Jbd6:Hive
教程地址
https://github.com/datawhalechina/juicy-bigdata/
0. 数据仓库
0.1 为什么要有数据仓库
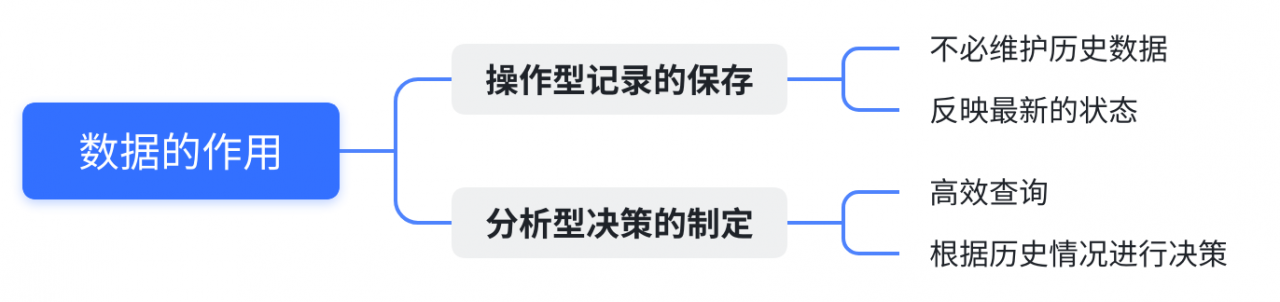
对于分析型决策而言,其优化需要高性能地完成用户的查询
因此引出了数据仓库的概念
0.2 数据仓库概念
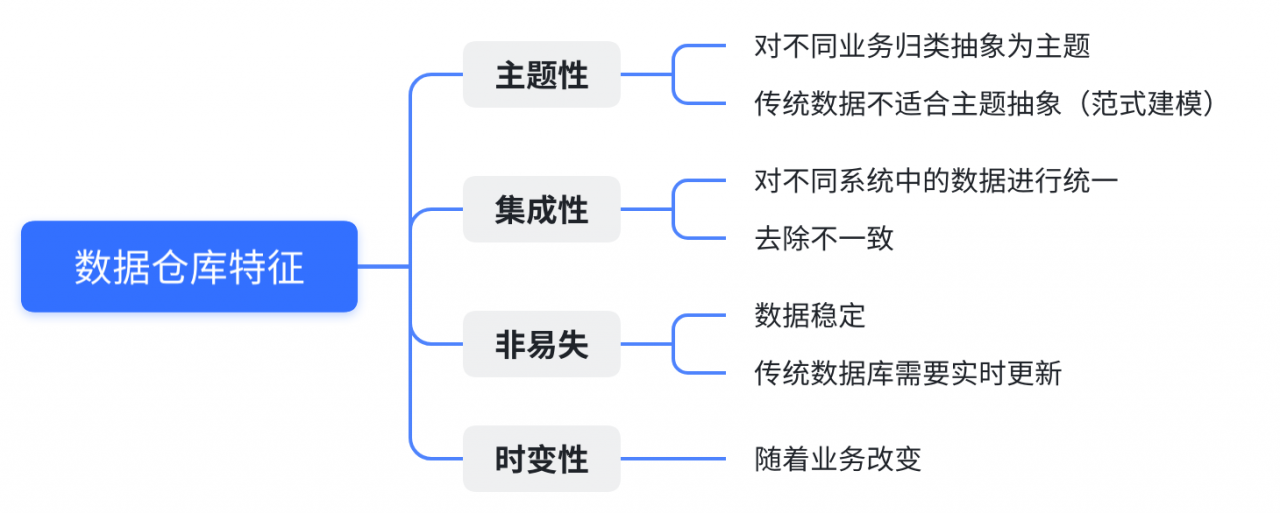
主题性
各个业务系统的数据可能是相互分离的,但数据仓库则是面向主题的
其将不同的业务进行归类并分析,将数据抽象为主题用于对应分析对象
而操作型记录(即传统数据)对数据的划分并不适用于决策分析
在数据仓库中,基于主题的数据被划分为各自独立的领域
每个领域有各自的逻辑内涵但互不交叉
在抽象层次上对数据进行完整的、一致的和准确的描述
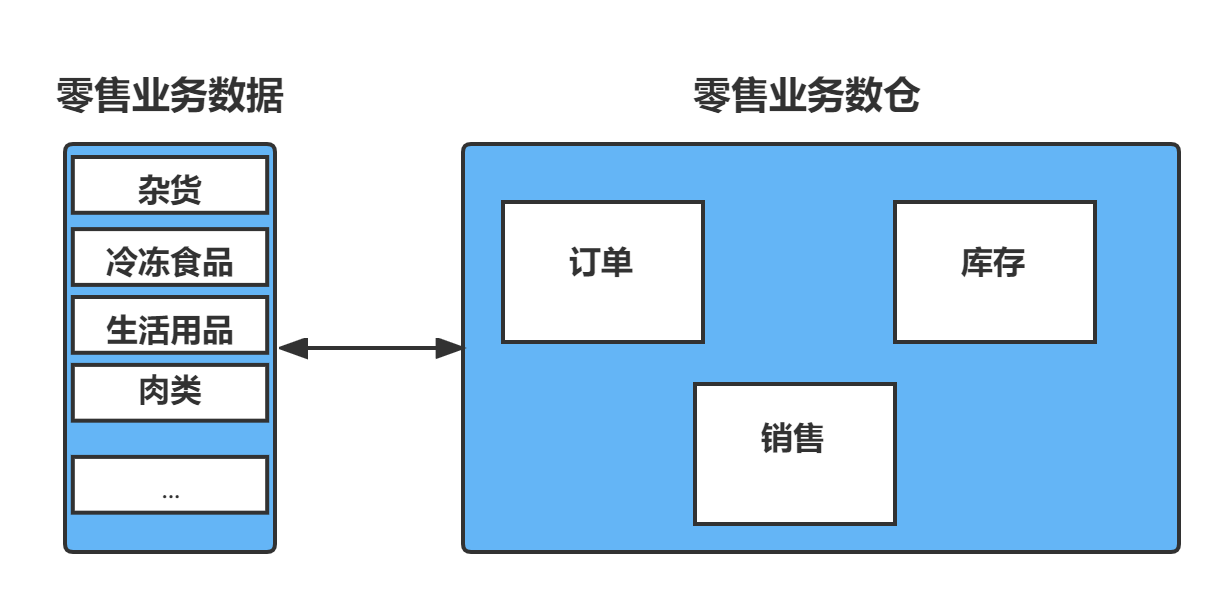
以零售业务的过程为例:将多个零售业务数据(杂货、冷冻食品、生活用品、肉类等)
依据业务主题进行数据划分,可创建一个具有订单、库存和销售等多个业务领域的零售业务数仓
集成性
同一数据会分布在不同的业务过程中,因此需要在入库前进行口径统一
即统一数据来源中的歧义、单位、字长等元素,并进行总和计算来聚合成新的数据
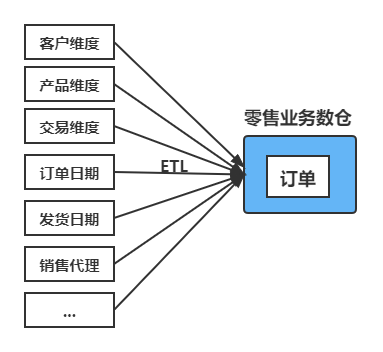
以上述零售业务过程中的订单主题为例,其通常会包括订单、发货和发票三个业务
这些过程会产生一些新的指标,如:销售额、发票收入等,这些就是新的数据
非易失性
数据仓库的目的是分析数据中的规律,因此需要保证其稳定性
而传统的操作型数据库主要服务于日常的业务操作
也就是说业务所产生的数据会实时更新到数据库中
以便业务应用能够迅速获得当前最新数据进行正常的业务运作
而数据仓库通常是保存历史业务数据,每隔一段时间批量导入新的数据
时变性
数据仓库是根据业务需要来建立的,代表了一个业务过程
因此数据仓库分析的结果只能反映过去的业务情况
当业务变化后,数据仓库需要随之改变,以适应分析决策的需要
这里可能也就是上文所说的,每隔一段时间导入一批数据
0.3 数据仓库的体系结构
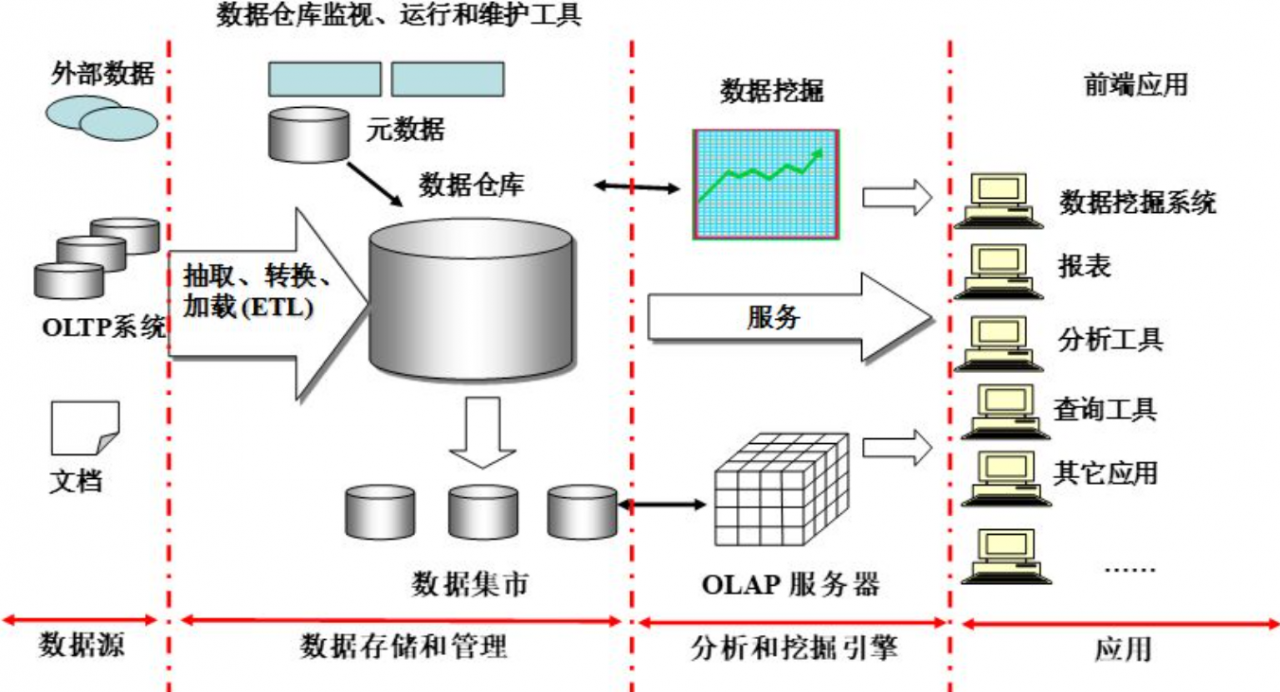
数据源:
数据来源包括外部数据、现有业务系统和文档资料等
数据存储和管理:
组件包括数据仓库、数据集市、数据仓库监视
以及运行与维护工具和元数据管理等
数据服务:
为前端工具和应用提供数据服务
包括直接从数据仓库中获取数据提供给前端使用
或者通过OLAP服务器为前端应用提供更为复杂的数据服务
数据应用:
直接面向最终用户
包括数据工具、自由报表工具、数据分析工具
以及数据挖掘工具和各类应用系统。
0.4 面临的挑战
- 无法满足快速增长的海量数据存储需求
- 无法有效处理不同类型的数据
- 计算和处理能力不足
1. Hive基本概念
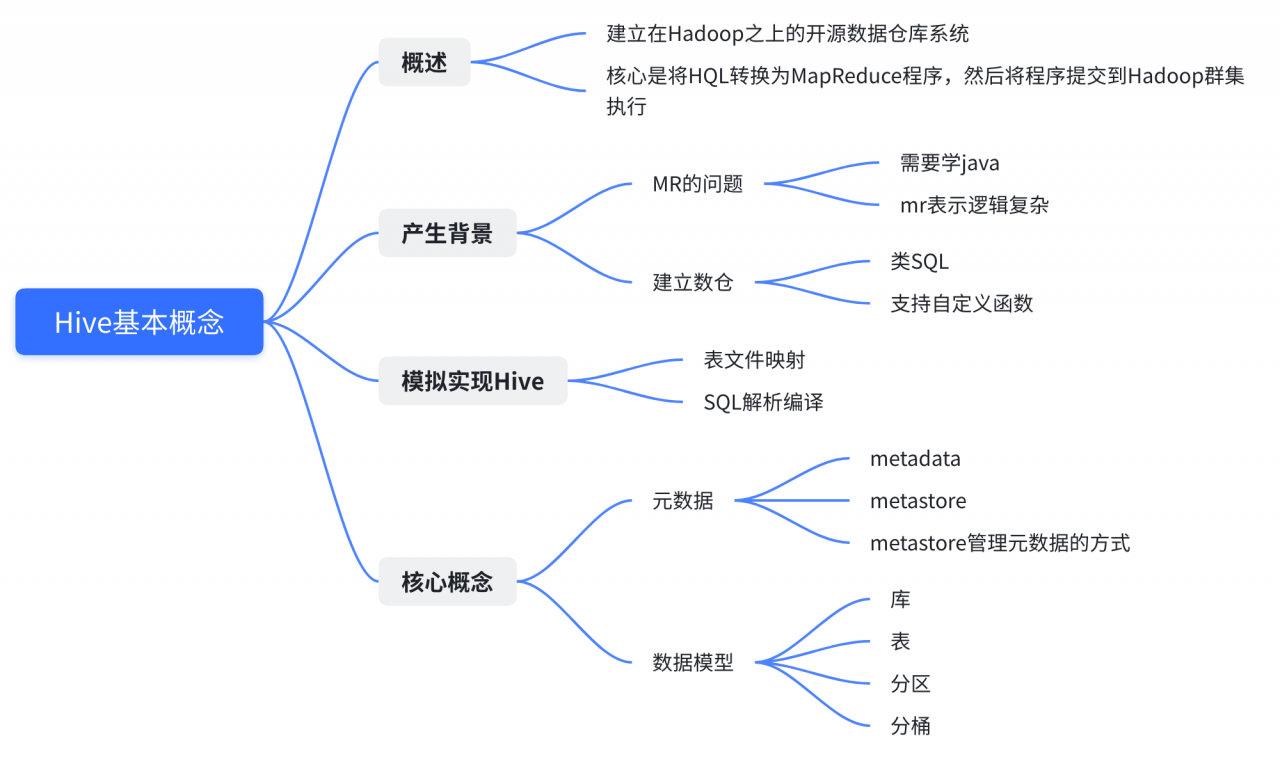
1.1 概述
Hive是建立在Hadoop之上的一种数仓工具
该工具的功能是将结构化、半结构化的数据文件映射为一张数据库表
基于数据库表,提供了一种类似SQL的查询模型(HQL)
用于访问和分析存储在Hadoop文件中的大型数据集
Hive本身并不具备存储功能,其核心是将HQL转换为MapReduce程序
然后将程序提交到Hadoop集群中执行相应的MapReduce流程

其主要特点如下:
简单、容易上手
其提供了类似SQL的查询语言HiveQL,大大降低了使用门槛
灵活性高
可以针对不同情况自定义用户函数(UDF)和存储格式
扩展性好
为超大的数据集设计的计算和存储能力,可轻易扩展集群
开放性好
统一的元数据管理,可与presto/impala/sparksql等共享数据
适合离线
执行延迟高,不适合做实时处理,但适合做海量数据的离线处理
1.2 产生背景
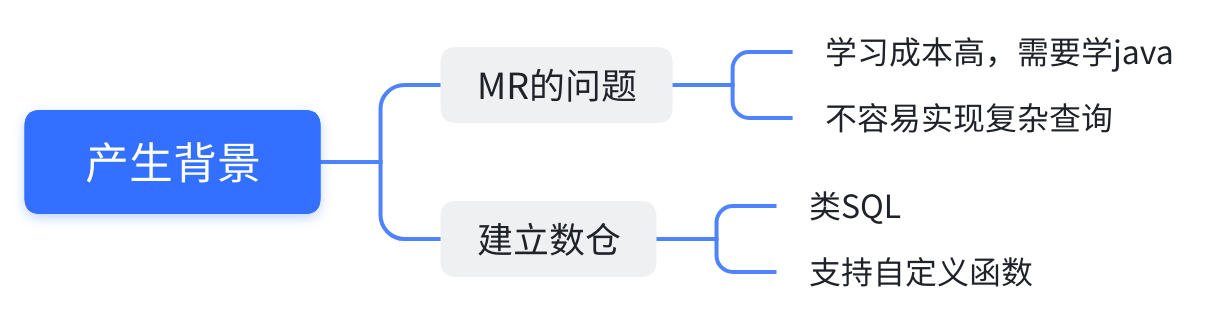
使用成本高:
使用MapReduce直接处理数据时,需要掌握Java等编程语言
其学习成本较高,而且使用MapReduce不容易实现复杂查询
建立分析型数仓的需求:
Hive支持类SQL的查询以及支持自定义函数,可以作为数据仓库的工具
1.3 Hive与Hadoop生态系统
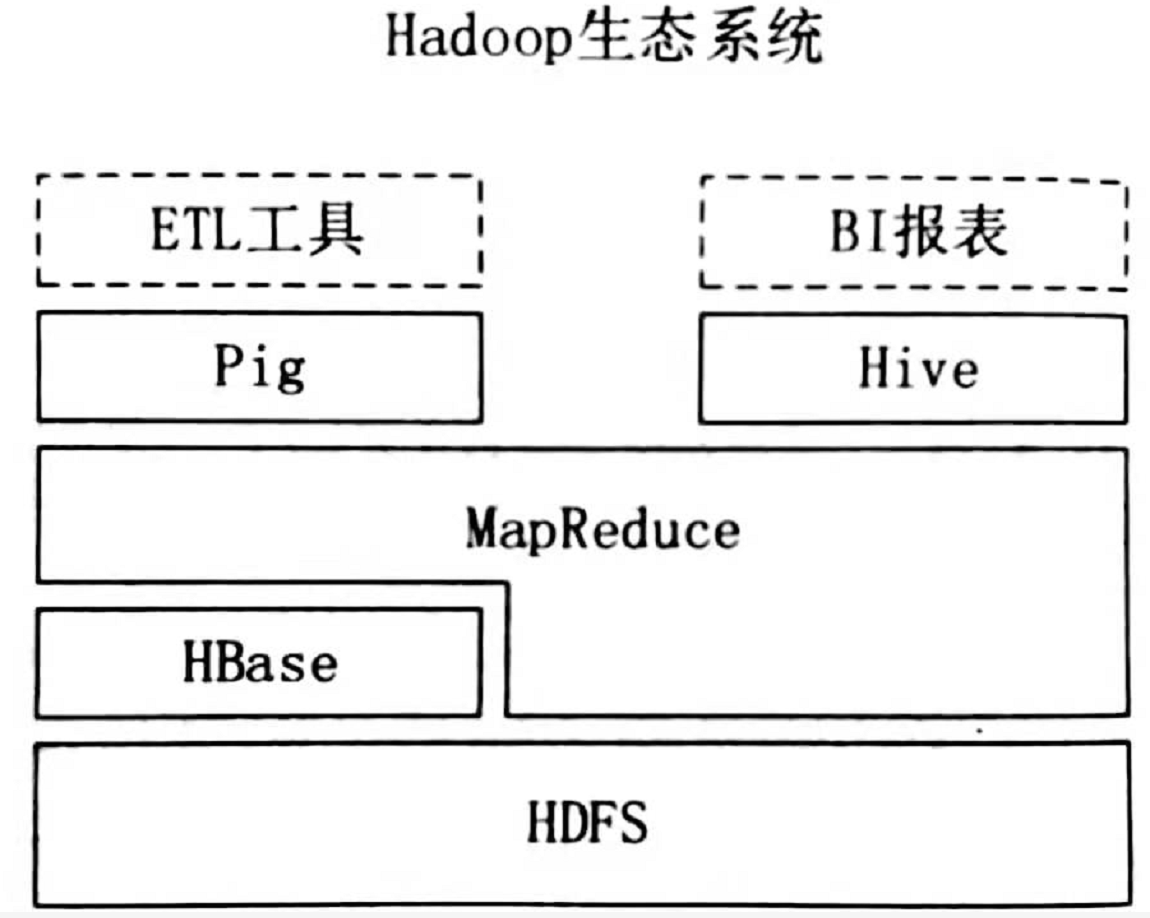
Hive与Hadoop生态的联系
HDFS作为高可靠的底层存储方式,可以执行海量数据的存储
MapReduce对这些海量数据进行批处理,可以实现高性能计算
Hive架构位于MapReduce 、HDFS之上,其自身并不存储和处理数据
而是分别借助于HDFS和MapReduce来实现对海量数据的存储和处理
用HiveQL语句编写的处理逻辑,最终都要转换成MapReduce任务来运行
Pig可以作为Hive的替代工具,它是一种数据流的语言和运行环境
其适用于在Hadoop平台上查询半结构化数据集,常用于数据抽取(ETL)部分
即将外部数据装载到Hadoop集群中,然后转换为用户需要的数据格式
Hive与HBase的区别
HBase是一个数据库,提供数据的实时访问功能
而Hive只能处理静态数据,主要是BI报表数据。
在Hadoop上设计Hive,是为了减少编写复杂MapReduce应用程序
在Hadoop上设计HBase是为了实现对海量数据的实时访问工作
所以,HBase与Hive的功能是互补的,它实现了Hive不能提供的功能
1.4 Hive与传统数据库的对比
| 对比内容 | Hive | 传统数据库 |
|---|---|---|
| 数据存储 | HDFS | 本地文件系统 |
| 索引 | 支持有限索引 | 支持复杂索引 |
| 分区 | 支持 | 支持 |
| 执行引擎 | MapReduce、Tez、Spark | 自身的执行引擎 |
| 执行延迟 | 高 | 低 |
| 扩展性 | 好 | 有限 |
| 数据规模 | 大 | 小 |
1.5 模拟实现Hive
需求:
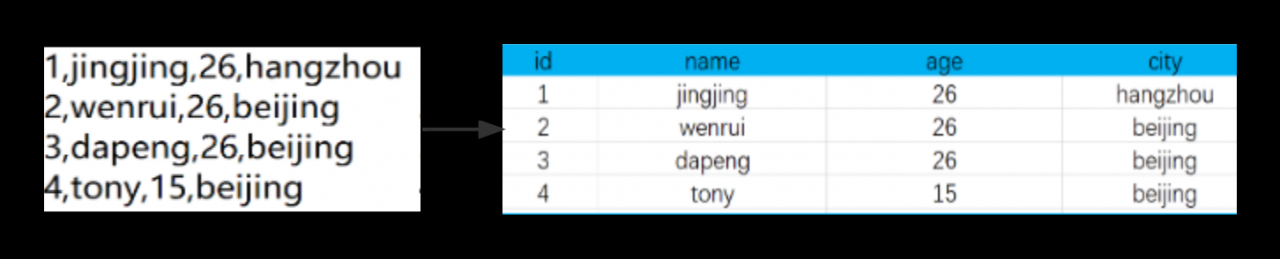
现在有一个文件:
1,jingjing,26,hangzhou 2,wenrui,26,beijing 3,dapeng,26,beijing 4,tony,15,hebei我们需要据其设计Hive数仓
使得用户可以通过编写SQL语句
来处理HDFS上的结构化数据
从而统计北京大于20岁的人数
分析
SQL是对表进行操作,所以我们要先建表
也就是说我们要注意:表的位置
表是对应于哪个文件的
字段的位置
表的列是对应文件的哪一个字段
内容的分割
文件字段之间的分隔符是什么
执行
完成了表和文件的映射后,Hive会对SQL语句进行语法校验
并且根据记录的元数据信息对SQL进行解析,制定执行计划
并将执行计划转化为MapReduce程序来执行
最终将执行的结果封装返回给用户
2. Hive核心概念
2.1 Hive数据类型
2.1.1 基本数据类型
| 大类 | 类型 |
| Integers(整型) | TINYINT:1字节的有符号整数; SMALLINT:2字节的有符号整数; INT:4字节的有符号整数; BIGINT:8字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN:TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT:单精度浮点型; DOUBLE:双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL:用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING:指定字符集的字符序列; VARCHAR:具有最大长度限制的字符序列; CHAR:固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP:时间戳; TIMESTAMP WITH LOCAL TIME ZONE:时间戳,纳秒精度; DATE:日期类型 |
| Binary types(二进制类型) | BINARY:字节序列 |
TIMESTAMP和TIMESTAMP WITH LOCAL TIME ZONE的区别如下:
TIMESTAMP WITH LOCAL TIME ZONE:
用户提交TIMESTAMP给数据库时,会被转换成数据库所在的时区来保存
查询时,则按照查询客户端的不同,转换为查询客户端所在时区的时间
TIMESTAMP :
提交的时间按照原始时间保存,查询时,也不做任何转换。
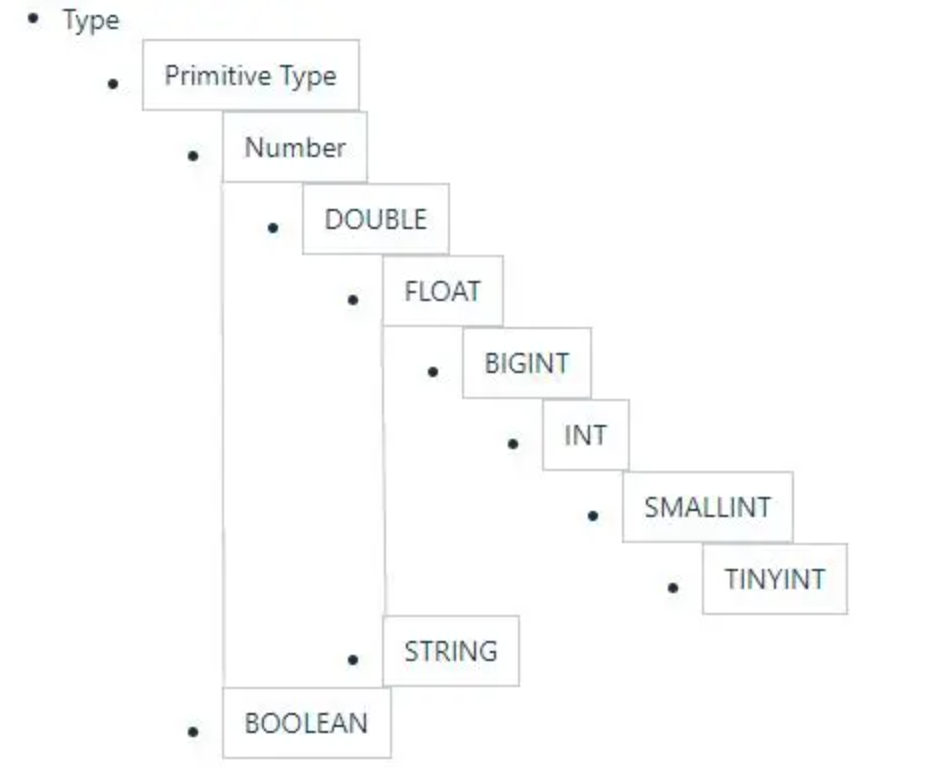
2.1.2 隐式转换
Hive中基本数据类型遵循以下的层次结构
按照这个层次结构,子类型到祖先类型允许隐式转换
例如INT类型的数据允许隐式转换为BIGINT类型
额外注意的是,允许将STRING类型隐式转换为DOUBLE类型
2.1.3 复杂类型
| 类型 | 描述 | 示例 |
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用名称.字段名方式进行访问 | STRUCT('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用名称[key]的方式访问对应的值 | map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用名称[index]访问对应的值 | ARRAY('a', 'b', 'c', 'd') |
2.1.4 示例
CREATE TABLE students(
name STRING, -- 姓名
age INT, -- 年龄
subject ARRAY<STRING>, -- 学科
score MAP<STRING,FLOAT>, -- 各个学科考试成绩
address STRUCT<houseNumber:int, street:STRING, city:STRING, province:STRING> -- 家庭居住地址
) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
2.2 Hive数据模型
2.2.1 库
MySQL中默认数据库是default,用户可以创建不同的库和表
Hive也可以分为不同的数据(仓)库,和传统数据库保持一致
在传统数仓中创建database,默认的数据库也是default
Hive中的库相当于关系数据库中的命名空间
它的作用是将用户和数据库的表进行隔离。
2.2.2 表
Hive中的表所对应的数据是存储在HDFS中
而表相关的元数据是存储在关系数据库中
Hive中的表分为内部表和外部表两种类型
两者的区别在于数据的访问和删除:
表的访问
内部表的加载数据和创建表的过程是分开的
在加载数据时,实际数据会被移动到数仓目录中
之后对数据的访问是在数仓目录实现
而外部表加载数据和创建表是同一个过程
对数据的访问是读取HDFS中的数据
表的删除
删除内部表时,因为数据移动到了数仓目录中
因此删除表时,表中数据和元数据会被同时删除
外部表因为数据还在HDFS中,删除表时并不影响数据
表的创建
创建表时不做任何指定,默认创建的就是内部表
想要创建外部表,则需要使用External进行修饰
| 对比内容 | 内部表 | 外部表 |
| 数据存储位置 | 内部表数据存储的位置由hive.Metastore.warehouse.dir参数指定, 默认情况下,表的数据存储在HDFS的/user/hive/warehouse/数据库名.db/表名/目录下 | 外部表数据的存储位置创建表时由Location参数指定 |
| 导入数据 | 在导入数据到内部表,内部表将数据移动到自己的数据仓库目录下, 数据的生命周期由Hive来进行管理 | 外部表不会将数据移动到自己的数据仓库目录下, 只是在元数据中存储了数据的位置 |
| 删除表 | 删除元数据(metadata)和文件 | 只删除元数据(metadata) |
2.2.3 分区
分区是一个优化的手段,目的是减少全表扫描,提高查询效率
在Hive中存储的方式就是表的主目录文件夹下的子文件夹
子文件夹的名字表示所定义的分区列名字
2.2.4 分桶
分桶和分区的区别在于:分桶是针对数据文件本身进行拆分
即根据表中字段(例如,编号ID)的值,经过hash划分成小文件
分桶后,HDFS中的数据文件会变为多个小文件
分桶的优点是优化join查询和方便抽样查询
3. Hive系统结构
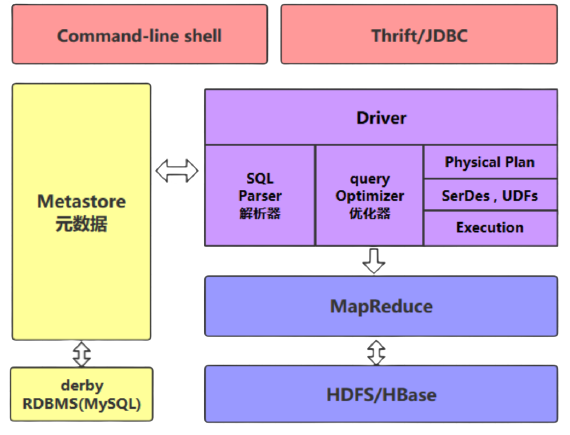
3.1 用户接口模块
用户接口模块包括CLI、Hive网页接口(Hive Web Interface,HWI)
以及JDBC、ODBC、Thrift Server等
主要实现外部应用对Hive的访问
用户可以使用以下两种方式来操作数据:
CLI(command-line shell):
Hive自带的一个命令行客户端工具
用户可以通过Hive命令行的方式来操作数据
HWI(Thrift/JDBC):
HWI是Hive的一个简单网页
JDBC、ODBS和Thrift Server可以向用户提供编程访问的接口
用户可以按照标准的JDBC的方式,通过Thrift协议操作数据
3.2 驱动模块
驱动模块(Driver)包括编译器、优化器、执行器等
所采用的执行引擎可以是 MapReduce、Tez或Spark等
当采用MapReduce时,驱动把HiveQL转换成MapReduce作业
所有命令和查询都会进入驱动模块,其会对输入进行解析编译
再对计算过程进行优化,然后按照指定的步骤执行
3.3 元数据存储模块
3.3.1 元数据
元数据(metadata)是描述数据的数据
对于Hive来说,元数据是用来描述HDFS文件和表的对应关系
即文件位置、列的顺序关系、内容的分隔符
Hive的元数据存储在关系数据库中,HDFS中存储的是数据
Hive内置的是Derby、第三方的是MySQL
在Hive中,所有的元数据默认存储在Hive内置的Derby数据库中
但由于Derby只能有一个实例,也就是说不能有多个同时访问
所以在实际生产环境中,通常使用 MySQL代替Derby
元数据存储模块(Metastore)是一个独立的关系数据库
通常是与MySQL数据库连接后创建的一个MySQL实例
也可以是Hive自带的Derby数据库实例,提供元数据服务
元数据存储模块中主要保存表模式和其他系统元数据
如表的名称、表的列及其属性、表的分区及其属性
以及表的属性、表中数据所在位置信息等
它提供给Hive操作管理访问元数据的一个服务
具体操作为Metastore对外提供一个服务地址
使客户端能够连接Hive,以此来对元数据进行访问
使用Metastore的好处如下:
使用元数据访问数据
元数据被保存在关系数据库中,Hive提供元数据服务
通过对外的服务地址,用户能够使用客户端连接Hive,访问并操作元数据
支持多个客户端的连接
而客户端无需关心数据的存储地址,实现了数据访问层面的解耦操作
共享表
因此如果你在Hive上创建了一张表
然后在presto/impala/sparksql中都是可以直接使用的
它们会从Metastore中获取统一的元数据信息
同样的你在presto/impala/sparksql中创建一张表
在Hive中也可以直接使用

3.3.2 Metastore管理元数据的方式
3.3.2.1 内嵌模式
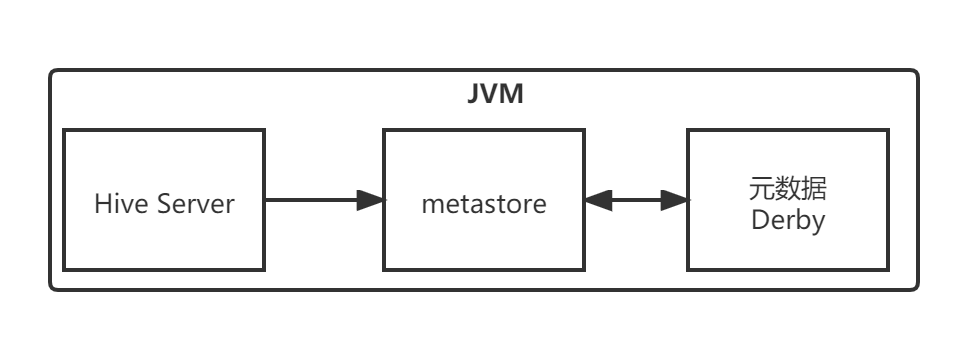
Metastore默认的部署模式是Metastore元数据服务和Hive服务融合在一起。
在这种模式下,Hive服务(即Hive驱动本身)、元数据服务Metastore
以及元数据metadata(用于存储映射信息)都在同一个JVM进程中
元数据存储在内置的Derby数据库
当启动HiveServer进程时,Derby和Metastore都会启动
不需要额外启动Metastore服务
但是,一次只能支持一个用户访问,适用于测试场景。
3.3.2.2 本地模式
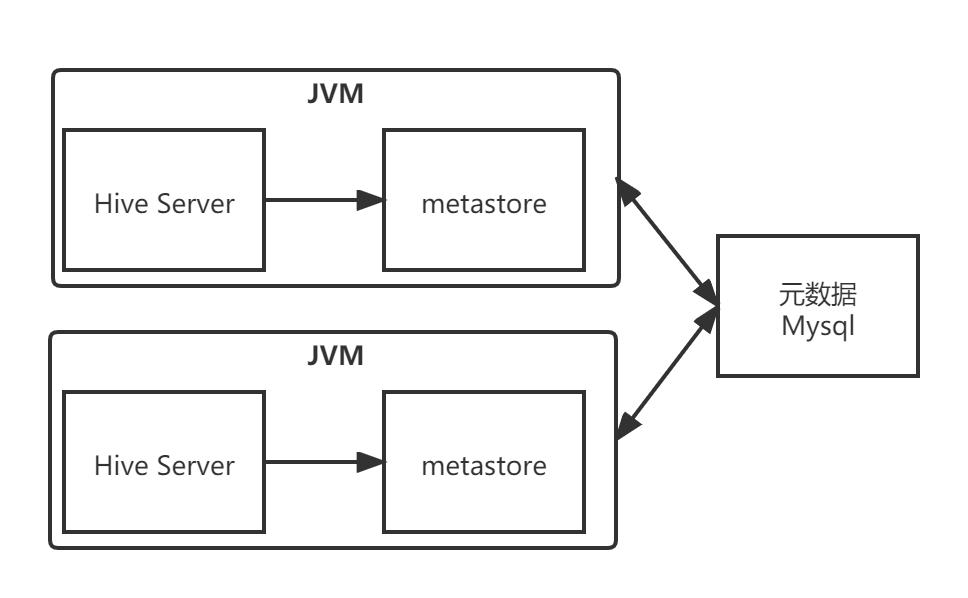
本地模式与内嵌模式的区别在于,是否把元数据提取出来
让Metastore服务与HiveServer主进程在同一个JVM进程中运行
而存储元数据的数据库在单独的进程中运行
元数据一般存储在MySQL关系型数据库中
但是,每启动一个Hive服务,都会启动一个Metastore服务
多个人使用时,会启用多个Metastore服务。
3.3.2.3 远程模式
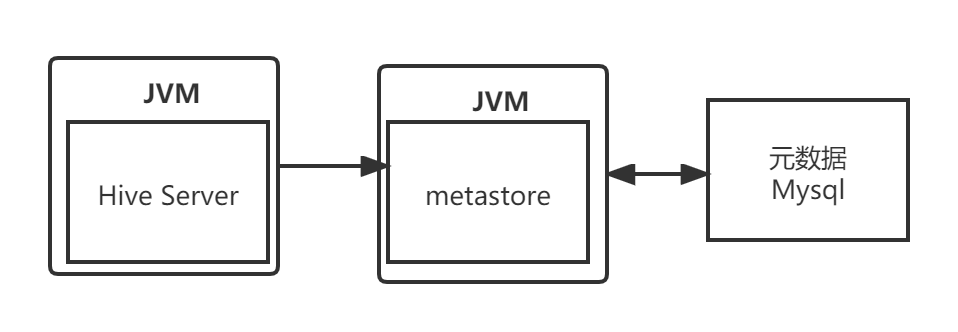
既然可以把元数据存储给提取出来
也可以考虑把Metastore给提取出来变为单独一个进程
把Metastore单独进行配置,并在单独的进程中运行
这意可以保证全局唯一,从而保证数据访问的安全性
即不随Hive的启动而启动,相对于Hive是全局独立的
其优点是把Metastore服务独立出来,可以安装到远程的服务器集群里
从而解耦Hive服务和Metastore服务,保证Hive的稳定运行
3.4 HQL的执行流程
Hive在执行一条HQL语句时,会经过以下步骤:
语法解析:
Antlr定义SQL的语法规则,完成SQL词法,语法解析
将SQL转化为抽象语法树AST Tree;
语义解析:
遍历AST Tree,抽象出查询的基本组成单元QueryBlock
生成逻辑执行计划:
遍历QueryBlock,翻译为执行操作树OperatorTree
优化逻辑执行计划:
逻辑层优化器进行OperatorTree变换
合并不必要的ReduceSinkOperator,减少shuffle数据量
生成物理执行计划:
遍历OperatorTree,翻译为MapReduce任务
优化物理执行计划:
物理层优化器进行MapReduce任务的变换,生成最终的执行计划。
4. Hive编程实战
4.1 实验一:Hive的安装部署和管理
4.1.1 实验准备
Ubuntu 20.04,Java,Hadoop 3.3.1
4.1.2 实验内容
基于上述实验环节,学习并掌握Hive的安装部署和管理。
4.1.3 实验步骤
4.1.3.1 解压安装包
master@VM-0-12-ubuntu:/opt/JuciyBigData$ sudo tar -zxvf apache-hive-2.3.9-bin.tar.gz -C /opt/
···
apache-hive-2.3.9-bin/hcatalog/sbin/webhcat_config.sh
apache-hive-2.3.9-bin/hcatalog/sbin/webhcat_server.sh
master@VM-0-12-ubuntu:/opt/JuciyBigData$
4.1.3.2 更改文件夹名和所属用户
master@VM-0-12-ubuntu:/opt$ ll
total 1496472
drwxr-xr-x 8 root root 4096 Mar 21 19:51 ./
drwxr-xr-x 20 root root 4096 Mar 21 19:52 ../
drwxr-xr-x 10 root root 4096 Mar 21 19:51 apache-hive-2.3.9-bin/
drwxr-xr-x 14 master master 4096 Mar 18 23:14 hadoop/
drwxr-xr-x 8 master master 4096 Mar 19 20:19 hbase/
drwxr-xr-x 8 master master 4096 Sep 27 20:29 java/
drwxr-xr-x 2 root root 4096 Feb 12 17:51 JuciyBigData/
-rw-r--r-- 1 root root 1532346446 Mar 15 18:28 JuciyBigData.zip
drwxr-xr-x 2 master master 4096 Mar 19 21:49 master/
master@VM-0-12-ubuntu:/opt$ sudo mv /opt/apache-hive-2.3.9-bin/ /opt/hive
master@VM-0-12-ubuntu:/opt$ sudo chown -R master:master /opt/hive/
master@VM-0-12-ubuntu:/opt$ ll
total 1496472
drwxr-xr-x 8 root root 4096 Mar 21 19:52 ./
drwxr-xr-x 20 root root 4096 Mar 21 19:52 ../
drwxr-xr-x 14 master master 4096 Mar 18 23:14 hadoop/
drwxr-xr-x 8 master master 4096 Mar 19 20:19 hbase/
drwxr-xr-x 10 master master 4096 Mar 21 19:51 hive/
drwxr-xr-x 8 master master 4096 Sep 27 20:29 java/
drwxr-xr-x 2 root root 4096 Feb 12 17:51 JuciyBigData/
-rw-r--r-- 1 root root 1532346446 Mar 15 18:28 JuciyBigData.zip
drwxr-xr-x 2 master master 4096 Mar 19 21:49 master/
master@VM-0-12-ubuntu:/opt$
4.1.3.3 设置HIVE_HOME环境变量
master@VM-0-12-ubuntu:/opt$ sudo vim /etc/profile
master@VM-0-12-ubuntu:/opt$ tail /etc/profile
export PATH=$HADOOP_HOME/bin:$PATH
# hbase
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
# hive
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
master@VM-0-12-ubuntu:/opt$ source /etc/profile
master@VM-0-12-ubuntu:/opt$
4.1.3.4 安装MySQL
master@VM-0-12-ubuntu:/opt$ sudo apt update
Hit:1 http://mirrors.tencentyun.com/ubuntu focal InRelease
Get:2 http://mirrors.tencentyun.com/ubuntu focal-security InRelease [114 kB]
Get:3 http://mirrors.tencentyun.com/ubuntu focal-updates InRelease [114 kB]
Fetched 228 kB in 1s (364 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
97 packages can be upgraded. Run 'apt list --upgradable' to see them.
master@VM-0-12-ubuntu:/opt$ sudo apt install mysql-server
···
done!
update-alternatives: using /var/lib/mecab/dic/ipadic-utf8 to provide /var/lib/mecab/dic/debian (mecab-dictionary) in auto mode
Setting up mysql-server (8.0.28-0ubuntu0.20.04.3) ...
Processing triggers for systemd (245.4-4ubuntu3.15) ...
Processing triggers for man-db (2.9.1-1) ...
Processing triggers for libc-bin (2.31-0ubuntu9.2) ...
master@VM-0-12-ubuntu:/opt$ sudo netstat -tap | grep mysql
tcp 0 0 localhost:33060 0.0.0.0:* LISTEN 663796/mysqld
tcp 0 0 localhost:mysql 0.0.0.0:* LISTEN 663796/mysqld
master@VM-0-12-ubuntu:/opt$ systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-03-21 19:55:54 CST; 56s ago
Main PID: 663796 (mysqld)
Status: "Server is operational"
Tasks: 38 (limit: 2265)
Memory: 362.6M
CGroup: /system.slice/mysql.service
└─663796 /usr/sbin/mysqld
master@VM-0-12-ubuntu:/opt$
安装完毕之后就直接是运行状态了,其他命令如下:
sudo netstat -tap | grep mysql #mysql节点处于LISTEN状态表示启动成功
sudo service mysql start #开启
sudo service mysql stop #关闭
sudo service mysql restart #重启
默认密码为空,好像还是不要设置比较好1
4.1.3.5 创建MySQL hive用户
master@VM-0-12-ubuntu:/opt$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.0.28-0ubuntu0.20.04.3 (Ubuntu)
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create user 'datawhale'@'localhost' identified by '123456'; -- 创建用户
Query OK, 0 rows affected (0.02 sec)
mysql> grant all on *.* to 'datawhale'@'localhost'; -- 将所有数据库的所有表的所有权限赋给datawhale
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges; -- 刷新mysql系统权限关系表
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
master@VM-0-12-ubuntu:/opt$
4.1.3.6 下载安装MySQL JDBC
master@VM-0-12-ubuntu:/opt/JuciyBigData$ ls
apache-hive-2.3.9-bin.tar.gz hbase-2.4.8-bin.tar.gz mysql-connector-java_8.0.27-1ubuntu20.04_all.deb
hadoop-3.3.1.tar.gz jdk-8u311-linux-x64.tar.gz spark-3.2.0-bin-without-hadoop.tgz
master@VM-0-12-ubuntu:/opt/JuciyBigData$ sudo dpkg -i mysql-connector-java_8.0.27-1ubuntu20.04_all.deb
Selecting previously unselected package mysql-connector-java.
(Reading database ... 150463 files and directories currently installed.)
Preparing to unpack mysql-connector-java_8.0.27-1ubuntu20.04_all.deb ...
Unpacking mysql-connector-java (8.0.27-1ubuntu20.04) ...
Setting up mysql-connector-java (8.0.27-1ubuntu20.04) ...
master@VM-0-12-ubuntu:/opt/JuciyBigData$
4.1.3.7 导入MySQL JDBC jar包到hive/lib目录下
master@VM-0-12-ubuntu:/opt/JuciyBigData$ sudo cp /usr/share/java/mysql-connector-java-8.0.27.jar /opt/hive/lib/
master@VM-0-12-ubuntu:/opt$ sudo chown master:master /opt/hive/lib/mysql-connector-java-8.0.27.jar
master@VM-0-12-ubuntu:/opt$
注意:
你可能不知道安装到哪里了,别急,在/usr/share/java/下面,会存在该jar包。
验证路径的方法:打开deb文件,提取文件,看到.tar.xz文件,使用xz -d命令解压,并使用tar -xvf解包,解压出来的文件目录路径就是在系统中的路径。
4.1.3.8 修改hive配置文件
master@VM-0-12-ubuntu:/opt$ cd /opt/hive/conf
master@VM-0-12-ubuntu:/opt/hive/conf$ sudo mv hive-default.xml.template hive-default.xml
master@VM-0-12-ubuntu:/opt/hive/conf$ sudo touch hive-site.xml
master@VM-0-12-ubuntu:/opt/hive/conf$ sudo vim hive-site.xml
master@VM-0-12-ubuntu:/opt/hive/conf$ sudo cat hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_metadata?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC Metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC Metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>datawhale</value>
<description>username to use against Metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against Metastore database</description>
</property>
</configuration>
master@VM-0-12-ubuntu:/opt/hive/conf$
4.1.3.9 启动MySQL
状态正常,不用启动
master@VM-0-12-ubuntu:/opt/hive/conf$ systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-03-21 19:55:54 CST; 19min ago
Main PID: 663796 (mysqld)
Status: "Server is operational"
Tasks: 38 (limit: 2265)
Memory: 363.9M
CGroup: /system.slice/mysql.service
└─663796 /usr/sbin/mysqld
master@VM-0-12-ubuntu:/opt/hive/conf$
4.1.3.10 指定元数据数据库类型并初始化Schema
master@VM-0-12-ubuntu:/opt/hive/conf$ schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://localhost:3306/hive_metadata?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: datawhale
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
master@VM-0-12-ubuntu:/opt/hive/conf$
唔,直接成功了,看到SLF4J我当时就被吓住了,还好没事
教程中说如果找不到schematool就source /etc/profile更新一下系统变量
4.1.3.11 启动Hadoop
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ./start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as master in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [VM-0-12-ubuntu]
Starting resourcemanager
Starting nodemanagers
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
668027 DataNode
668232 SecondaryNameNode
669273 Jps
667870 NameNode
668527 ResourceManager
668690 NodeManager
master@VM-0-12-ubuntu:/opt/hadoop/sbin$
4.1.3.12 启动Hive
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/hive/lib/hive-common-2.3.9.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
4.1.3.13 检验Hive是否成功部署
hive> show databases;
OK
default
Time taken: 7.602 seconds, Fetched: 1 row(s)
hive>
4.2 实验二:Hive常用的DDL操作
4.2.1 实验准备
Ubuntu 20.04,Java,Hadoop,MySQL,Hive
4.2.2 实验内容
基于上述实验环境, 在hive shell命令行下,完成一些常见的DDL操作。
4.2.3 实验步骤
4.2.3.1 数据库操作
4.2.3.1.1 查看数据库
hive> show databases;
OK
default
Time taken: 7.602 seconds, Fetched: 1 row(s)
hive>
4.2.3.1.2 使用数据库
末尾记得加;
hive> use hive_test;
OK
Time taken: 0.118 seconds
hive>
4.2.3.1.3 新建数据库
命令格式如下:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name -- DATABASE|SCHEMA 是等价的
[COMMENT database_comment] -- 数据库注释
[LOCATION hdfs_path] -- 存储在HDFS上的位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; -- 指定额外属性
实践如下:
hive> CREATE DATABASE IF NOT EXISTS hive_test
> COMMENT 'hive database for test'
> WITH DBPROPERTIES ('create'='datawhale');
OK
Time taken: 0.447 seconds
hive>
4.2.3.1.4 查看数据库信息
命令格式如下:
DESC DATABASE [EXTENDED] db_name; -- EXTENDED 表示是否显示额外属性
实践如下:
hive> DESC DATABASE EXTENDED hive_test;
OK
hive_test hive database for test hdfs://localhost:9000/user/hive/warehouse/hive_test.db master USER {create=datawhale}
Time taken: 0.051 seconds, Fetched: 1 row(s)
hive>
4.2.3.1.5 删除数据库
格式如下:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
默认行为是RESTRICT,如果数据库中存在该表,则删除失败。要想删除库及其中的表,可以使用CASCADE级联删除。
实践如下:
hive> DROP DATABASE IF EXISTS hive_test CASCADE;
OK
Time taken: 0.452 seconds
hive>
4.2.3.2 创建表
4.2.3.2.1 建表语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- 表名
[(col_name data_type [COMMENT col_comment],
... [constraint_specification])] -- 列名 列数据类型
[COMMENT table_comment] -- 表描述
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] -- 分区表分区规则
[
CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS
] -- 分桶表分桶规则
[SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
] -- 指定倾斜列和值
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
] -- 指定行分隔符、存储文件格式或采用自定义存储格式
[LOCATION hdfs_path] -- 指定表的存储位置
[TBLPROPERTIES (property_name=property_value, ...)] -- 指定表的属性
[AS select_statement]; -- 从查询结果创建表
4.2.3.2.2 内部表
| 字段名称 | 字段类型 | 说明 |
|---|---|---|
| empno | INT | 员工编号 |
| ename | STRING | 员工姓名 |
| job | STRING | 员工工作 |
| mgr | INT | 领导编号 |
| hiredate | TIMESTAMP | 入职日期 |
| sal | DECIMAL(7,2) | 月薪 |
| comm | DECIMAL(7,2) | 奖金 |
| deptno | INT | 部门编号 |
命令格式如下:
CREATE TABLE emp(
empno INT,
empname STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
实践如下:
hive> CREATE TABLE emp(
> empno INT,
> empname STRING,
> job STRING,
> mgr INT,
> hiredate TIMESTAMP,
> sal DECIMAL(7,2),
> comm DECIMAL(7,2),
> deptno INT)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
OK
Time taken: 0.873 seconds
hive>
文件位置:
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /
hadoop: command not found
master@VM-0-12-ubuntu:/opt$ source /etc/profile
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /
Found 3 items
drwxr-xr-x - master supergroup 0 2022-03-19 20:49 /hbase
drwx-wx-wx - master supergroup 0 2022-03-21 20:21 /tmp
drwxr-xr-x - master supergroup 0 2022-03-21 20:26 /user
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /user
Found 1 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:26 /user/hive
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /user/hive
Found 1 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:34 /user/hive/warehouse
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:34 /user/hive/warehouse/hive_test.db
master@VM-0-12-ubuntu:/opt$
神奇啊,这直接就是个.db,教程当中给的好像还是个文件夹来着
4.2.3.2.3 外部表
命令:
CREATE EXTERNAL TABLE emp_external(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/datawhale/emp_external';
创建并查看:
hive> CREATE EXTERNAL TABLE emp_external(
> empno INT,
> ename STRING,
> job STRING,
> mgr INT,
> hiredate TIMESTAMP,
> sal DECIMAL(7,2),
> comm DECIMAL(7,2),
> deptno INT)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
> LOCATION '/datawhale/emp_external';
OK
Time taken: 0.227 seconds
hive> desc emp_external
> ;
OK
empno int
ename string
job string
mgr int
hiredate timestamp
sal decimal(7,2)
comm decimal(7,2)
deptno int
Time taken: 0.172 seconds, Fetched: 8 row(s)
hive>
找一找存储位置:
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /
Found 4 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:39 /datawhale
drwxr-xr-x - master supergroup 0 2022-03-19 20:49 /hbase
drwx-wx-wx - master supergroup 0 2022-03-21 20:21 /tmp
drwxr-xr-x - master supergroup 0 2022-03-21 20:26 /user
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /datawhale
Found 1 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:39 /datawhale/emp_external
master@VM-0-12-ubuntu:/opt$
嘛,这个正常了一点,和教程的一样,都是文件夹
4.2.3.2.4 分区表
命令:
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/datawhale/emp_partition';
建表:
hive> CREATE EXTERNAL TABLE emp_partition(
> empno INT,
> ename STRING,
> job STRING,
> mgr INT,
> hiredate TIMESTAMP,
> sal DECIMAL(7,2),
> comm DECIMAL(7,2)
> )
> PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
> LOCATION '/datawhale/emp_partition';
OK
Time taken: 0.206 seconds
hive>
找位置:
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /
Found 4 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:41 /datawhale
drwxr-xr-x - master supergroup 0 2022-03-19 20:49 /hbase
drwx-wx-wx - master supergroup 0 2022-03-21 20:21 /tmp
drwxr-xr-x - master supergroup 0 2022-03-21 20:26 /user
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /datawhale
Found 2 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:39 /datawhale/emp_external
drwxr-xr-x - master supergroup 0 2022-03-21 20:41 /datawhale/emp_partition
master@VM-0-12-ubuntu:/opt$
4.2.3.2.5 分桶表
命令:
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS -- 按照员工编号散列到四个 bucket 中
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/datawhale/emp_bucket';
建表:
hive> CREATE EXTERNAL TABLE emp_bucket(
> empno INT,
> ename STRING,
> job STRING,
> mgr INT,
> hiredate TIMESTAMP,
> sal DECIMAL(7,2),
> comm DECIMAL(7,2),
> deptno INT)
> CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS -- 按照员工编号散列到四个 bucket 中
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
> LOCATION '/datawhale/emp_bucket';
OK
Time taken: 0.181 seconds
hive>
找位置:
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /datawhale
Found 3 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:42 /datawhale/emp_bucket
drwxr-xr-x - master supergroup 0 2022-03-21 20:39 /datawhale/emp_external
drwxr-xr-x - master supergroup 0 2022-03-21 20:41 /datawhale/emp_partition
master@VM-0-12-ubuntu:/opt$
4.2.3.2.6 倾斜表
通过指定一个或者多个列经常出现的值(严重偏斜)
Hive会自动将涉及到这些值的数据拆分为单独的文件
在查询时,如果涉及到倾斜值,它就直接从独立文件中获取数据
而不是扫描所有文件,这使得查询性能得到提升
命令:
CREATE EXTERNAL TABLE emp_skewed(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
SKEWED BY (empno) ON (66,88,100) -- 指定 empno 的倾斜值 66,88,100
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/datawhale/emp_skewed';
建表:
hive> CREATE EXTERNAL TABLE emp_skewed(
> empno INT,
> ename STRING,
> job STRING,
> mgr INT,
> hiredate TIMESTAMP,
> sal DECIMAL(7,2),
> comm DECIMAL(7,2)
> )
> SKEWED BY (empno) ON (66,88,100) -- 指定 empno 的倾斜值 66,88,100
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
> LOCATION '/datawhale/emp_skewed';
OK
Time taken: 0.202 seconds
hive>
找位置:
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /datawhale
Found 4 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:42 /datawhale/emp_bucket
drwxr-xr-x - master supergroup 0 2022-03-21 20:39 /datawhale/emp_external
drwxr-xr-x - master supergroup 0 2022-03-21 20:41 /datawhale/emp_partition
drwxr-xr-x - master supergroup 0 2022-03-21 20:46 /datawhale/emp_skewed
master@VM-0-12-ubuntu:/opt$
4.2.3.2.7 临时表
临时表仅对当前session可见,临时表的数据将存储在用户的暂存目录中,并在会话结束后删除
如果临时表与永久表表名相同,则对该表名的任何引用都将解析为临时表,而不是永久表
临时表还具有以下两个限制,即不支持分区列,且不支持创建索引
命令:
CREATE TEMPORARY TABLE emp_temp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
实践:
hive> CREATE TEMPORARY TABLE emp_temp(
> empno INT,
> ename STRING,
> job STRING,
> mgr INT,
> hiredate TIMESTAMP,
> sal DECIMAL(7,2),
> comm DECIMAL(7,2)
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
OK
Time taken: 0.073 seconds
hive>
4.2.3.2.8 CTAS创建表
命令:
CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20';
实践:
hive> CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20';
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = master_20220321205127_728bfccd-3e1d-4580-872a-99a2422f4b7f
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1647865159127_0004, Tracking URL = http://localhost.localdomain:8088/proxy/application_1647865159127_0004/
Kill Command = /opt/hadoop/bin/hadoop job -kill job_1647865159127_0004
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2022-03-21 20:51:49,535 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1647865159127_0004
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://localhost:9000/user/hive/warehouse/hive_test.db/.hive-staging_hive_2022-03-21_20-51-27_145_2011158569485848367-1/-ext-10002
Moving data to directory hdfs://localhost:9000/user/hive/warehouse/hive_test.db/emp_copy
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 25.59 seconds
hive>
查看:
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
emp_temp
Time taken: 0.07 seconds, Fetched: 7 row(s)
hive>
找位置:
master@VM-0-12-ubuntu:/opt$ hadoop fs -ls /user/hive/warehouse/hive_test.db
Found 2 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:34 /user/hive/warehouse/hive_test.db/emp
drwxr-xr-x - master supergroup 0 2022-03-21 20:51 /user/hive/warehouse/hive_test.db/emp_copy
master@VM-0-12-ubuntu:/opt$
啊,之前没注意,虽然是.db,但是是一个文件夹啊
4.2.3.2.9 复制表结构
命令格式:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- 创建表表名
LIKE existing_table_or_view_name -- 被复制表的表名
[LOCATION hdfs_path]; -- 存储位置
命令:
CREATE TEMPORARY EXTERNAL TABLE IF NOT EXISTS emp_co LIKE emp
实践:
hive> CREATE TEMPORARY EXTERNAL TABLE IF NOT EXISTS emp_co LIKE emp
> ;
OK
Time taken: 0.181 seconds
hive>
4.2.3.2.10 加载数据到表
Data Manipulation Language是对对数据库中的数据进行一些简单操作
而Data Definition Language是对数据库中的某些对象进行管理2
这个命令是属于DML操作,下面是加载本地数据到表:
-- 加载数据到 emp 表中
load data local inpath "/opt/master/emp.txt" into table emp;
我把这个文件放在了/opt/master/目录下面,名为emp.txt,内容如下:
7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20
7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 20
7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 30
7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 10
7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 20
7839 KING PRESIDENT 1981-11-17 00:00:00 5000.00 10
7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 20
7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 30
7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 20
7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 10
实践如下:
hive> load data local inpath "/opt/master/emp.txt" into table emp;
Loading data to table hive_test.emp
OK
Time taken: 0.695 seconds
hive> select * from emp;
OK
NULL CLERK 7902 NULL NULL NULL 20.00 NULL
7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 NULL 20
7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 NULL 30
7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 NULL 10
7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 00:00:00 5000.00 NULL 10
7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 NULL 20
7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 NULL 30
7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 NULL 20
7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 NULL 10
Time taken: 0.325 seconds, Fetched: 14 row(s)
hive>
呜哇,教程这里给的东西有问题啊,直接复制载入进去全是NULL,不过文件里面是对的
然后查了博客3得知是分隔符不对,我上面展示的已经改用文件的了,可以直接复制
唔,教程这里还给了一个用分区表加载的例子:
命令:
load data local inpath "/opt/master/emp.txt" into table emp_partition partition(deptno=30);
实践:
hive> load data local inpath "/opt/master/emp.txt" into table emp_partition partition(deptno=30);
Loading data to table hive_test.emp_partition partition (deptno=30)
OK
Time taken: 1.042 seconds
hive> select * from emp_partition;
OK
NULL CLERK 7902 NULL NULL NULL 20.00 30
7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 NULL 30
7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 NULL 30
7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 NULL 30
7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 NULL 30
7839 KING PRESIDENT NULL 1981-11-17 00:00:00 5000.00 NULL 30
7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 NULL 30
7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 NULL 30
7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 NULL 30
7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 NULL 30
Time taken: 0.355 seconds, Fetched: 14 row(s)
hive>
找位置:
master@VM-0-12-ubuntu:/opt/master$ hadoop fs -ls /datawhale
Found 4 items
drwxr-xr-x - master supergroup 0 2022-03-21 20:42 /datawhale/emp_bucket
drwxr-xr-x - master supergroup 0 2022-03-21 20:39 /datawhale/emp_external
drwxr-xr-x - master supergroup 0 2022-03-21 21:14 /datawhale/emp_partition
drwxr-xr-x - master supergroup 0 2022-03-21 20:46 /datawhale/emp_skewed
master@VM-0-12-ubuntu:/opt/master$ hadoop fs -ls /datawhale/emp_partition
Found 1 items
drwxr-xr-x - master supergroup 0 2022-03-21 21:14 /datawhale/emp_partition/deptno=30
master@VM-0-12-ubuntu:/opt/master$
4.2.3.3 修改表
4.2.3.3.1 重命名表
格式如下:
ALTER TABLE table_name RENAME TO new_table_name;
命令如下:
ALTER TABLE emp_temp RENAME TO new_emp;
实践如下:
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
emp_temp
Time taken: 0.057 seconds, Fetched: 7 row(s)
hive> ALTER TABLE emp_temp RENAME TO new_emp;
OK
Time taken: 0.038 seconds
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
new_emp
Time taken: 0.052 seconds, Fetched: 7 row(s)
hive>
4.2.3.3.2 修改列
格式如下:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type
[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
命令如下:
-- 修改字段名和类型
ALTER TABLE new_emp CHANGE empno empno_new INT;
-- 修改字段 sal 的名称 并将其放置到 empno 字段后
ALTER TABLE new_emp CHANGE sal sal_new decimal(7,2) AFTER ename;
-- 为字段增加注释
ALTER TABLE new_emp CHANGE mgr mgr_new INT COMMENT 'this is column mgr';
实践如下:
hive> desc new_emp
> ;
OK
empno int
ename string
job string
mgr int
hiredate timestamp
sal decimal(7,2)
comm decimal(7,2)
Time taken: 0.028 seconds, Fetched: 7 row(s)
hive> ALTER TABLE new_emp CHANGE empno empno_new INT;
OK
Time taken: 0.042 seconds
hive> desc new_emp;
OK
empno_new int
ename string
job string
mgr int
hiredate timestamp
sal decimal(7,2)
comm decimal(7,2)
Time taken: 0.032 seconds, Fetched: 7 row(s)
hive> ALTER TABLE new_emp CHANGE sal sal_new decimal(7,2) AFTER ename;
OK
Time taken: 0.05 seconds
hive> desc new_emp;
OK
empno_new int
ename string
sal_new decimal(7,2)
job string
mgr int
hiredate timestamp
comm decimal(7,2)
Time taken: 0.031 seconds, Fetched: 7 row(s)
hive> ALTER TABLE new_emp CHANGE mgr mgr_new INT COMMENT 'this is column mgr';
OK
Time taken: 0.033 seconds
hive> desc new_emp;
OK
empno_new int
ename string
sal_new decimal(7,2)
job string
mgr_new int this is column mgr
hiredate timestamp
comm decimal(7,2)
Time taken: 0.035 seconds, Fetched: 7 row(s)
hive>
4.2.3.3.3 新增列
命令如下:
ALTER TABLE new_emp ADD COLUMNS (address STRING COMMENT 'home address');
实践如下:
hive> desc new_emp;
OK
empno_new int
ename string
sal_new decimal(7,2)
job string
mgr_new int this is column mgr
hiredate timestamp
comm decimal(7,2)
Time taken: 0.035 seconds, Fetched: 7 row(s)
hive> ALTER TABLE new_emp ADD COLUMNS (address STRING COMMENT 'home address');
OK
Time taken: 0.031 seconds
hive> desc new_emp;
OK
empno_new int
ename string
sal_new decimal(7,2)
job string
mgr_new int this is column mgr
hiredate timestamp
comm decimal(7,2)
address string home address
Time taken: 0.035 seconds, Fetched: 8 row(s)
hive>
4.2.3.4 清空表/删除表
4.2.3.4.1 清空表
格式如下:
-- 清空整个表或表指定分区中的数据
TRUNCATE TABLE table_name [PARTITION (partition_column = partition_col_value, ...)];
注意:
目前只有内部表才能执行TRUNCATE操作,外部表执行时会抛出异常Cannot truncate non-managed table。
命令如下:
TRUNCATE TABLE emp_partition PARTITION (deptno=30);
实践如下:
hive> desc emp_partition;
OK
empno int
ename string
job string
mgr int
hiredate timestamp
sal decimal(7,2)
comm decimal(7,2)
deptno int
# Partition Information
# col_name data_type comment
deptno int
Time taken: 0.209 seconds, Fetched: 13 row(s)
hive> TRUNCATE TABLE emp_partition PARTITION (deptno=30);
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table emp_partition.
hive>
嗯,这是个外部表
4.2.3.4.2 删除表
格式如下:
DROP TABLE [IF EXISTS] table_name [PURGE];
实践如下:
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
new_emp
Time taken: 0.057 seconds, Fetched: 7 row(s)
hive> DROP TABLE new_emp;
OK
Time taken: 0.048 seconds
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
Time taken: 0.052 seconds, Fetched: 6 row(s)
hive>
删除不同的表,其效果也不同:
内部表:
不仅会删除表的元数据,同时会删除HDFS上的数据
外部表:
只会删除表的元数据,不会删除HDFS上的数据
删除视图引用的表
不会给出警告,但视图已经无效了,必须由用户删除或重新创建
4.2.3.5 其他命令
4.2.3.5.1 查看数据库
格式如下:
DESCRIBE|Desc DATABASE [EXTENDED] db_name; -- EXTENDED 是否显示额外属性
实践如下:
hive> Desc DATABASE extended hive_test;
OK
hive_test hive database for test hdfs://localhost:9000/user/hive/warehouse/hive_test.db master USER {create=datawhale}
Time taken: 0.051 seconds, Fetched: 1 row(s)
hive>
4.2.3.5.2 查看表
格式如下:
DESCRIBE|Desc [EXTENDED|FORMATTED] table_name -- FORMATTED 以友好的展现方式查看表详情
实践如下:
hive> desc formatted emp;
OK
# col_name data_type comment
empno int
empname string
job string
mgr int
hiredate timestamp
sal decimal(7,2)
comm decimal(7,2)
deptno int
# Detailed Table Information
Database: hive_test
Owner: master
CreateTime: Mon Mar 21 20:34:26 CST 2022
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://localhost:9000/user/hive/warehouse/hive_test.db/emp
Table Type: MANAGED_TABLE
Table Parameters:
numFiles 1
numRows 0
rawDataSize 0
totalSize 793
transient_lastDdlTime 1647868241
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.132 seconds, Fetched: 37 row(s)
hive>
4.2.3.5.3 查看数据库列表
格式:
-- 语法
SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards'];
实践:
hive> SHOW DATABASES;
OK
default
hive_test
Time taken: 0.029 seconds, Fetched: 2 row(s)
hive> SHOW DATABASES like 'hive*';
OK
hive_test
Time taken: 0.037 seconds, Fetched: 1 row(s)
hive>
LIKE子句允许使用正则表达式进行过滤
但是SHOW语句当中的LIKE子句只支持 *(通配符)和 |(条件或)两个符号
例如 employees,emp *,emp * | * ees
所有这些都将匹配名为employees的数据库
4.2.3.5.4 查看表的列表
格式:
-- 语法
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
实践:
hive> show databases;
OK
default
hive_test
Time taken: 0.036 seconds, Fetched: 2 row(s)
hive> SHOW TABLES IN 'hive_test';
NoViableAltException(352@[])
at org.apache.hadoop.hive.ql.parse.HiveParser_IdentifiersParser.identifier(HiveParser_IdentifiersParser.java:11072)
at org.apache.hadoop.hive.ql.parse.HiveParser.identifier(HiveParser.java:41976)
at org.apache.hadoop.hive.ql.parse.HiveParser.showStatement(HiveParser.java:17204)
at org.apache.hadoop.hive.ql.parse.HiveParser.ddlStatement(HiveParser.java:3878)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:2382)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1333)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:208)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:77)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:70)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:468)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1317)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1457)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
FAILED: ParseException line 1:15 cannot recognize input near ''hive_test'' '<EOF>' '<EOF>' in show statement
hive>
搞锤子,这个命令不对吧,我感觉有问题啊,我的操作一般是:
hive> show databases;
OK
default
hive_test
Time taken: 0.033 seconds, Fetched: 2 row(s)
hive> use hive_test;
OK
Time taken: 0.045 seconds
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
Time taken: 0.032 seconds, Fetched: 6 row(s)
hive>
4.2.3.5.5 查看视图列表
格式:
SHOW VIEWS [IN/FROM database_name] [LIKE 'pattern_with_wildcards']; -- 仅支持 Hive 2.2.0 +
实践:
hive> show databases;
OK
default
hive_test
Time taken: 0.021 seconds, Fetched: 2 row(s)
hive> use hive_test;
OK
Time taken: 0.037 seconds
hive> SHOW VIEWS
> ;
OK
Time taken: 0.043 seconds
hive>
4.2.3.5.6 查看表的分区列表
格式:
SHOW PARTITIONS table_name;
实践:
hive> use hive_test;
OK
Time taken: 0.031 seconds
hive> show tables
> ;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
Time taken: 0.042 seconds, Fetched: 6 row(s)
hive> SHOW PARTITIONS emp;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Table emp is not a partitioned table
hive> SHOW PARTITIONS emp_partition;
OK
deptno=30
Time taken: 0.16 seconds, Fetched: 1 row(s)
hive>
4.2.3.5.7 查看表/视图的创建语句
格式:
SHOW CREATE TABLE ([db_name.]table_name|view_name);
实践:
hive> show tables;
OK
emp
emp_bucket
emp_copy
emp_external
emp_partition
emp_skewed
Time taken: 0.033 seconds, Fetched: 6 row(s)
hive> SHOW CREATE TABLE emp
> ;
OK
CREATE TABLE `emp`(
`empno` int,
`empname` string,
`job` string,
`mgr` int,
`hiredate` timestamp,
`sal` decimal(7,2),
`comm` decimal(7,2),
`deptno` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'serialization.format'='\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://localhost:9000/user/hive/warehouse/hive_test.db/emp'
TBLPROPERTIES (
'transient_lastDdlTime'='1647868241')
Time taken: 0.181 seconds, Fetched: 22 row(s)
hive> SHOW CREATE TABLE datawhale;
FAILED: SemanticException [Error 10001]: Table not found datawhale
hive>
啊,只能看已经有的表的创建语句
最后!最后!最后!记得关环境
依次退出hive,关hadoop,再关mysql
hive> exit
> ;
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ps -ef|grep hive
master 686663 662210 0 22:00 pts/0 00:00:00 grep --color=auto hive
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ./stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as master in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [VM-0-12-ubuntu]
Stopping nodemanagers
localhost: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
Stopping resourcemanager
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
668690 -- process information unavailable
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ./stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as master in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [VM-0-12-ubuntu]
Stopping nodemanagers
Stopping resourcemanager
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
668690 -- process information unavailable
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ls /tmp/hsperfdata_master/
668690
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ ps | grep 668690
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ sudo rm -rf /tmp/hsperfdata_master/
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ jps
689346 Jps
master@VM-0-12-ubuntu:/opt/hadoop/sbin$
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-03-21 19:55:54 CST; 2h 12min ago
Main PID: 663796 (mysqld)
Status: "Server is operational"
Tasks: 43 (limit: 2265)
Memory: 396.7M
CGroup: /system.slice/mysql.service
└─663796 /usr/sbin/mysqld
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ sudo service mysql stop
master@VM-0-12-ubuntu:/opt/hadoop/sbin$ systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Mon 2022-03-21 22:08:47 CST; 1s ago
Process: 663796 ExecStart=/usr/sbin/mysqld (code=exited, status=0/SUCCESS)
Main PID: 663796 (code=exited, status=0/SUCCESS)
Status: "Server shutdown complete"
master@VM-0-12-ubuntu:/opt/hadoop/sbin$
挺神奇,jps又出错了,得删掉对应的文件夹4