爬虫入门,萌新报道
第一篇独立完成的爬虫,网址目前未见其他人爬过
入门作品代码略显冗余,欢迎大家批评指正!!
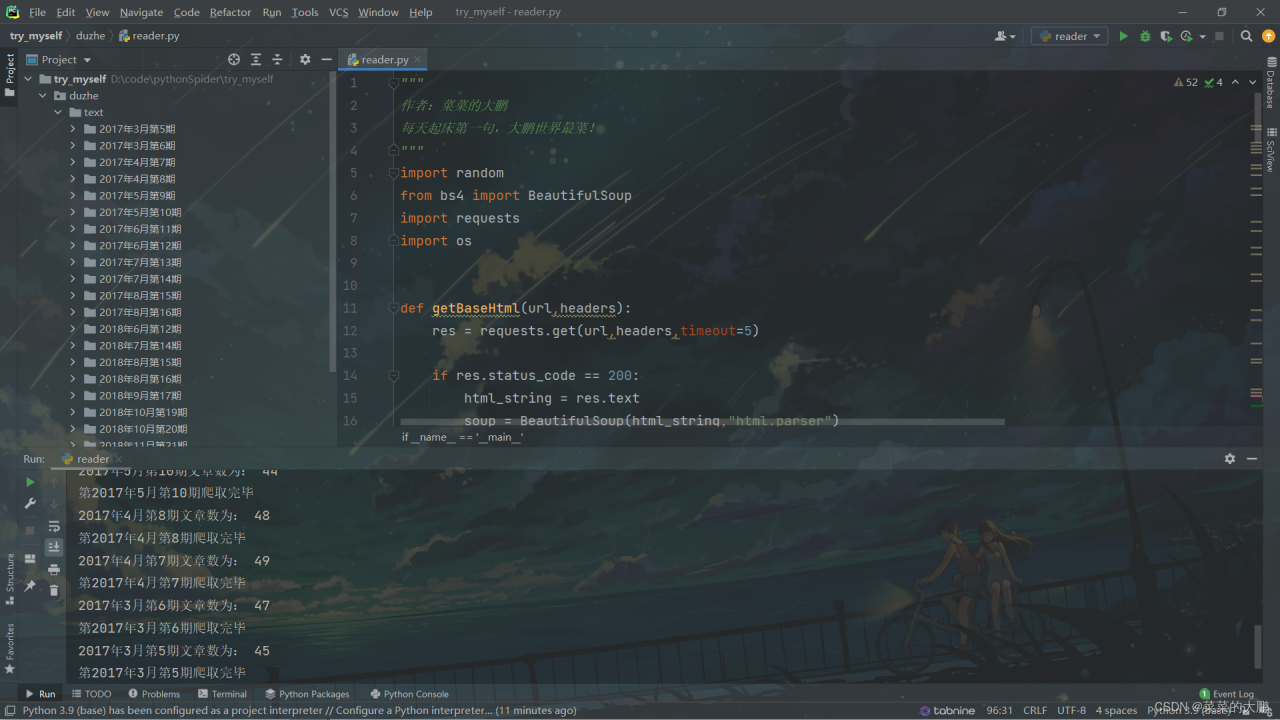
源码
"""
作者:菜菜的大鹏
每天起床第一句,大鹏世界最菜!
"""
import random
from bs4 import BeautifulSoup
import requests
import os
def getBaseHtml(url,headers):
res = requests.get(url,headers,timeout=5)
if res.status_code == 200:
html_string = res.text
soup = BeautifulSoup(html_string,"html.parser")
books = soup.findAll(attrs={'class':'zp-book-item'})
print("现有总期数为:",len(books))
detailUrls=[]
for item in books:
href = item.a['href']
dateName = item.h2.string
detailUrls.append(zip({href:f"{href}",dateName:f"{dateName}"}))
getDetailUrl(href,dateName)
def getDetailUrl(url,dateName):
ua = random.choice(uas)
headers = {
'User-Agent': ua,
}
res = requests.get(url, headers, timeout=5)
if res.status_code == 200:
html_string = res.text
soup = BeautifulSoup(html_string, "html.parser")
books = soup.find_all('ul',attrs={'class':None})
booklist = books[0].find_all('li')
print(dateName+"文章数为:", len(booklist))
textUrls=[]
for item in booklist:
href = item.a['href']
title = item.a['title']
textUrls.append(zip({href:f"{href}",title:f"{title}"}))
getText(href,dateName,title)
print("第" + dateName + "爬取完毕")
def getText(url,dateName,title):
ua = random.choice(uas)
headers = {
'User-Agent': ua,
}
res = requests.get(url, headers, timeout=5)
if res.status_code == 200:
html_string = res.text
soup = BeautifulSoup(html_string, "html.parser")
text = soup.find(attrs={'class': 'contentbox'})
saveText(text,dateName,title)
def saveText(text,dateName,title):
if text is not None:
messages = text.find_all('p')
path = 'text/{}'.format(dateName)
folder = os.path.exists(path)
if not folder:
os.makedirs(path)
with open("text/{}/{}.txt".format(dateName,title), "w+",encoding='utf-8') as f:
f.write(title+"\n")
for message in messages:
f.write(" "+message.text+'\n')
def LoadUserAgents(uafile):
uas = []
with open(uafile, 'rb') as uaf:
for ua in uaf.readlines():
if ua:
uas.append(ua.strip()[:-1])
random.shuffle(uas)
return uas
if __name__ == '__main__':
baseUrl = 'http://duzhe.1she.com/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'}
uas = LoadUserAgents("user_agents.txt")
getBaseHtml(baseUrl,headers)
版权声明:本文为weixin_52144018原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。