7、神经网络的全连接
损失函数
为何要设定损失函数?
我们想获得的是能提高识别精度的参数,特意再导入一个损失函数。
为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
之所以不能用识别精度作为指标,是因为这样一来绝大多数地方的导数都会变为0,导致参数无法更新。
总结:在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为0。
举例子,假设某个神经网络正确识别出了100笔训练数据中的32笔,此时识别精度为32 %。如果以识别精度为指标,即使稍微改变权重参数的值,识别精度也仍将保持在32 %,不会出现变化。微调参数,是无法改善识别精度的。即便识别精度有所改善,它的值也不会像32.0123 … %这样连续变化,而是变为33 %、34 %这样的不连续的、离散的值。而如果把损失函数作为指标,则当前损失函数的值可以表示为0.92543 … 这样的值。并且,如果稍微改变一下参数的值,对应的损失函数也会像0.93432 … 这样发生连续性的变化。(参考:深度学习入门)
交叉熵
特点:
1、不确定性
2、惊喜程度
3、更高的熵等于更少的信息
演示代码:
import torch
x1 = torch.full([4], 1 / 4.0)
y1 = -(x1 * torch.log2(x1)).sum()
x2 = torch.tensor([0.1, 0.1, 0.1, 0.7])
y2 = -(x2 * torch.log2(x2)).sum()
x3 = torch.tensor([0.001, 0.001, 0.001, 0.999])
y3 = -(x3 * torch.log2(x3)).sum()
print(y1)
print(y2)
print(y3)
结果:
tensor(2.)
tensor(1.3568)
tensor(0.0313)
对分类来说,这个交叉熵会更好用。
线性层的计算 : x @ w.t() + b
x是4张照片且已经打平了 (4, 784)
我们希望 (4, 784) —> (4, 512)
这样的话w因该是 (784, 512)
但由于pytorch默认 第一个维度是 channel-out(目标), 第二个维度是 channel-in (输入) , 所以需要用一个转置
MNIST数据集分类代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size = 200
learning_rate = 0.01
epochs = 10
# 下载数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
w1, b1 = torch.randn(200, 784, requires_grad=True), \
torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True), \
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True), \
torch.zeros(10, requires_grad=True)
# kaiming正态分布
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
logits = forward(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
结果:
Test set: Average loss: 0.0011, Accuracy: 9371/10000 (94%)
这结果是很差的,因为只用了3层全连接网络结构
GPU加速
只需要在代码运行前加一行代码就行了,然后把网络模型、损失函数和数据都放进cuda里,这样就进行了GPU加速了。
device = torch.device('cuda:0')
visdom可视化
先安装,代码:
pip install visdom -i https://pypi.tuna.tsinghua.edu.cn/simple
再用一行代码打开服务器:
python -m visdom.server
结果为:
例子代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size = 200
learning_rate = 0.01
epochs = 10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
结果为: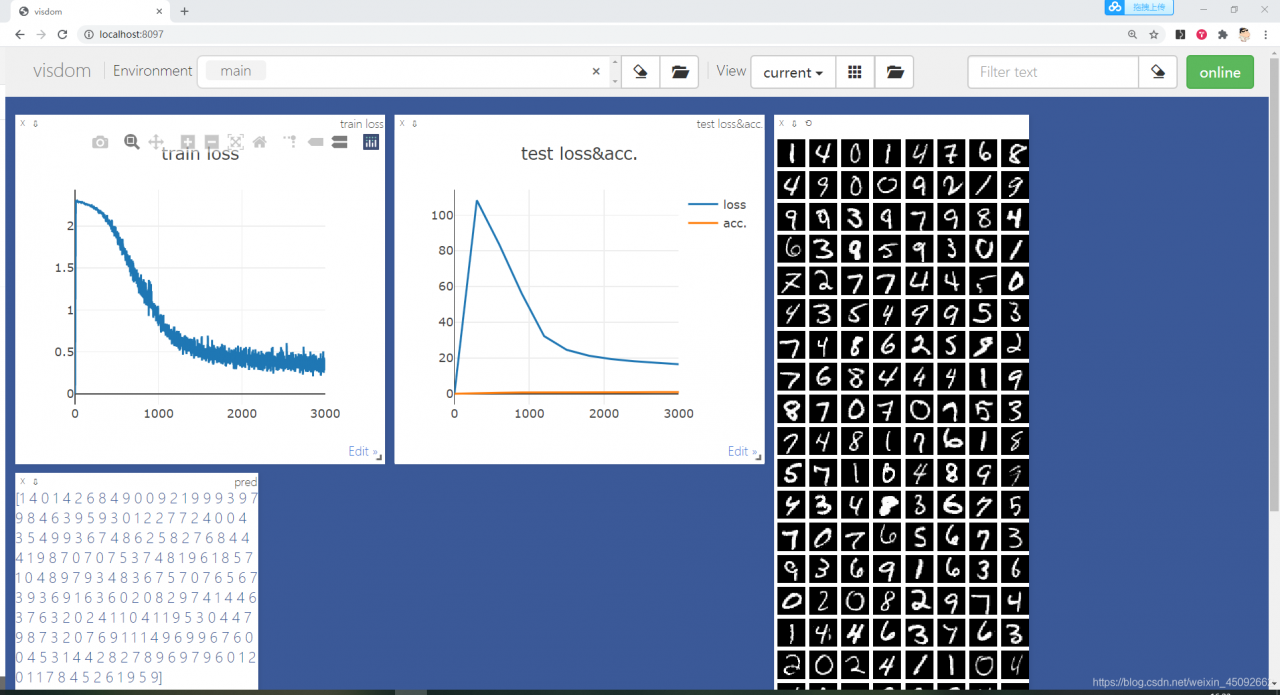
图像很直观,和tensorboard有的一比。
2021年2月9号更新
Visdom.line()的单条曲线的用法。
from visdom import Visdom
viz = Visdom()
# viz.line([Y轴的值],[X轴的值], win='窗口ID名称', opts=dict(title='标题名称))
# 先初始化viz.line()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([loss.item()],[global_step], win='train_loss', update='append')
viz.line()里面接受的数据是numpy数据,不是tensor数据。update='append’把数据添加在后面。
item()的用法,参考博客https://blog.csdn.net/weixin_45092662/article/details/113768531
Visdom.line()的多条曲线的用法。
from visdom import Visdom
viz = Visdom()
# 先初始化viz.line()
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',legend=['loss', 'acc.']))
viz.line([[test_loss, correct / len(test_loader.dataset)]],[global_step], win='test', update='append')
visual X
from visdom import Visdom
viz = Visdom()
viz.images(data.view(-1,1,28,28), win='x')
viz.text(str(pred.detach().cup().numpy()),win='pred',opts=dict(title='pred'))
有用请点个赞!!
本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/weixin_45092662。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。