Spark SQL整合hive就是获取hive表中的元数据信息(在mysql中),然后通过Spark SQL来操作数据。
整合步骤:
1、拷贝hive配置文件到spark
- 查看hive 目录中conf目录下的配置文件,hive-site.xml,可以发现之前配置的hive的元数据信息在master的mysql数据库中。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>- 整合需要spark能够读取找到Hive的元数据以及数据存放位置。将hive-site.xml文件拷贝到Spark的conf目录下,同时添加metastore的url配置(对应hive安装节点,我的为master节点)。
具体配置如下:
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
# 添加metastore的url配置(对应hive安装节点,我的为master节点)
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9000</value>
</property>- 修改完后再发送给其他节点
scp hive-site.xml slave1:/usr/local/spark/conf/
scp hive-site.xml slave2:/usr/local/spark/conf/2、拷贝hive中mysql驱动到spark
在master中hive的lib目录下执行以下命令(因为在安装hive时已经拷贝了mysql驱动):
切换到hive的lib目录下查看mysql驱动包:
cd /usr/local/apache-hive-1.2.2-bin/lib/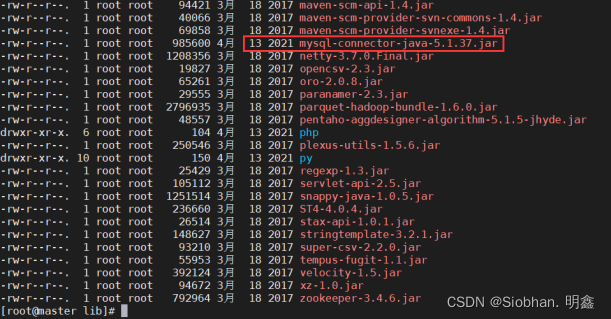
cp mysql-connector-java-5.1.37.jar /usr/local/spark/jars/
scp mysql-connector-java-5.1.37.jar slave1:/usr/local/spark/jars/
scp mysql-connector-java-5.1.37.jar slave2:/usr/local/spark/jars/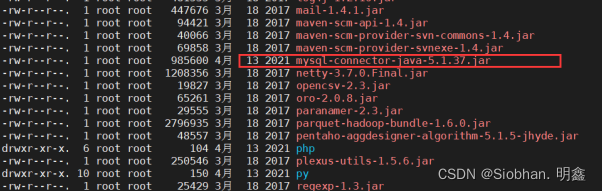
3、启动服务
- 启动HDFS,YARN集群
[root@master ~]# start-all.sh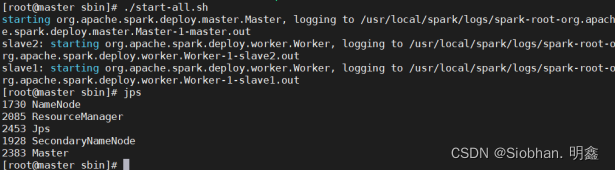
- 检查mysql是否启动:
#查看状态
service mysqld status#启动
service mysqld start- 启动hive metastore服务
bin/hive --service metastore
- 启动hive:
cd /usr/local/apache-hive-1.2.2-bin/
bin/hive 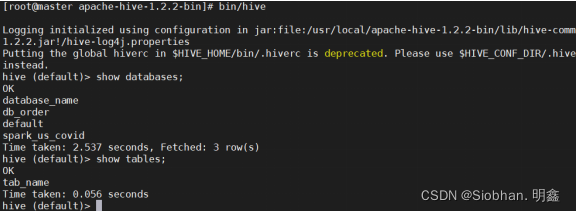
- 启动spark
[root@master ~]# cd /usr/local/spark/sbin
[root@master sbin]# ./start-all.sh启动spark-shell
[root@master ~]# cd /usr/local/spark/bin
[root@master spark]# ./spark-shell
[root@master ~]# cd /usr/local/spark/bin
[root@master spark]# ./spark-shell在spark安装目录的bin目录下:
启动spark-sql
bin/spark-sql
#查看数据库
show databases; 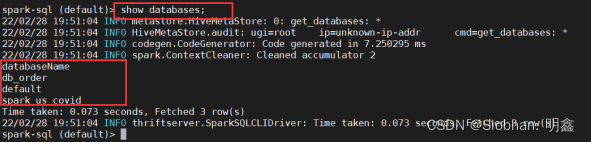
#使用数据库
use spark_us_covid
#查看表
show tables;
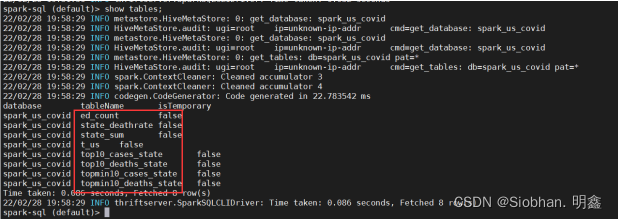
#查看表数据select * from top10_cases_state;
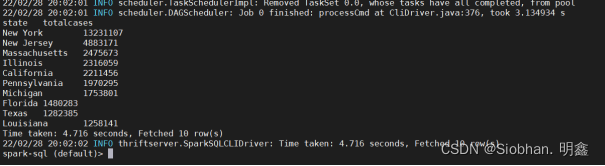
启动spark-shell进行查询:
spark.sql("show databases").collect();
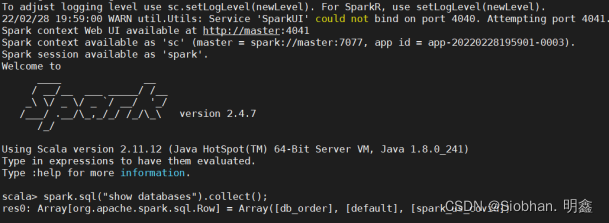
到此,spark整合hive全部完成。本次使用的hive为1.2.2的版本,spark为spark-2.4.7-hadoop2.7。而我的虚拟机中hadoop版本为2.8,可以向下兼容。
不存在hive与spark不兼容的情况,所以在遇到这种问题时可以考虑自己的spark jars包中是否有hive的相关jar包。
版权声明:本文为weixin_46474921原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。