Each输出结合
for(String e:arrList)
{
System.out.print(e+" ");
}
System.out.println();
//使用toString输出集合
System.out.println(arrList);
}
}2.3LinkedList
LinkedList是一种可以在任何位置进行高效地插入和删除操作的有序序列。
代码实例:LinkedListTest
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class LinkedListTest {
public static void main(String[] args) {
List<String> a=new ArrayList<String>();
a.add("a");
a.add("b");
a.add("c");
System.out.println(a);
List<String> b=new ArrayList<String>();
b.add("d");
b.add("e");
b.add("f");
b.add("g");
System.out.println(b);
//ListIterator在Iterator基础上添加了add(),previous()和hasPrevious()方法
ListIterator<String> aIter=a.listIterator();
//普通的Iterator只有三个方法,hasNext(),next()和remove()
Iterator<String> bIter=b.iterator();
//b归并入a当中,间隔交叉得插入b中的元素
while(bIter.hasNext())
{
if(aIter.hasNext())
aIter.next();
aIter.add(bIter.next());
}
System.out.println(a);
//在b中每隔两个元素删除一个
bIter=b.iterator();
while(bIter.hasNext())
{
bIter.next();
if(bIter.hasNext())
{
bIter.next();//remove跟next是成对出现的,remove总是删除前序
bIter.remove();
}
}
System.out.println(b);
//删除a中所有的b中的元素
a.removeAll(b);
System.out.println(a);
}
}2.4HashMap
1.HashMap的数据结构
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
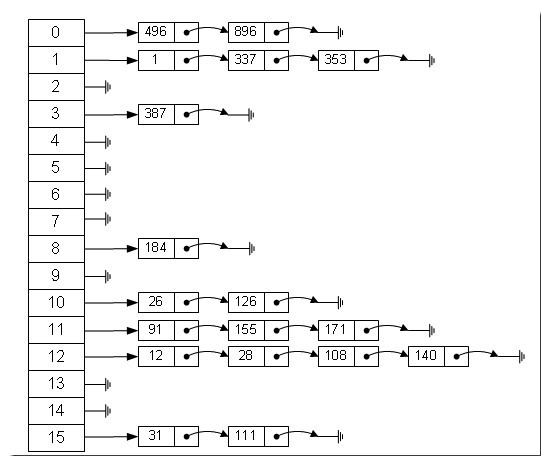
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
1.首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
2.HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
/存储时:
int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
//取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];到这里我们轻松的理解了HashMap通过键值对实现存取的基本原理
3.疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规则加长长度。
3.解决hash冲突的办法
开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
再哈希法
链地址法
建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4.实现自己的HashMap
Entry.java
package edu.sjtu.erplab.hash;
public class Entry<K,V>{
final K key;
V value;
Entry<K,V> next;//下一个结点
//构造函数
public Entry(K k, V v, Entry<K,V> n) {
key = k;
value = v;
next = n;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Entry))
return false;
Entry e = (Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}MyHashMap.java
//保证key与value不为空
public class MyHashMap<K, V> {
private Entry[] table;//Entry数组表
static final int DEFAULT_INITIAL_CAPACITY = 16;//默认数组长度
private int size;
// 构造函数
public MyHashMap() {
table = new Entry[DEFAULT_INITIAL_CAPACITY];
size = DEFAULT_INITIAL_CAPACITY;
}
//获取数组长度
public int getSize() {
return size;
}
// 求index
static int indexFor(int h, int length) {
return h % (length - 1);
}
//获取元素
public V get(Object key) {
if (key == null)
return null;
int hash = key.hashCode();// key的哈希值
int index = indexFor(hash, table.length);// 求key在数组中的下标
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k)))
return e.value;
}
return null;
}
// 添加元素
public V put(K key, V value) {
if (key == null)
return null;
int hash = key.hashCode();
int index = indexFor(hash, table.length);
// 如果添加的key已经存在,那么只需要修改value值即可
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;// 原来的value值
}
}
// 如果key值不存在,那么需要添加
Entry<K, V> e = table[index];// 获取当前数组中的e
table[index] = new Entry<K, V>(key, value, e);// 新建一个Entry,并将其指向原先的e
return null;
}
}MyHashMapTest.java
public class MyHashMapTest {
public static void main(String[] args) {
MyHashMap<Integer, Integer> map = new MyHashMap<Integer, Integer>();
map.put(1, 90);
map.put(2, 95);
map.put(17, 85);
System.out.println(map.get(1));
System.out.println(map.get(2));
System.out.println(map.get(17));
System.out.println(map.get(null));
}
}比较:
是否有序
Collection 否
List 是
Set
AbstractSet 否
HashSet 否
TreeSet 是
Map
AbstractMap 否
HashMap 否
TreeMap 是
是否允许元素重复
Collection 是
List 是
Set
AbstractSet 否
HashSet 否
TreeSet 否
Map 使用key-value来映射和存储数据,key必须唯一,value可以重复
AbstractMap
HashMap
TreeMap
作者:xwdreamer
出处:http://www.cnblogs.com/xwdreamer/archive/2012/05/30/2526822.html
欢迎任何形式的转载,但请务必注明出处。