文章目录
- MP 配置
- Service CURD接口
- Mapper CURD接口
- 条件构造器
- mapper 层 选装件
- #[AlwaysUpdateSomeColumnById(opens new window)](https://gitee.com/baomidou/mybatis-plus/blob/3.0/mybatis-plus-extension/src/main/java/com/baomidou/mybatisplus/extension/injector/methods/AlwaysUpdateSomeColumnById.java)
- #[insertBatchSomeColumn(opens new window)](https://gitee.com/baomidou/mybatis-plus/blob/3.0/mybatis-plus-extension/src/main/java/com/baomidou/mybatisplus/extension/injector/methods/InsertBatchSomeColumn.java)
- #[logicDeleteByIdWithFill(opens new window)](https://gitee.com/baomidou/mybatis-plus/blob/3.0/mybatis-plus-extension/src/main/java/com/baomidou/mybatisplus/extension/injector/methods/LogicDeleteByIdWithFill.java)
- 查询指定字段
- convert
- @Param
- javaAPI
- SQL语句构建器
- MP分页
- 分页联表查询
- MP注解
- MP注解
- `${ew.sqlSegment}` `${ew.sqlSelect}` `${ew.customSqlSegment}`
- 自定义排序
- 主键
- SqlInjector
- 插件
- 自动生成代码
- mybatisX
- mybatisCodeHelperPro
- toolkit
MP 配置
依赖
<!--springboot整合mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>
yml
# mybatis-plus的配置
mybatis-plus:
type-aliases-package: com.example.demo.entity # 配置包别名
mapper-locations: classpath:mappers/*.xml # 映射文件的位置
configuration:
map-underscore-to-camel-case: true # true自动开启驼峰规则映射
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # mybatis-plus 日志
Service CURD接口
public interface EmployeeService extends IService<Employee> {
}
@Service
public class EmployeeServiceImpl extends ServiceImpl<EmployeeMapper, Employee> implements EmployeeService {
}
事实上,我们只需让 EmployeeServiceImpl 继承 ServiceImpl 即可获得 Service 层的方法,那么为什么还需要实现 EmployeeService 接口呢?
这是因为实现 EmployeeService 接口能够更方便地对业务进行扩展,一些复杂场景下的数据处理,MyBatisPlus 提供的 Service 方法可能无法处理,此时我们就需要自己编写代码,这时候只需在 EmployeeService 中定义自己的方法,并在 EmployeeServiceImpl 中实现即可
IService中的方法具体参考官网即可
接下来模拟一个自定义的场景,我们来编写自定义的操作方法,首先在 EmployeeMapper 中进行声明:
public interface EmployeeMapper extends BaseMapper<Employee> {
List<Employee> selectAllByLastName(@Param("lastName") String lastName);
}
此时我们需要自己编写配置文件实现该方法,在 resource 目录下新建一个 mapper 文件夹,然后在该文件夹下创建 EmployeeMapper.xml 文件:
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.wwj.mybatisplusdemo.mapper.EmployeeMapper">
<sql id="Base_Column">
id, last_name, email, gender, age
</sql>
<select id="selectAllByLastName" resultType="com.wwj.mybatisplusdemo.bean.Employee">
select <include refid="Base_Column"/>
from tbl_employee
where last_name = #{lastName}
</select>
</mapper>
MyBatisPlus 默认扫描的是类路径下的 mapper 目录,这可以从源码中得到体现:
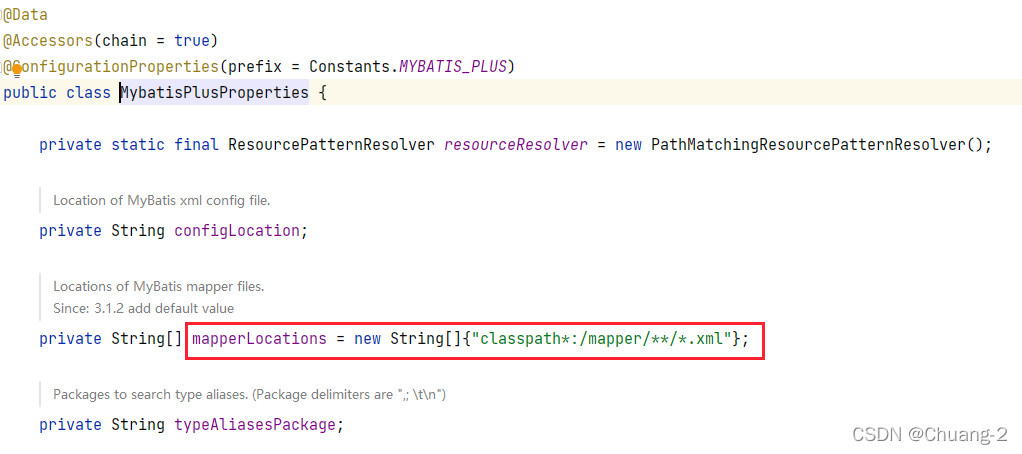
所以我们直接将 Mapper 配置文件放在该目录下就没有任何问题,可如果不是这个目录,我们就需要进行配置,比如:
mybatis-plus:
mapper-locations: classpath:xml/*.xml
编写好 Mapper 接口后,我们就需要定义 Service 方法了:
public interface EmployeeService extends IService<Employee> {
List<Employee> listAllByLastName(String lastName);
}
@Service
public class EmployeeServiceImpl extends ServiceImpl<EmployeeMapper, Employee> implements EmployeeService {
@Override
public List<Employee> listAllByLastName(String lastName) {
return baseMapper.selectAllByLastName(lastName);
}
}
在 EmployeeServiceImpl 中我们无需将 EmployeeMapper 注入进来,而是使用 BaseMapper,查看 ServiceImpl 的源码:
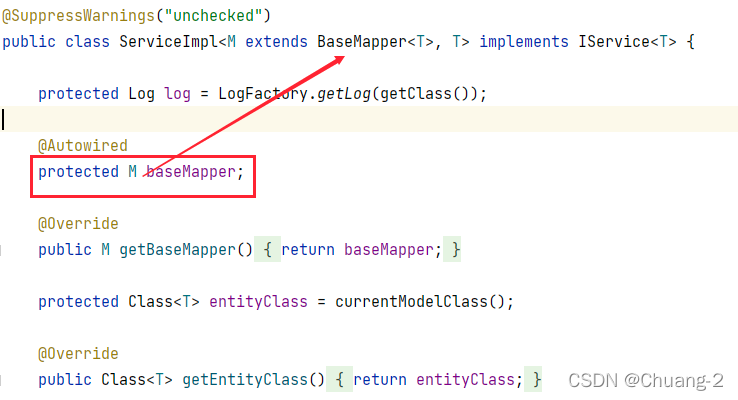
可以看到它为我们注入了一个 BaseMapper 对象,而它是第一个泛型类型,也就是 EmployeeMapper 类型,所以我们可以直接使用这个 baseMapper 来调用 Mapper 中的方法,此时编写测试代码:
@SpringBootTest
@MapperScan("com.wwj.mybatisplusdemo.mapper")
class MybatisplusDemoApplicationTests {
@Autowired
private EmployeeService employeeService;
@Test
void contextLoads() {
List<Employee> list = employeeService.listAllByLastName("tom");
list.forEach(System.out::println);
}
}
Mapper CURD接口
insert
// 插入一条记录
int insert(T entity);
delete
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
update
// 根据 whereWrapper 条件,更新记录
int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);
// 根据 ID 修改
int updateById(@Param(Constants.ENTITY) T entity);
select
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
条件构造器
LambdaUpdateWrapper
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda().set(User::getAge, 20)
.eq(User::getAge, 18);
Wrappers.<实体>lambdaUpdate()
注意
MP的update方法,如果字段为null,则不会被更新,需要再用set更新为null
userDTO是传参
this.aMapper.update(userDTO, Wrappers.<User>lambdaUpdate()
.set(Objects.isNull(userDTO.getName()), User::getName, null)
.eq(User::getPhone, userDTO.getPhone()));
只更新某个字段
userId是传参
return this.aMapper.update(null, Wrappers.<User>lambdaUpdate()
.set(User::getName, "lisi").eq(User::getUserId, userId));
更新比较多的,先删除后增加
queryWrapper
QueryWrapper<BannerItem> wrapper = new QueryWrapper<>();
wrapper.eq("banner_id", id);
List<BannerItem> bannerItems = bannerItemMapper.selectList(wrapper);
lambdaQueryWrapper
LambdaQueryWrapper<BannerItem> wrapper = new QueryWrapper<BannerItem>().lambda();
wrapper.eq(BannerItem::getBannerId, id);
List<BannerItem> bannerItems = bannerItemMapper.selectList(wrapper);
Wrappers.<实体>lambdaQuery()
@Override
public IPage<ElementVO> listPage(@NonNull ElementListPageDTO ElementListPageDTO, @NonNull Integer current, @NonNull Integer size) {
LambdaQueryWrapper<Element> wrappers = Wrappers.<Element>lambdaQuery()
.eq(StringUtils.isNotBlank(ElementListPageDTO.getElementCode()),
Element::getElementCode,
ElementListPageDTO.getElementCode())
.eq(StringUtils.isNotBlank(ElementListPageDTO.getElementName()),
Element::getElementName,
ElementListPageDTO.getElementName());
IPage<ElementVO> selectPage =
this.ElementMapper.selectPage(new Page<>(current, size), wrappers);
return selectPage;
}
AbstractWrapper
前面都是可以加条件的,条件为true时,才会执行
eq(boolean condition, R column, Object val)
AbstractWrapper
前面都是可以加条件的,条件为true时,才会执行
eq(boolean condition, R column, Object val)
- eq
- allEq
- ne
- gt
- ge
- lt
- le
- between,notBetween
- like,notLike,likeLeft(‘%王’),likeRight(‘王%’)
- isNull,isNotNull
- in,notIn in(“id”, new Object[]{1, 2}),in(“id”, list)
- inSql inSql(“age”, “1,2,3,4,5,6”)—> age in (1,2,3,4,5,6)
- notInSql notInSql(“age”, “1,2,3,4,5,6”)—> age not in (1,2,3,4,5,6)
- groupBy
- orderByAsc,orderByDesc
- orderBy
- having having(“sum(age) > {0}”, 11) -> having sum(age) > 11
- or or(i -> i.eq(“name”, “李白”).ne(“status”, “活着”))
--->or (name = ‘李白’ and status <> ‘活着’) - and and(i -> i.eq(“name”, “李白”).ne(“status”, “活着”))
--->and (name = ‘李白’ and status <> ‘活着’) - exists,notExists 例:
exists("select id from table")—>exists (select id from table) - func (if…else下调用不同方法能不断链) func(i -> if(true) {i.eq(“id”, 1)} else {i.ne(“id”, 1)})
- nested 正常嵌套 不带 AND或OR nested(i -> i.eq(“name”, “李白”).ne(“status”, “活着”))—> (name = ‘李白’ and status <> ‘活着’)
- apply 拼接sql
- last 就是limit查询
this.carouselMapper.selectList(Wrappers.<Carousel>lambdaQuery().eq(Carousel::getDeleted, 0).last("limit " + number));
allEq
params : key为数据库字段名,value为字段值
null2IsNull : 为true则在map的value为null时调用 isNull 方法,为false时则忽略value为null
例1: allEq({id:1,name:"老王",age:null})--->id = 1 and name = '老王' and age is null
例2: allEq({id:1,name:"老王",age:null}, false)--->id = 1 and name = '老王'
apply
拼接sql,该方法可用于数据库函数 动态入参的params对应前面applySql内部的{index}部分.这样是不会有sql注入风险的,反之会有!
// 注意limit后面是有空格的
int count = MapUtils.getIntValue(jobParam, "count", 30);
QueryWrapper<A> queryWrapper = Wrappers.<A>query().apply(total > 0,
MyBatisPlusUtils.column(EquipCheck::getBillId) + "%{0}={1}", total, index).last(" limit " + count);;
return this.listA(queryWrapper);
// 或者是
QueryWrapper<A> queryWrapper = Wrappers.<A>query().apply(total > 0,
"ec.bill_id" + "%{0}={1}", total, index).last(" limit " + count);;
return this.listA(queryWrapper);
mapper 层 选装件
说明:
选装件位于 com.baomidou.mybatisplus.extension.injector.methods 包下 需要配合Sql 注入器使用,案例(opens new window)
使用详细见源码注释(opens new window)
#AlwaysUpdateSomeColumnById(opens new window)
int alwaysUpdateSomeColumnById(T entity);
#insertBatchSomeColumn(opens new window)
int insertBatchSomeColumn(List<T> entityList);
#logicDeleteByIdWithFill(opens new window)
int logicDeleteByIdWithFill(T entity);
查询指定字段
LambdaQueryWrapper<Form> queryWrapper = Wrappers.<Form>lambdaQuery()
.select(Form::getCode, Form::getName)
.eq(StringUtils.isNotBlank(query.getCategory()), Form::getCategory, query.getCategory())
convert
// 源码:
/**
* IPage 的泛型转换
*
* @param mapper 转换函数
* @param <R> 转换后的泛型
* @return 转换泛型后的 IPage
*/
@SuppressWarnings("unchecked")
default <R> IPage<R> convert(Function<? super T, ? extends R> mapper) {
List<R> collect = this.getRecords().stream().map(mapper).collect(toList());
return ((IPage<R>) this).setRecords(collect);
}
// 例子
return this.formMapper.selectPage(new Page(pageNum, pageSize), queryWrapper).convert(o -> {
FormVO o1 = (FormVO)o;
o1.setLastUpdateByName("a");
return o1;
});
@Param
@Param("ew")
@Param(Constants.WRAPPER)
@Param("coll")
@Param(Constants.COLLECTION)
@Param("et")
@Param(Constants.ENTITY)
@Param("cm")
@Param(Constants.COLUMN_MAP)
javaAPI
参考:https://mybatis.org/mybatis-3/zh/java-api.html
注解实现CURD
@Select({"SELECT biz_tag, max_id, step, update_time FROM leaf_alloc"})
@Results({@Result(column = "biz_tag", property = "key"), @Result(column = "max_id", property = "maxId"),
@Result(column = "step", property = "step"), @Result(column = "update_time", property = "updateTime")})
List<LeafAlloc> getAllLeafAllocs();
@Select({"SELECT biz_tag, max_id, step FROM leaf_alloc WHERE biz_tag = #{tag}"})
@Results({@Result(column = "biz_tag", property = "key"), @Result(column = "max_id", property = "maxId"),
@Result(column = "step", property = "step")})
LeafAlloc getLeafAlloc(@Param("tag") String var1);
@Update({"UPDATE leaf_alloc SET max_id = max_id + step,update_time=#{updateTime} WHERE biz_tag = #{tag}"})
void updateMaxId(@Param("tag") String var1, @Param("updateTime") LocalDateTime var2);
@Update({"UPDATE leaf_alloc SET max_id = max_id + #{leafAlloc.step},update_time=#{updateTime} WHERE biz_tag = #{leafAlloc.key}"})
void updateMaxIdByCustomStep(@Param("leafAlloc") LeafAlloc var1, @Param("updateTime") LocalDateTime var2);
@Select({"SELECT biz_tag FROM leaf_alloc"})
List<String> getAllTags();
@Select({"${sql}"})
Long getFromDBSeq(@Param("sql") String var1);
SQL语句构建器
参考:https://mybatis.org/mybatis-3/zh/statement-builders.html
SqlBuilder 和 SelectBuilder (已经废弃)
问题
Java 程序员面对的最痛苦的事情之一就是在 Java 代码中嵌入 SQL 语句
这通常是因为需要动态生成 SQL 语句,不然我们可以将它们放到外部文件或者存储过程中。如你所见,MyBatis 在 XML 映射中具备强大的 SQL 动态生成能力。但有时,我们还是需要在 Java 代码里构建 SQL 语句
String sql = "SELECT P.ID, P.USERNAME, P.PASSWORD, P.FULL_NAME, "
"P.LAST_NAME,P.CREATED_ON, P.UPDATED_ON " +
"FROM PERSON P, ACCOUNT A " +
"INNER JOIN DEPARTMENT D on D.ID = P.DEPARTMENT_ID " +
"INNER JOIN COMPANY C on D.COMPANY_ID = C.ID " +
"WHERE (P.ID = A.ID AND P.FIRST_NAME like ?) " +
"OR (P.LAST_NAME like ?) " +
"GROUP BY P.ID " +
"HAVING (P.LAST_NAME like ?) " +
"OR (P.FIRST_NAME like ?) " +
"ORDER BY P.ID, P.FULL_NAME";
解决方案
借助 SQL 类
private String selectPersonSql() {
return new SQL() {{
SELECT("P.ID, P.USERNAME, P.PASSWORD, P.FULL_NAME");
SELECT("P.LAST_NAME, P.CREATED_ON, P.UPDATED_ON");
FROM("PERSON P");
FROM("ACCOUNT A");
INNER_JOIN("DEPARTMENT D on D.ID = P.DEPARTMENT_ID");
INNER_JOIN("COMPANY C on D.COMPANY_ID = C.ID");
WHERE("P.ID = A.ID");
WHERE("P.FIRST_NAME like ?");
OR();
WHERE("P.LAST_NAME like ?");
GROUP_BY("P.ID");
HAVING("P.LAST_NAME like ?");
OR();
HAVING("P.FIRST_NAME like ?");
ORDER_BY("P.ID");
ORDER_BY("P.FULL_NAME");
}}.toString();
}
这个例子有什么特别之处吗?仔细看一下你会发现,你不用担心可能会重复出现的 “AND” 关键字,或者要做出用 “WHERE” 拼接还是 “AND” 拼接还是不用拼接的选择。SQL 类已经为你处理了哪里应该插入 “WHERE”、哪里应该使用 “AND” 的问题,并帮你完成所有的字符串拼接工作。
MP分页
@Configuration
public class MPConfig {
/**
* 分页插件 MP 3.2之前
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
// MP 3.2之后
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.H2));
return interceptor;
}
}
IPage属性
record getRecords 查询出来的记录
total getTotal总条数
size getSize页的大小
current getCurrent当前页
pages getPages总页数
searchCount isSerachCount默认是true,是否返回符合查询条件的条数
分页联表查询
@GetMapping(value = "/list/{size}/{current}")
public ResponseMessage<IPage<VO>> list(@PathVariable @Min(1) Integer current,
@PathVariable @Range(min = 1, max = 100) Integer size) {
return ResponseMessage.success(this.sService.listPage(current, size));
}
service
IPage<VO> listPage(@NonNull Integer current, @NonNull Integer size);
serviceImpl
@Override
public IPage<VO> listPage(@NonNull Integer current, @NonNull Integer size) {
return this.sMapper.listPage(new Page<>(current, size));
}
mapper
IPage<VO> listPage(@Param("page") Page<VO> page);
mapper.xml
<select id="listPage" resultType="VO">
SELECT
pb.*, sb.*
FROM
b pb, s sb
WHERE
pb.id = sb.id
</select>
如果有其他条件,也可以在serviceImpl 中的 listPage(new Page<>(current, size), wrapper),加个wrapper条件**
limit
使用last
List<Carousel> carousels =
this.carouselMapper.selectList(Wrappers.<Carousel>lambdaQuery().eq(Carousel::getDeleted, 0).last(
"limit " + number));
MP注解
@TableId
MP注解
参考官网:https://baomidou.com/pages/223848/#tablename
@TableId
value = “id字段”, type = IdType.INPUT
IdType
| 值 | 描述 |
|---|---|
| AUTO | 数据库ID自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert前自行set主键值 |
| ASSIGN_ID | 分配ID(主键类型为Number(Long和Integer)或String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配UUID,主键类型为String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认default方法) |
分布式全局唯一ID 长整型类型(please use ASSIGN_ID) | |
32位UUID字符串(please use ASSIGN_UUID) | |
分布式全局唯一ID 字符串类型(please use ASSIGN_ID) |
@TableField
updateStrategy insertStrategy
前端传 ""或者null会更新,但是要注意更新的时候 如果不传该值,更新时数据又没了,比如只更新用户的昵称,但是此时没有传 用户本身的其他字段值,然后更新,带有策略(updateStrategy = FieldStrategy.IGNORED)的字段值又没了
@TableField(value = "login_name", updateStrategy = FieldStrategy.IGNORED)
private String loginName;
// 为null或者"" 也会更新, 插入时数据库不会有该值
@TableField(updateStrategy = FieldStrategy.IGNORED, insertStrategy = FieldStrategy.NEVER)
private String passwordMd5;
@GetMapping("/testStrategy")
@ResponseBody
public String testStrategy(@RequestBody User user) {
int insert = this.userMapper.insert(user);
// int update = this.userMapper.update(user, Wrappers.<User>lambdaUpdate().eq(User::getUserId, 13));
return "ok";
}
{
"nickName": "",
"loginName": "",
"passwordMd5": "a",
"deleted": 0,
"lockedFlag": 0,
"createTime": "2022-04-29 08:44:52",
"updateTime": "2022-04-29 08:44:52",
"avatar": ""
}
public enum FieldStrategy {
IGNORED, //忽略数值为null,但是有风险
NOT_NULL, //数值不能为null,“”
NOT_EMPTY,//为null,为空串的忽略,就是如果设置值为null,“”,不会插入数据库
DEFAULT,//默认,如果数值为null,就跳过该条数据
NEVER;//不保存该数据
private FieldStrategy() {
}
}
fill
| DEFAULT | 默认不处理 |
|---|---|
| INSERT | 插入时填充字段 |
| UPDATE | 更新时填充字段 |
| INSERT_UPDATE | 插入和更新时填充字段 |
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
private SexEnum sex;
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.UPDATE)
private LocalDateTime updateTime;
}
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.setFieldValByName("createTime", LocalDateTime.now(), metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updateTime", LocalDateTime.now(), metaObject);
}
}
@EnumValue
@KeySequence
序列主键策略
@InterceptorIgnore
具体参考 MP插件
${ew.sqlSegment} ${ew.sqlSelect} ${ew.customSqlSegment}
ew是mapper方法里的@Param(Constants.WRAPPER) Wrapper queryWrapper对象
首先判断ew.emptyOfWhere是否存在where条件,有的话再拼接上去,ew.customSqlSegment是WHERE + sql语句
没有where的时候加上 == false
最佳例子1
mapper.xml
<select id="tableList" resultType="java.util.LinkedHashMap">
SELECT
${ew.sqlSelect} // 这里拼接select后面的语句
FROM
${table_name} //如果是单表的话,这里可以写死
${ew.customSqlSegment}
</select>
mapper
IPage<LinkedHashMap<String,Object>> tableList(@Param("table_name") String table_name,
Page page,
@Param(Constants.WRAPPER) QueryWrapper queryWrapper);
test
String responseField = "*";
queryWrapper.select(responseField);
// 即 select * ...
String responseField = "name";
queryWrapper.select(responseField);
// 即 select name ...
最佳例子2
controller
public String saveAddress(HttpSession session) {
UserVO user1 = (UserVO)session.getAttribute("user");
LambdaQueryWrapper<User> lambdaQueryWrapper = Wrappers.<User>lambdaQuery()
.select(User::getNickName, User::getUserId) // 需要查询的列,即 ${ew.sqlSelect}
.eq(User::getUserId, user1.getUserId());// 条件
User user = this.userMapper.selectNickNameAndUserId(lambdaQueryWrapper);
System.out.println(user);
return null;
}
mapper
User selectNickNameAndUserId(@Param(Constants.WRAPPER) LambdaQueryWrapper<User> queryWrapper);
mapper.xml
<select id="selectNickNameAndUserId" resultType="com.example.demo.entity.User">
select
<if test="ew != null and ew.SqlSelect != null and ew.SqlSelect != ''">
${ew.SqlSelect}
</if>
from
user
where is_deleted != 1
<if test="ew != null">
<if test="ew.nonEmptyOfWhere">
AND
</if>
${ew.sqlSegment}
</if>
</select>
<select id="selectNickNameAndUserId" resultType="com.example.demo.entity.User">
select
<if test="ew != null and ew.SqlSelect != null and ew.SqlSelect != ''">
${ew.SqlSelect}
</if>
from
user
${ew.customSqlSegment}
</select>
使用${ew.sqlSegment} 如果是联表查询且查询条件是连表的字段则需在service层拼接查询条件时字段前指定别名,而且不能用lambda的查询了
<select id="selectByRoleId" resultType="com.captain.crewer.mybatis.plus.dto.RolePermsDTO">
SELECT tp.id,
tp.perm_name,
tp.url,
tr.role_id as roleId,
tr.role_name as roleName
FROM tb_role tr
LEFT JOIN tb_perm_role tpr ON tr.role_id = tpr.role_id
LEFT JOIN tb_perm tp ON tpr.perm_id = tp.id ${ew.customSqlSegment}
</select>
mapper
List<RolePermsDTO> selectByRoleId(@Param(Constants.WRAPPER) Wrapper<RolePermsDTO> wrapper);
@Test
public void test2(){
QueryWrapper<RolePermsDTO> wrapper = new QueryWrapper<>();
wrapper.eq("tr.role_id", 1);
tbPermService.selectByRoleId(wrapper);
}
${ew.sqlSet}
LambdaUpdateWrapper<User> wrapper = Wrappers.<User>lambdaUpdate().set(User::getNickName, "1").eq(User::getUserId, 1);
this.userMapper.updateUser(wrapper);
int updateUser(@Param(Constants.WRAPPER) Wrapper<User> updateWrapper);
<update id="updateUser">
update user
set ${ew.sqlSet}
where ${ew.sqlSegment}
</update>
自定义排序
<select id="selectByPrimaryKeys" resultMap="rm">
select
<include refid="Goods_Column_List"/>
from goods_info
where goods_id in
<foreach item="id" collection="list" open="(" separator="," close=")">
#{id}
</foreach>
order by field(goods_id,
<foreach item="id" collection="list" separator=",">
#{id}
</foreach>
);
</select>
主键
我们知道,对于一个大型应用,其访问量是非常巨大的,就比如说一个网站每天都有人进行注册,注册的用户信息就需要存入数据表,随着日子一天天过去,数据表中的用户越来越多,此时数据库的查询速度就会受到影响,所以一般情况下,当数据量足够庞大时,数据都会做分库分表的处理。
然而,一旦分表,问题就产生了,很显然这些分表的数据都是属于同一张表的数据,只是因为数据量过大而分成若干张表,那么这几张表的主键 id 该怎么管理呢?每张表维护自己的 id?那数据将会有很多的 id 重复,这当然是不被允许的,其实,我们可以使用算法来生成一个绝对不会重复的 id,这样问题就迎刃而解了,事实上,分布式 id 的解决方案有很多:
https://www.cnblogs.com/haoxinyue/p/5208136.html
这里多说一点, 当实体类的主键名为 id,并且数据表的主键名也为 id 时,此时 MyBatisPlus 会自动判定该属性为主键 id,倘若名字不是 id 时,就需要标注 @TableId 注解,若是实体类中主键名与数据表的主键名不一致,则可以进行声明:
@TableId(value = "uid",type = IdType.AUTO) // 设置主键策略
private Long id;
mybatis-plus:
global-config:
db-config:
id-type: auto
主键策略
3.2之后变为
AUTO 主键自增,开发者无需赋值
NONE(默认) 设置主键,通过雪花算法实现
INPUT 主键需要开发者手动赋值,如果没有手动赋值,则通过自增方式赋值
ASSIGN_ID 主键类型为Long、Integer、String,通过雪花算法自动赋值
ASSIGN_UUID 主键的数据类型为String,不包含下划线的UUID
Sequcence主键
主键生成策略必须使用INPUT
支持父类定义@KeySequence子类继承使用
支持主键类型指定(3.3.0开始自动识别主键类型)内置支持:
- DB2KeyGenerator
- H2KeyGenerator
- KingbaseKeyGenerator
- OracleKeyGenerator
- PostgreKeyGenerator
如果内置支持不满足你的需求,可实现IKeyGenerator接口来进行扩展
举个栗子
@KeySequence("SEQ_USER")
public class User {
@TableId(value = "id", type = IdType.INPUT)
private Long id;
private String name;
private Integer age;
private String email;
}
springboot
方式一:
@Configuration
public class MybatisPlusConfig {
/**
* sequence主键,需要配置一个主键生成器
* 配合实体类注解 {@link KeySequence} + {@link TableId} type=INPUT
* @return
*/
@Bean
public H2KeyGenerator h2KeyGenerator(){
return new H2KeyGenerator();
}
}
方式二:
@Bean
public MybatisPlusPropertiesCustomizer plusPropertiesCustomizer() {
return plusProperties -> plusProperties.getGlobalConfig().getDbConfig().setKeyGenerator(new H2KeyGenerator());
}
SqlInjector
@PostMapping("/deleteAll")
public String deleteAll() {
int i = this.userMapper.deleteAll();
System.out.println(i);
return "deleteAll";
}
public class DeleteAllMethod extends AbstractMethod {
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
// 执行的SQL
String sql = "delete from " + tableInfo.getTableName();
// mapper接口方法名
String method = "deleteAll";
SqlSource sqlSource = this.languageDriver.createSqlSource(this.configuration, sql, modelClass);
return this.addDeleteMappedStatement(mapperClass, method, sqlSource);
}
}
@Component
public class MySqlInjector extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass) {
// MP自定义的SQL语句,如果不添加,MP自定义的语句就不能用了
List<AbstractMethod> methodList = super.getMethodList(mapperClass);
methodList.add(new DeleteAllMethod());
return methodList;
}
}
public interface UserMapper extends BaseMapper<User> {
int deleteAll();
}
如果每张表都需要删除全部,那我们为每个Mapper都写一个deleteAll()方法,非常的繁琐。这时候我们可以自己建立一个MyMapper接口,MyMapper接口继承BaseMapper,而类似于UserMapper的自定义Mapper全部继承MyMapper,这样我们就只需要在MyMapper中编写一个deleteAll方法,再由UserMpper和其他Mapper继承就可以实现deleteAll()方法的重用。
当然实际上不会删除全表,也不会真的删除数据,这里举个小栗子
数据安全保护
多数据源
插件
自动生成代码
依赖
<!-- 代码生成器依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.4.1</version>
</dependency>
<!-- 模板引擎依赖-->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>
非默认模板引擎依赖
Freemarker
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
Beetl
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>beetl</artifactId>
<version>latest-beetl-version</version>
</dependency>
注意!如果您选择了非默认引擎,需要在 AutoGenerator 中 设置模板引擎。
AutoGenerator generator = new AutoGenerator();
// set freemarker engine
generator.setTemplateEngine(new FreemarkerTemplateEngine());
// set beetl engine
generator.setTemplateEngine(new BeetlTemplateEngine());
启动测试类
import com.baomidou.mybatisplus.generator.config.*;
@Test
public void contextLoads() {
// 需要构建一个 代码自动生成器 对象
AutoGenerator mpg = new AutoGenerator();
mpg.setTemplateEngine(new FreemarkerTemplateEngine());
// 1、全局配置
GlobalConfig gc = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
gc.setOutputDir(projectPath+"/src/main/java");
gc.setAuthor("Chuang-2");
gc.setOpen(false); // 不打开资源管理器
gc.setFileOverride(false); // 是否覆盖
gc.setServiceName("%sService");// 去掉Service接口的首字母I
// gc.setIdType(IdType.AUTO);// 自增Id
gc.setIdType(IdType.ASSIGN_ID);// 雪花算法
gc.setDateType(DateType.TIME_PACK);// DateType.TIME_PACK LocalDateTime, DateType.SQL_PACK Timestamp,DateType.ONLY_DATE Date
gc.setSwagger2(true);
mpg.setGlobalConfig(gc);
//2、设置数据源
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/edu?useSSL=false&useUnicode=true&characterEncoding=utf-8");
dsc.setDriverName("com.mysql.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("123456");
dsc.setDbType(DbType.MYSQL);
mpg.setDataSource(dsc);
//3、包的配置
PackageConfig pc = new PackageConfig();
pc.setParent("com.example.demo");
pc.setEntity("entity");
pc.setMapper("mapper");
pc.setService("service");
pc.setController("controller");
mpg.setPackageInfo(pc);
// 自定义配置
InjectionConfig cfg = new InjectionConfig() {
@Override
public void initMap() {
// to do nothing
}
};
// 如果模板引擎是 freemarker
String templatePath = "/templates/mapper.xml.ftl";
// 如果模板引擎是 velocity
// String templatePath = "/templates/mapper.xml.vm";
// 自定义输出配置
List<FileOutConfig> focList = new ArrayList<>();
// 自定义配置会被优先输出
focList.add(new FileOutConfig(templatePath) {
@Override
public String outputFile(TableInfo tableInfo) {
// 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
return projectPath + "/src/main/resources/mappers/" +
tableInfo.getEntityName() + "Mapper" + StringPool.DOT_XML;
}
});
cfg.setFileOutConfigList(focList);
mpg.setCfg(cfg);
//4、策略配置
StrategyConfig strategy = new StrategyConfig();
strategy.setInclude("tb_generator"); // 设置要映射的表名,多个表则逗号隔开
strategy.setTablePrefix(pc.getModuleName() + "_"); // 去掉表前缀
strategy.setNaming(NamingStrategy.underline_to_camel);// 数据库表映射到实体的命名策略
strategy.setColumnNaming(NamingStrategy.underline_to_camel);// 据库表字段映射到实体的命名策略
// strategy.setChainModel(true);// 开启链式编程,lombok的注解
// strategy.setLogicDeleteFieldName("deleted");
// 自动填充配置
/*TableFill gmtCreate = new TableFill("gmt_create", FieldFill.INSERT);
TableFill gmtModified = new TableFill("gmt_modified",
FieldFill.INSERT_UPDATE);
ArrayList<TableFill> tableFills = new ArrayList<>();
tableFills.add(gmtCreate);
tableFills.add(gmtModified);
strategy.setTableFillList(tableFills);*/
// strategy.setVersionFieldName("version");// 乐观锁
strategy.setRestControllerStyle(true);// RestController
// strategy.setControllerMappingHyphenStyle(true); //localhost:8080/hello_id_2
mpg.setStrategy(strategy);
mpg.execute(); //执行
}
mybatisX
mapper跳转
mybatisCodeHelperPro
插件
下载:
破解:
toolkit
package com.baomidou.mybatisplus.core.toolkit;
public interface Constants extends StringPool {
String MYBATIS_PLUS = "mybatis-plus";
String MD5 = "MD5";
String ENTITY = "et";
String ENTITY_DOT = "et.";
String WRAPPER = "ew";
String WRAPPER_DOT = "ew.";
String WRAPPER_ENTITY = "ew.entity";
String WRAPPER_SQLSEGMENT = "ew.sqlSegment";
String WRAPPER_EMPTYOFNORMAL = "ew.emptyOfNormal";
String WRAPPER_NONEMPTYOFNORMAL = "ew.nonEmptyOfNormal";
String WRAPPER_NONEMPTYOFENTITY = "ew.nonEmptyOfEntity";
String WRAPPER_EMPTYOFWHERE = "ew.emptyOfWhere";
String WRAPPER_NONEMPTYOFWHERE = "ew.nonEmptyOfWhere";
String WRAPPER_ENTITY_DOT = "ew.entity.";
String U_WRAPPER_SQL_SET = "ew.sqlSet";
String Q_WRAPPER_SQL_SELECT = "ew.sqlSelect";
String Q_WRAPPER_SQL_COMMENT = "ew.sqlComment";
String COLUMN_MAP = "cm";
String COLUMN_MAP_IS_EMPTY = "cm.isEmpty";
String COLLECTION = "coll";
String WHERE = "WHERE";
String MP_OPTLOCK_VERSION_ORIGINAL = "MP_OPTLOCK_VERSION_ORIGINAL";
String MP_OPTLOCK_VERSION_COLUMN = "MP_OPTLOCK_VERSION_COLUMN";
String MP_OPTLOCK_ET_ORIGINAL = "MP_OPTLOCK_ET_ORIGINAL";
String WRAPPER_PARAM = "MPGENVAL";
String WRAPPER_PARAM_FORMAT = "#{%s.paramNameValuePairs.%s}";
}
public interface StringPool {
String AMPERSAND = "&";
String AND = "and";
String AT = "@";
String ASTERISK = "*";
String STAR = "*";
String BACK_SLASH = "\\";
String COLON = ":";
String COMMA = ",";
String DASH = "-";
String DOLLAR = "$";
String DOT = ".";
String DOTDOT = "..";
String DOT_CLASS = ".class";
String DOT_JAVA = ".java";
String DOT_XML = ".xml";
String EMPTY = "";
String EQUALS = "=";
String FALSE = "false";
String SLASH = "/";
String HASH = "#";
String HAT = "^";
String LEFT_BRACE = "{";
String LEFT_BRACKET = "(";
String LEFT_CHEV = "<";
String DOT_NEWLINE = ",\n";
String NEWLINE = "\n";
String N = "n";
String NO = "no";
String NULL = "null";
String OFF = "off";
String ON = "on";
String PERCENT = "%";
String PIPE = "|";
String PLUS = "+";
String QUESTION_MARK = "?";
String EXCLAMATION_MARK = "!";
String QUOTE = "\"";
String RETURN = "\r";
String TAB = "\t";
String RIGHT_BRACE = "}";
String RIGHT_BRACKET = ")";
String RIGHT_CHEV = ">";
String SEMICOLON = ";";
String SINGLE_QUOTE = "'";
String BACKTICK = "`";
String SPACE = " ";
String TILDA = "~";
String LEFT_SQ_BRACKET = "[";
String RIGHT_SQ_BRACKET = "]";
String TRUE = "true";
String UNDERSCORE = "_";
String UTF_8 = "UTF-8";
String US_ASCII = "US-ASCII";
String ISO_8859_1 = "ISO-8859-1";
String Y = "y";
String YES = "yes";
String ONE = "1";
String ZERO = "0";
String DOLLAR_LEFT_BRACE = "${";
String HASH_LEFT_BRACE = "#{";
String CRLF = "\r\n";
String HTML_NBSP = " ";
String HTML_AMP = "&";
String HTML_QUOTE = """;
String HTML_LT = "<";
String HTML_GT = ">";
String[] EMPTY_ARRAY = new String[0];
byte[] BYTES_NEW_LINE = "\n".getBytes();
}