深度学习BN(Batch Normalization),LN(Layer_Normalization)的区别
为什么会用BN和LN?
神经网络的本质就是训练层数之间的参数,若层数过多,一层之间的参数发生变化,则会导致后面的层数放大错误,所以我们一般训练的时候都会选择较小的学习率,还有参数的初始化也很重要。BN层往往加在激励函数和全连接层之间。它可以将每层的数据分布都收缩到差不多的位置,加快模型收敛。因为许多的激活函数越往两边,梯度越小。所以还可以防止梯度消失。在网络的训练中,BN的使用使得一个minibatch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。
BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。LayerNorm则是通过对Hidden size这个维度归一化来让分布稳定下来。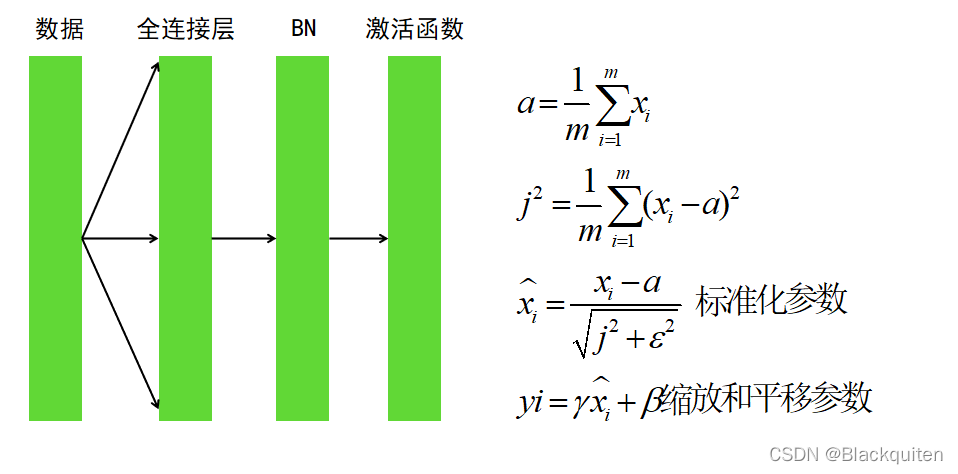
其中gamma是可以自己学习的参数。
| Batch Normalization | Layer_Normalization | |
|---|---|---|
| 处理对象 | 一批样本 | 单个样本 |
| 归一化维度 | 同一维度特征 | 全部特征 |
版权声明:本文为u014136435原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。