环境搭建
1. 环境搭建
2. 部署大框架
2.0框架图

2.1 filebeat采集日志文件推倒kafka指定的topic
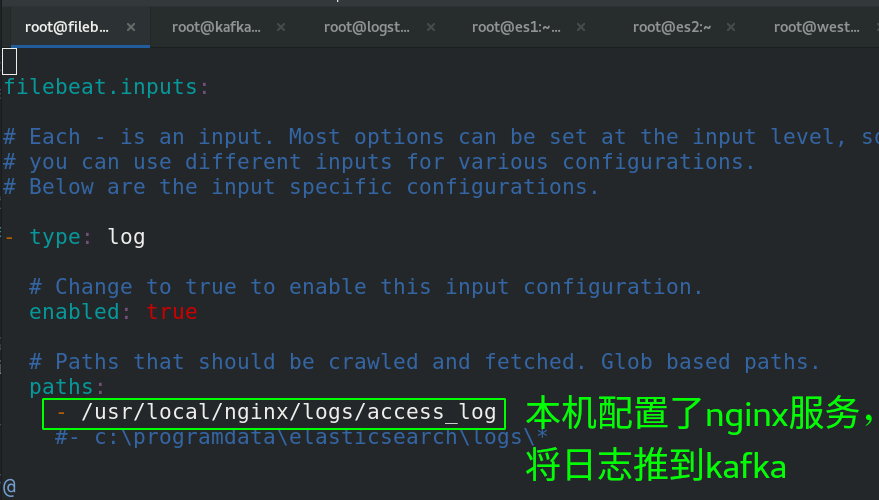
-注: nginx和filebeat配置在了一台机器
2.1.1 filebeat配置(将日志信息推到kafka)
##修改完配置信息。启动之后,如果kafka开着,会自动创建filebeat配置的topic
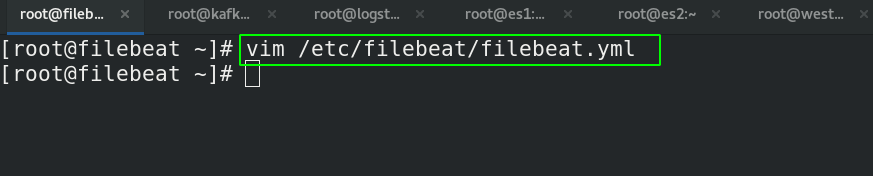
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log ##类型必须是log,因为传送的是nginx日志
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /usr/local/nginx/logs/access_log ##路径是nginx的日志
#-------------------------- kafka output --------------------##推送到kafka
setup.template.name: "nginx" ##日志显示的模板信息
setup.template.pattern: "nginx-*"
setup.ilm.enabled: false
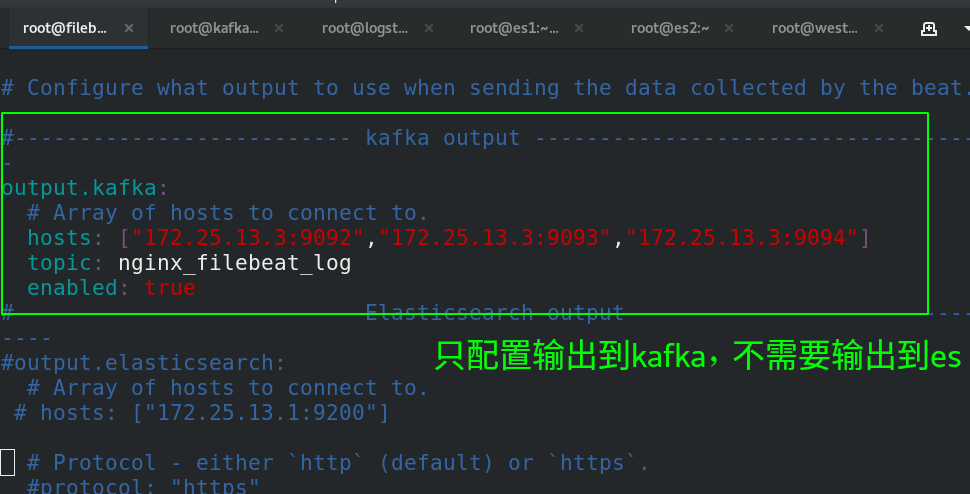
output.kafka:
# Array of hosts to connect to.
hosts: ["172.25.13.3:9092","172.25.13.3:9093","172.25.13.3:9094"]
topic: nginx_filebeat_log
enabled: true

2.1.2 配置kafka、logstash信息
##1、启动kafka,启动命令可以查看前面的博客。
##2、创建topic
[root@kafka ~]# kafka-topics.sh --zookeeper localhost:2181,localhost:2182,localhost:2183 --create --topic nginx_filebeat_log --partitions 3 --replication-factor 3 ##创建指定的topic
[root@kafka ~]# kafka-topics.sh --zookeeper localhost:2181,localhost:2182,localhost:2183 -list
__consumer_offsets
nginx_filebeat_log ##创建成功
test-topic
##3、配置并启动filebeat
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml ##读取指定路径内容
paths:
- /usr/local/nginx/logs/access.log
[root@filebeat ~]# systemctl restart filebeat.service
##3.验证kafka是否可以消费数据
[root@kafka ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --topic nginx_filebeat_log --from-beginning
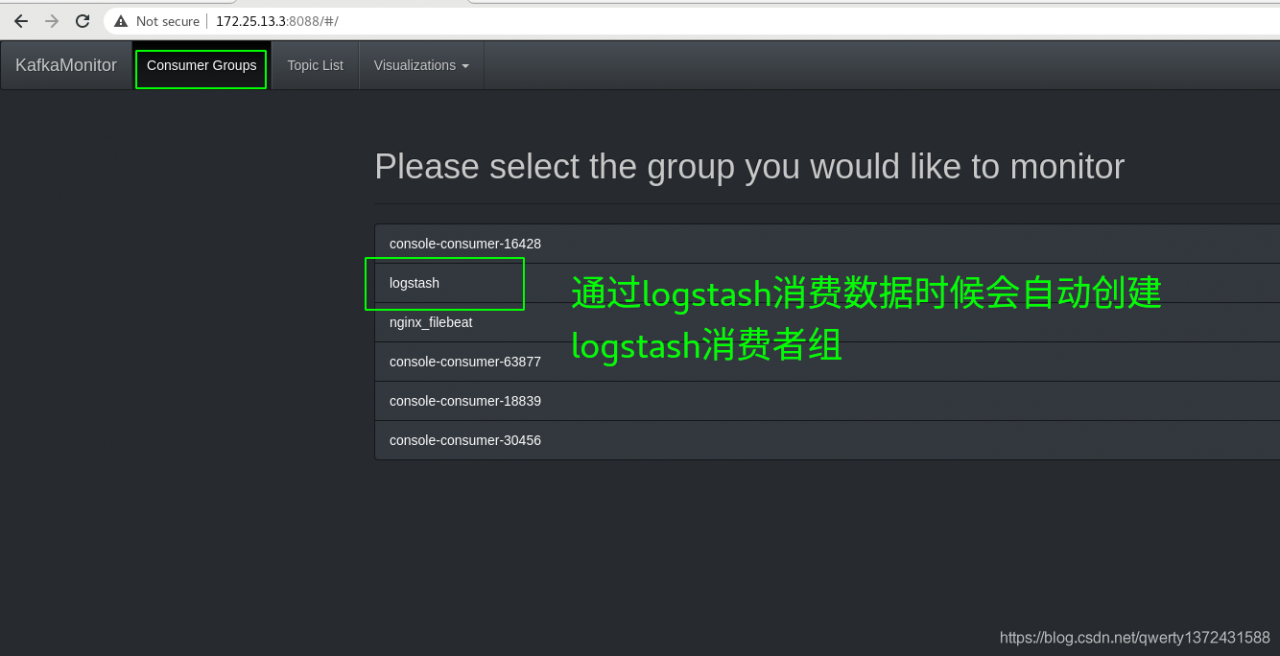
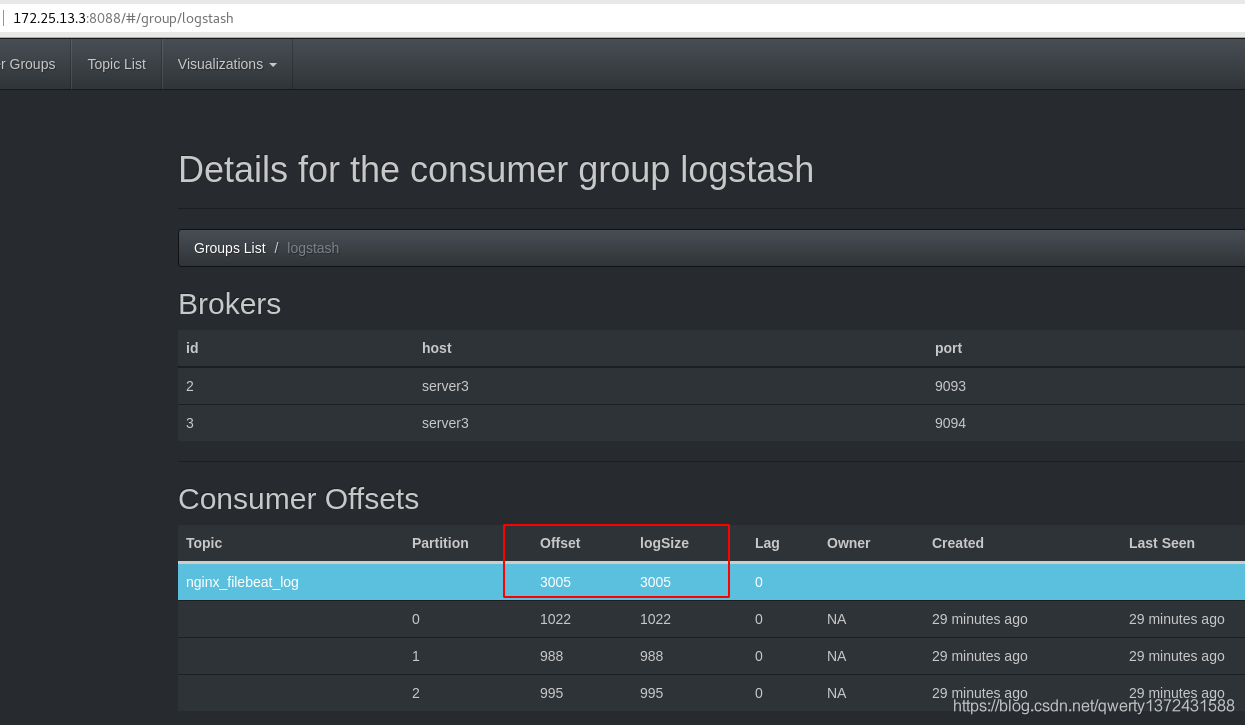
##如果有日志信息的输出则说明可以消费数据,也可以通过访问http://172.25.13.3:8088这个kafka监控查看
##4、配置logstash(负责消费)
[root@logstashkibana conf.d]# pwd
/etc/logstash/conf.d
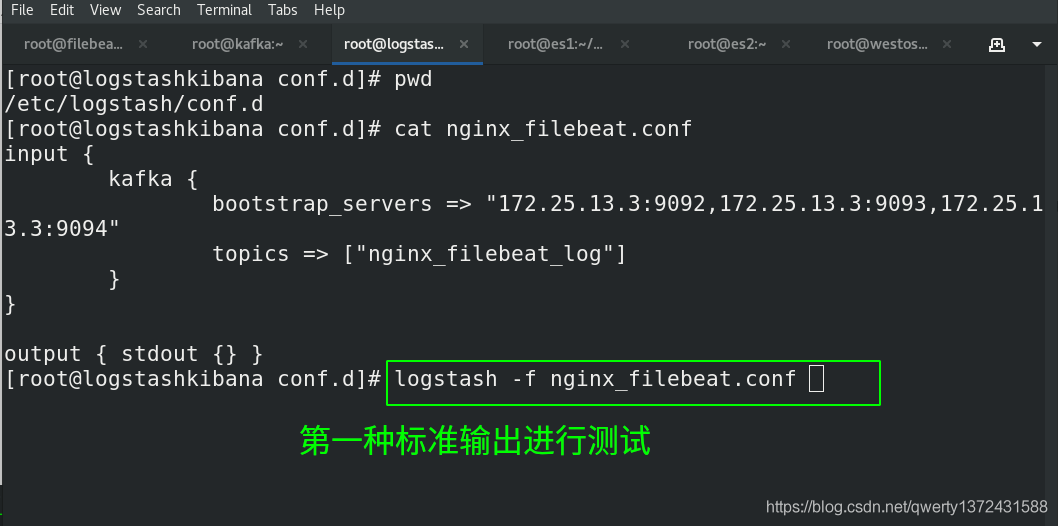
[root@logstashkibana conf.d]# cat nginx_filebeat.conf ##查看配置文件(第一种配置:标准输出)
input {
kafka {
bootstrap_servers => "172.25.13.3:9092,172.25.13.3:9093,172.25.13.3:9094"
topics => ["nginx_filebeat_log"]
}
}
output { stdout {} } ##标准输出filebeat读取的日志文件
#第二种配置(输出到es)
[root@logstashkibana conf.d]# cat nginx_filebeat.conf
input {
kafka {
bootstrap_servers => "172.25.13.3:9092,172.25.13.3:9093,172.25.13.3:9094"
topics => ["nginx_filebeat_log"]
}
}
output {
stdout {}
elasticsearch {
hosts => ["172.25.13.1:9200"]
index => "nginx-%{+yyyy.MM.dd}"
}
}
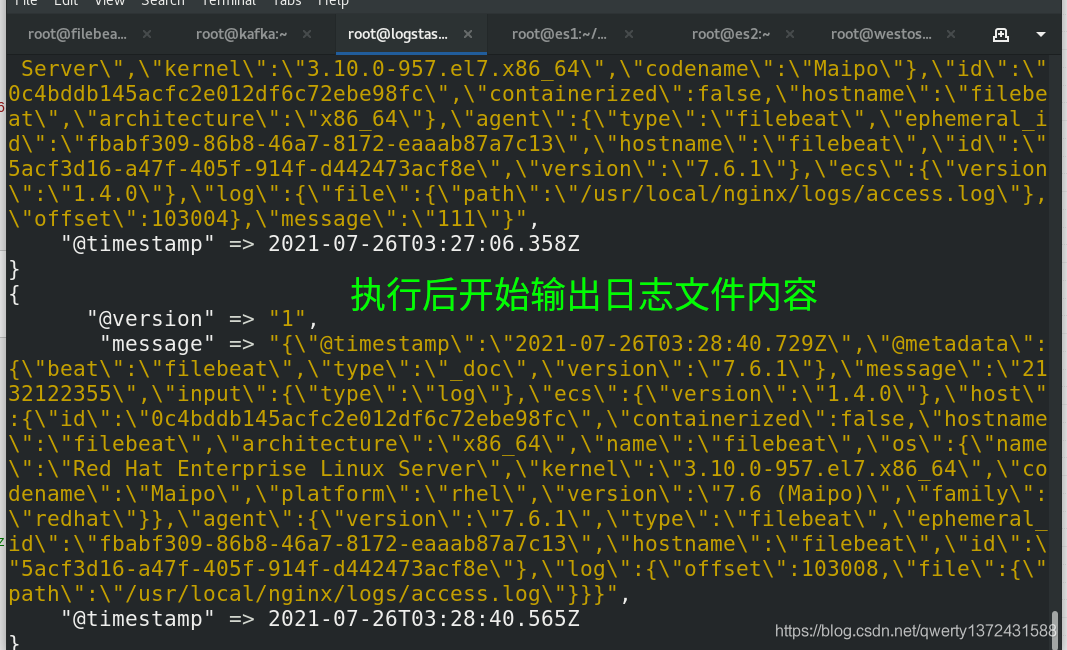
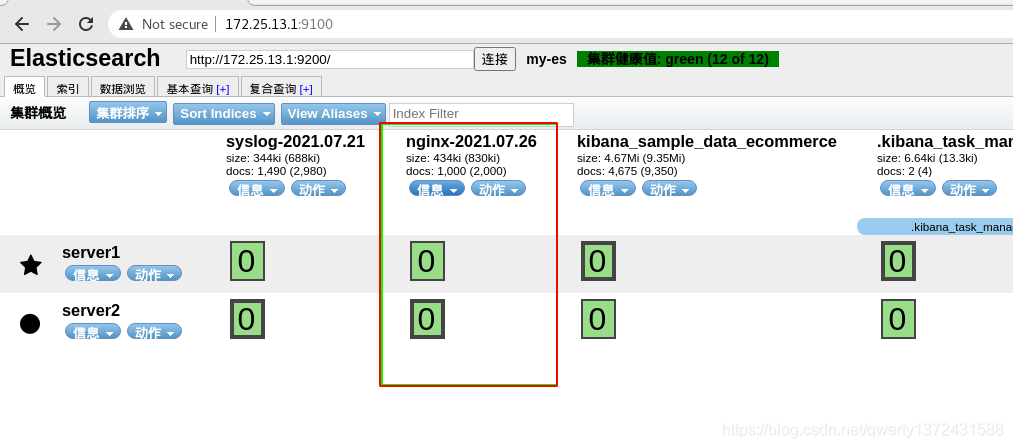
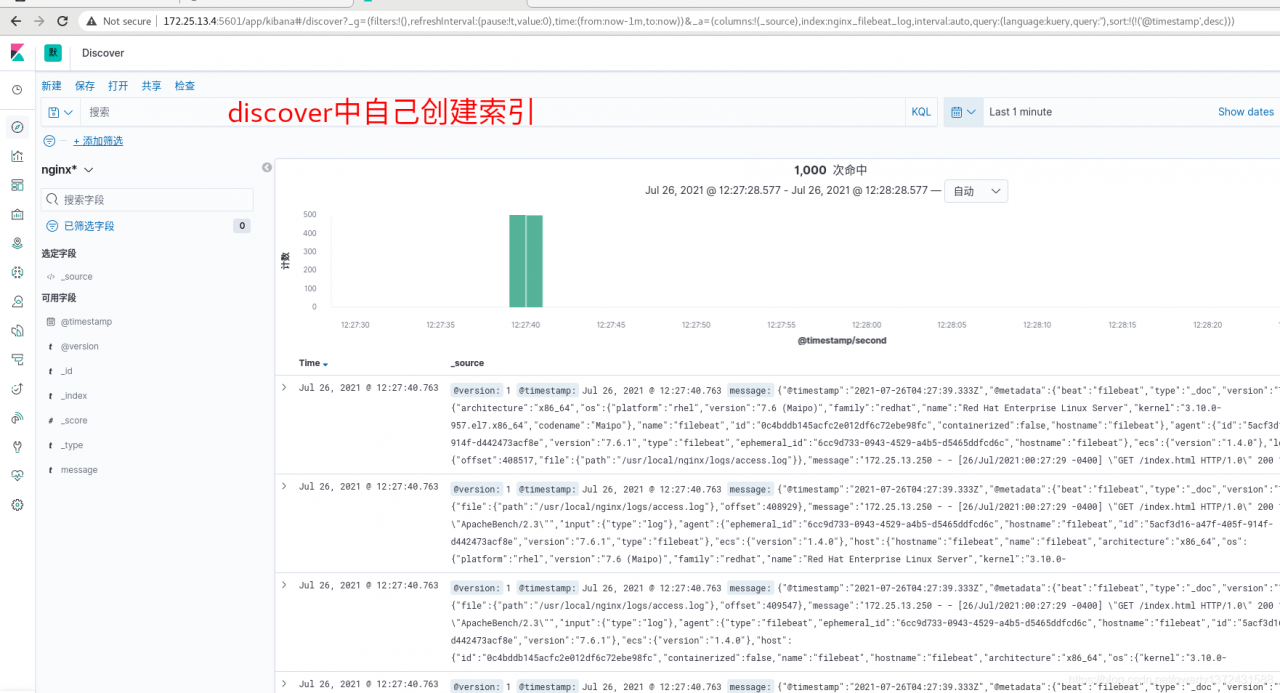
##5、下图查看效果

验证kafka是否可以消费数据
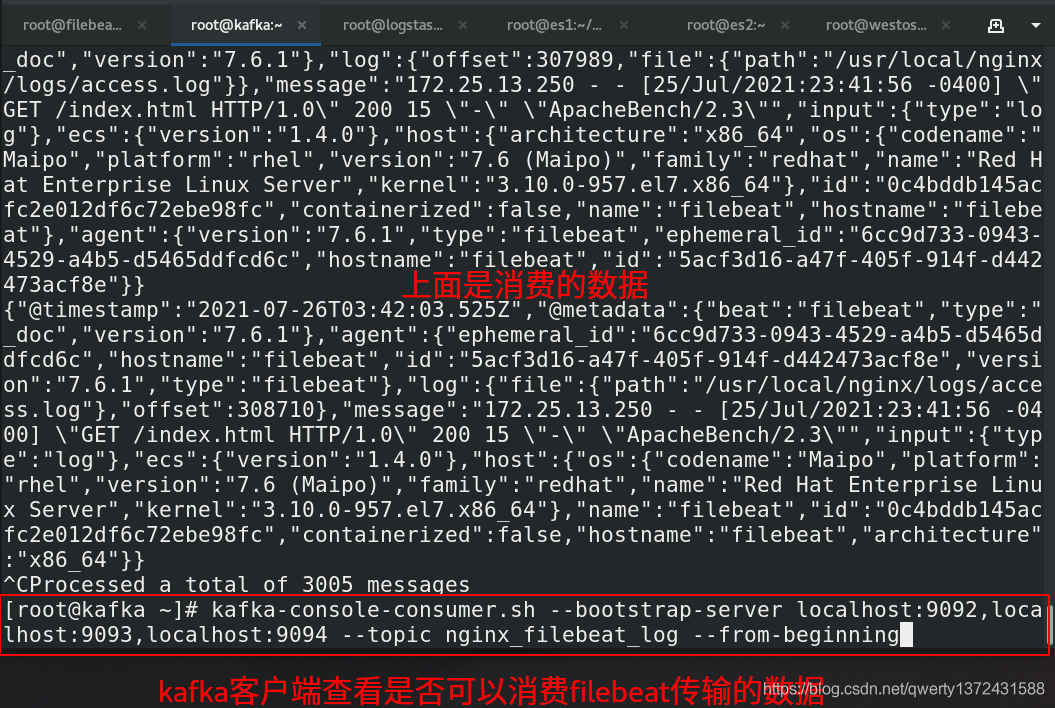


验证logstash是否可以消费数据
版权声明:本文为qwerty1372431588原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。