1. 为什么有string类
C 语言中,字符串是以 ‘\0’ 结尾的一些字符的集合,为了操作方便, C 标准库中提供了一些 str 系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP 的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
在 OJ 中,有关字符串的题目基本以 string 类的形式出现,而且在常规工作中,为了简单、方便、快捷,基本都使用string 类,很少有人去使用 C 库中的字符串操作函数。
2. 什么是string类
string是个类,是模板的实例化。

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1To2otnl-1659949768958)(Image/image-20220716145502512.png)]](https://code84.com/wp-content/uploads/2022/09/321c1cda47d34217844693e06adce5c7.png)
编码问题
针对不同的文字,需要不同的编码来支持。

| 针对的编码类型 | ||
|---|---|---|
| char | utf-8 | 都是Unicode编码的延申 |
| char16_t | utf-16 | |
| char32_t | utf-32 | |
| wchar_t | gbk | 国标 |
string是表示字符序列的类
标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性。
string 类使用 char作为它的字符类型,具有默认的 char_traits 和 allocator类型。
string 类是 basic_string 模板类的一个实例,它使用 char 来实例化 basic_string 模板类,并用 char_traits 和 allocator 作为 basic_string 的默认参数 。
注意,这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符 ( 如 UTF-8) 的序列,这个类的所有成员( 如长度或大小 ) 以及它的迭代器,将仍然按照字节 ( 而不是实际编码的字符 ) 来操作。
总结:
string 是表示字符序列的字符串类
该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作 string 的常规操作。
不能操作多字节或者变长字符的序列。
在使用 string 类时,必须包含#include 头文件以及using namespace std;
3. string的常用接口
构造函数
| default (1) | string(); |
|---|---|
| copy (2) | string (const string& str); |
| substring (3) | string (const string& str, size_t pos, size_t len = npos); |
| from c-string (4) | string (const char* s); |
| from sequence (5) | string (const char* s, size_t n); |
| fill (6) | string (size_t n, char c); |
| range (7) | template <class InputIterator> string (InputIterator first, InputIterator last); |
关于npos?
until the end of the string
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3CKQ0CIG-1659949768959)(Image/image-20220714163747522.png)]](https://code84.com/wp-content/uploads/2022/09/dbbf07e0bc41476a87487f91273e1a66.png)
(3) substring constructor
Copies the portion of str that begins at the character position pos and spans len characters (or until the end of str, if either str is too short or if len is string::npos
(4) from c-string
Copies the null-terminated character sequence pointed by s.
range (7)详见迭代器。
void StringTest1()
{
string s1; // empty string, with a length of zero characters
string s2("hello world");
s2 += "!!!";
string s3(s2); // construct a copy of s2
string s4 = s3;
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
string s5("https://cplusplus.com/reference/string/string/string/", 4);
cout << s5 << endl;
string s6(10, 'c');
cout << s6 << endl;
string s7(s2, 6, 5);
cout << s7 << endl;
string s8(s7.begin(), s7.end());
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ucDqQEVy-1659949768960)(Image/image-20220714164237743.png)]](https://code84.com/wp-content/uploads/2022/09/df0b27c3a8b3472ca6ef7370f3978728.png)
赋值重载
| string (1) | string& operator= (const string& str); |
|---|---|
| c-string (2) | string& operator= (const char* s); |
| character (3) | string& operator= (char c); |
void StringTest2()
{
string s1("hello");
string s2 = s1; // s1 must be different from *this
cout << s2 << endl;
s2 = "hello world"; // s: pointer to a null-terminated sequence of characters
cout << s2 << endl;
s2 = 'a'; // the string length becomes 1
cout << s2 << endl;
}
遍历:
下标+[]
operator[]返回的是引用,因此可读可写。
void StringTest3()
{
string s1("hello world");
cout << s1.size() << endl; // size()不包括\0
// 尽量统一用size
for (size_t i = 0; i < s1.size(); ++i)
{
//其实就是 s1.operator[](i)
cout << s1[i] << " ";
//s1[i] = 'x'; // 也可以修改
}
cout << endl;
// 用at()也可以
const char* str = "world";
cout << str[1] << endl; // 本质是指针偏移,*(str+1),str指向字符串的首地址
for (size_t i = 0; i < s1.size(); ++i)
{
cout << s1.at(i) << " ";
}
cout << endl;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OguWhAvv-1659949768961)(Image/image-20220716152223741.png)]](https://code84.com/wp-content/uploads/2022/09/1483055f99d4442ea25c7001bbead523.png)
传引用返回的是那个位置对应的字符,可读可写。
operator[]和at对比
at是早期给出来的,和[]类似。
他们都有普通版本和const版本。const版本,针对const对象。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SYtVadbH-1659949768961)(Image/image-20220716095649714.png)]](https://code84.com/wp-content/uploads/2022/09/9aab9fac48154e7e9ca5434a04a35ea1.png)
operator[]出现越界,报的是断言错误。it causes undefined behavior.
void StringTest8()
{
string s1("hello");
const string s2 = "hello";
s1[0] = 'x';
//s2[0] = 'x'; // err 调用的是const版本的operator[]无法修改
s1[6]; // 通过断言报错
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AsCNEgYG-1659949768963)(Image/image-20220716100702013.png)]](https://code84.com/wp-content/uploads/2022/09/f7adaf7ec0cc4465bc4d270d00c0aed6.png)
而at()是抛异常,可以进一步捕获分析。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yQ4SWH0s-1659949768964)(Image/image-20220716095902421.png)]](https://code84.com/wp-content/uploads/2022/09/de77e65617114c58a9b570b4b084aebb.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oK10yhwX-1659949768965)(Image/image-20220716101107503.png)]](https://code84.com/wp-content/uploads/2022/09/e9d889fe66e34bcda8a07abeeea7bf91.png)
void StringTest8()
{
string s1("hello");
const string s2 = "hello";
s1.at(6);
}
int main()
{
try
{
StringTest8();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z9Yeav67-1659949768978)(Image/image-20220716101022372.png)]](https://code84.com/wp-content/uploads/2022/09/b1908961f3c7469f82a0d43d2fe6fc38.png)
迭代器
迭代器是类似指针的东西,它的用法就是模拟指针的。
而string类的迭代器底层恰巧就是原生指针。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-USyTHY5E-1659949768980)(Image/image-20220714172404506.png)]](https://code84.com/wp-content/uploads/2022/09/c56471dda70b4cde99519c87331722a0.png)
总的来说是4个版本:
- iterator
- const_iterator
- reverse_iterator
- const_reverse_iterator
| begin | Returns an iterator pointing to the first character of the string. |
| end | Returns an iterator pointing to the character that would follow the last character in the string. |
| rbegin | Returns a reverse iterator pointing to the last character of the string, its reverse beginning. |
| rend | Returns a reverse iterator pointing to the element preceding the first character of the string. |
注意:If the string object is const-qualified, the function returns a const_iterator.
**迭代器意义:**string,vector支持【】遍历,但是list map不支持【】,但我们可以都用迭代器去遍历。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7TgCc7Gc-1659949768981)(Image/Pasted image 20220321185727.png)]](https://code84.com/wp-content/uploads/2022/09/8e7570ff8d394f2b90648a48e954c98c.png)
void StringTest4()
{
string s2("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
反向迭代器:
这只是便于理解的图,实际上
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UAS465Il-1659949768982)(Image/Pasted image 20220321185741.png)]](https://code84.com/wp-content/uploads/2022/09/fac57e795e5e40198ff00815cda83208.png)
void StringTest7()
{
string s1("hello world");
string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
{
cout << *rit << " ";//d l r o w o l l e h
++rit;
}
cout << endl;
}
如果对象是被const修饰的,那么就要用const迭代器。
反向迭代器的const版本:
void StringTest9(const string& rs)
{
string::const_reverse_iterator rit = rs.rbegin();
// 这种太长的类型,其实就可以用auto自动推导类型
auto rit2 = rs.rbegin();
while (rit != rs.rend())
{
//(*rit) += 1;
cout << *rit << " ";
++rit;
}
cout << endl;
}
int main()
{
string s1 = "hello world";
StringTest9(s1);
return 0;
}
注意:
C++11提出了cbegin等替代begin的两个版本的函数。
不过实际中还是就用begin就够了。

范围for(C++11)
也叫做语法糖。
依次取容器中的数据,赋值给e,自动判断结束。
要想改变容器中的内容,需要加引用。
本质:被替换成迭代器?
void StringTest5()
{
string s1("123456");
for (auto e : s1)
{
cout << e << " ";// 1 2 3 4 5 6
}
cout << endl;
}
void StringTest5()
{
string s1("123456");
for (auto& e : s1)
{
e += 1;
cout << e << " "; // 2 3 4 5 6 7
}
cout << endl;
}
auto是自动推导,如果知道具体类型,写具体类型也行。
void StringTest5()
{
string s1("123456");
for (char &e : s1)
{
e += 1;
cout << e << " "; // 2 3 4 5 6 7
}
cout << endl;
}
容量:

| 函数名称 | 功能说明 |
|---|---|
| size | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty | 检测字符串释放为空串,是返回 true ,否则返回 false |
| clear | 清空有效字符 |
| reserve | 为字符串预留空间 |
| resize | 将有效字符的个数该成 n 个,多出的空间用字符 c 填充 |
size&length
size_t size() const;
size_t length() const;
Returns the length of the string, expressed in terms of bytes.
int main ()
{
std::string str ("Test string");
std::cout << "The size of str is " << str.size() << " bytes.\n"; // 11
std::cout << "The length of str is " << str.length() << " bytes.\n"; // 11
return 0;
}
max_size
size_t max_size() const;
Returns the maximum length the string can reach.
void Test9()
{
string s1;
string s2 = "hello world";
cout << s1.max_size() << endl; // 4611686018427387903
//64 位环境下int的最大值。
cout << s2.max_size() << endl; // 4611686018427387903
cout << s1.size() << endl; // 0
cout << s2.size() << endl; // 11
cout << s1.capacity() << endl; // 15
cout << s2.capacity() << endl; // 15
}
capacity
size_t capacity() const;
Returns the size of the storage space currently allocated for the string, expressed in terms of bytes.
The capacity is not necessarily equal to the string length. It can be equal or greater.
clear
clear的清除没有把空间清除,capacity还是15。
void Test9()
{
string s1;
string s2 = "hello world";
cout << s1.max_size() << endl; // 4611686018427387903
// 64 位环境下int的最大值。
cout << s2.max_size() << endl; // 4611686018427387903
cout << s1.size() << endl; // 0
cout << s2.size() << endl; // 11
cout << s1.capacity() << endl; // 15
cout << s2.capacity() << endl; // 15
s2.clear();
cout << s2.size() << endl;//0
cout << s2 << endl;
cout << s2.capacity() << endl; // 15
}
扩容问题
void StringTest10()
{
// 验证多久扩容一次
string s;
size_t sz = s.capacity();
cout << "making s grow:\n";
cout << "capacity changed: " << sz << '\n';
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
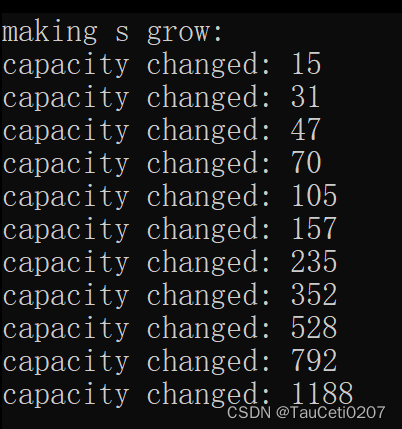
问题来了,频繁的扩容是不好的,如何在不改变push_back源代码的基础上降低扩容的次数?
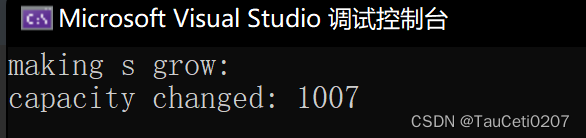
利用reserve
void StringTest10()
{
// 验证多久扩容一次
string s;
// 提前直到需要插入1000个数据的话,就提前声明好足够的容量
s.reserve(1000);
size_t sz = s.capacity();
cout << "making s grow:\n";
cout << "capacity changed: " << sz << '\n';
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
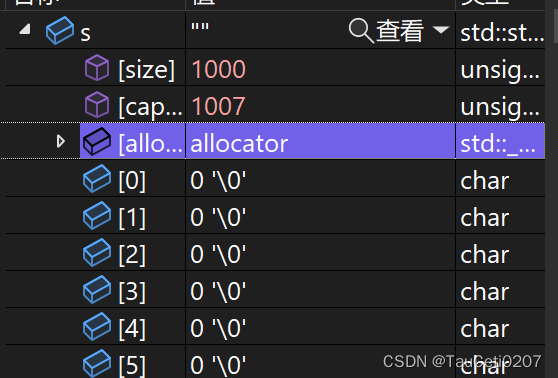
resize&reserve
void reserve (size_t n = 0);
void resize (size_t n);
void resize (size_t n, char c);
resize是开空间加初始化。
void StringTest10()
{
// 验证多久扩容一次
string s;
s.resize(1000); // resize还会进行初始化,占用空间,默认是\0
size_t sz = s.capacity();
cout << "making s grow:\n";
cout << "capacity changed: " << sz << '\n';
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}

当然也可以用s.resize(1000, 'x')指定初始化的内容
注意:resize并不改变已经存在的内容,只是一个补齐式的初始化。
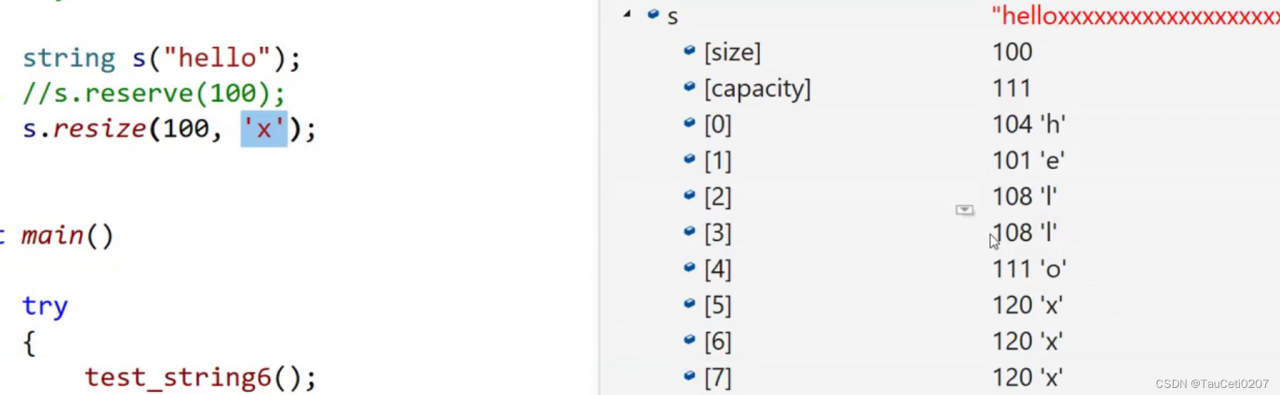
==注意:==VS下
reserve、resize都不会缩小容量
int main()
{
string s("hello world");
s.reserve(100);
s.reserve(10); // size、capacity都不改变
s.resize(10); // 会改变size,但不改变capacity
return 0;
}
总结:
size() 与 length() 方法底层实现原理完全相同,引入 size() 的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size() 。
clear() 只是将 string 中有效字符清空,不改变底层空间大小。
resize(size_t n) 与 resize(size_t n, char c) 都是将字符串中有效字符个数改变到 n 个,不同的是当字符个数增多时:resize(n) 用
\0来填充多出的元素空间, resize(size_t n, char c) 用字符c来填充多出的元素空间。注意:resize 在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0) :为 string 预留空间,不改变有效元素个数,当 reserve 的参数小于string的底层空间总大小时, reserver 不会改变容量大小。
修改:
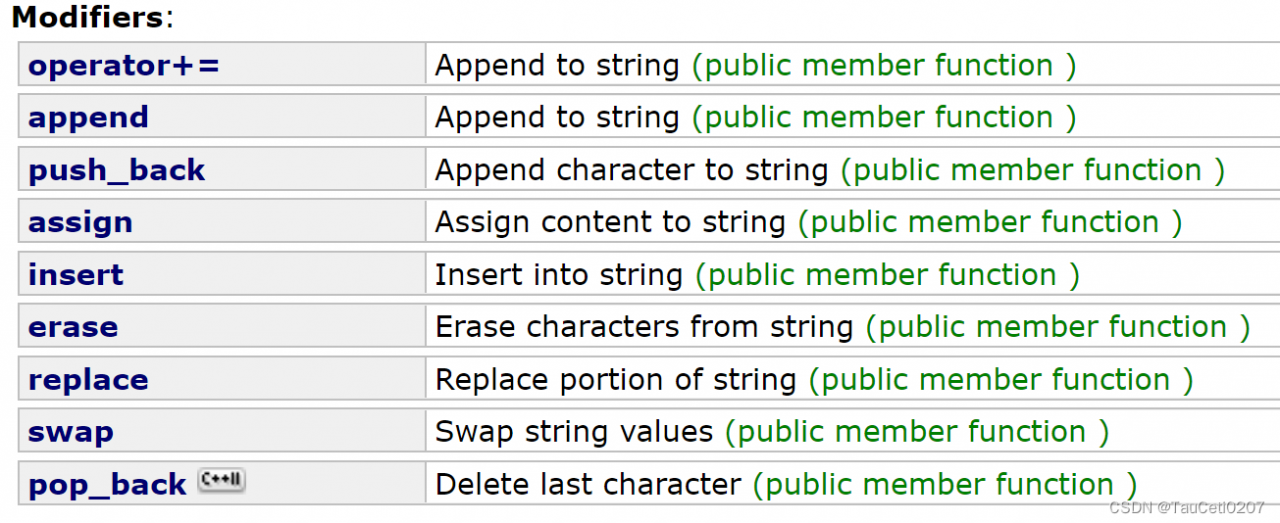
| 函数名称 | 功能说明 |
|---|---|
| push_back | 在字符串后尾插字符 c |
| append | 在字符串后追加一个字符串 |
| operator+= ( 重点 ) | 在字符串后追加字符串 str |
| c_str ( 重点 ) | 返回 C 格式字符串 |
| find + npos ( 重点 ) | 从字符串 pos 位置开始往后找字符 c ,返回该字符在字符串中的位置 |
| rfind | 从字符串 pos 位置开始往前找字符 c ,返回该字符在字符串中的位置 |
| substr | 在 str 中从 pos 位置开始,截取 n 个字符,然后将其返回 |
注意:
在 string 尾部追加字符时,
s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string 类的 += 操作用的比较多, += 操作不仅可以连接单个字符,还可以连接字符串。对 string 操作时,如果能够大概预估到放多少字符,可以先通过 reserve 把空间预留好。因为这样可以防止多次扩容导致多余的消耗
+=
实际中用的最多的就是+=。

push_back
void push_back (char c);
Appends character c to the end of the string, increasing its length by one.
void StringTest11()
{
string s;
s.push_back('x');
s.append("hello");
string s2("world");
s.append(s2);
cout << s << endl;
s += 'a';
s += "hello world";
s += s2;
cout << s << endl;
}
// xhelloworld
// xhelloworldahello worldworld
pop_back
void pop_back();
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s("C++");
s.pop_back();
s.pop_back();
cout << s << endl; //C
return 0;
}
append
| string (1) | string& append (const string& str); |
|---|---|
| substring (2) | string& append (const string& str, size_t subpos, size_t sublen); |
| c-string (3) | string& append (const char* s); |
| buffer (4) | string& append (const char* s, size_t n); |
| fill (5) | string& append (size_t n, char c); |
| range (6) | template <class InputIterator> string& append (InputIterator first, InputIterator last); |
int main ()
{
std::string str;
std::string str2="Writing ";
std::string str3="print 10 and then 5 more";
str.append(str2); // "Writing "
str.append(str3,6,3); // "10 "
str.append("dots are cool",5); // "dots "
str.append("here: "); // "here: "
str.append(10, '.'); // ".........."
str.append(str3.begin()+8, str3.end()); // " and then 5 more"
str.append(5, '.'); // "....."
std::cout << str << '\n'; // Writing 10 dots here: .......... and then 5 more.....
return 0;
}
insert
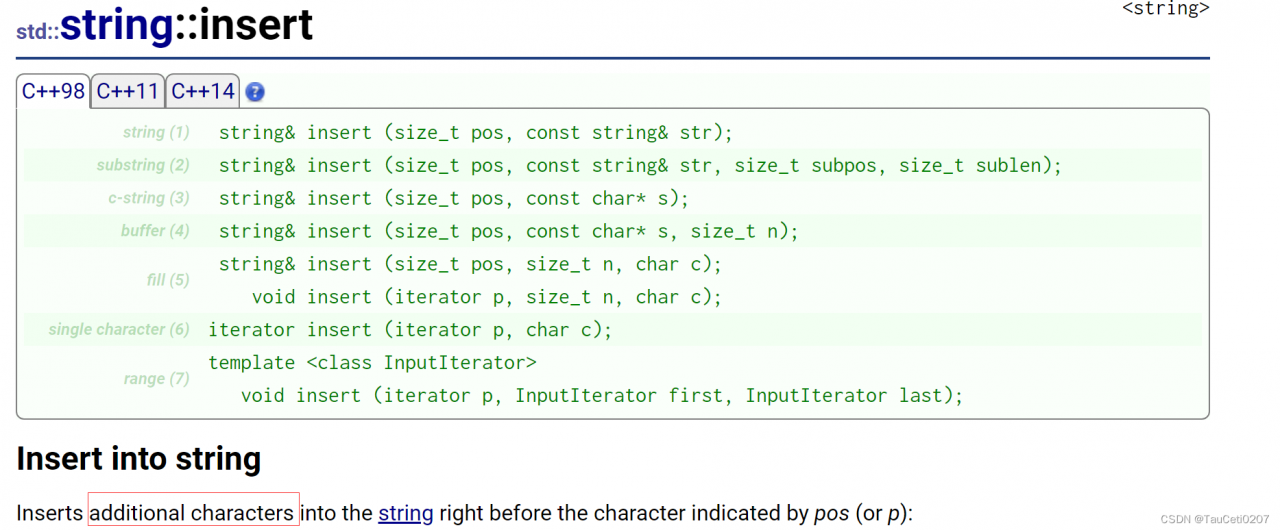
尽量少用insert,因为底层实现是数组,头部或中间插入需要挪动数据
void StringTest12()
{
string s("hello world");
s.insert(0, 1, 'x'); // 第一个位置插入x
cout << s << endl;
s.insert(s.begin(), 'y');
cout << s << endl;
s.insert(s.begin()+3, 'y');
cout << s << endl;
s.insert(0, "hello");
cout << s << endl;
}

erase
| sequence (1) | string& erase (size_t pos = 0, size_t len = npos); |
|---|---|
| character (2) | iterator erase (iterator p); |
| range (3) | iterator erase (iterator first, iterator last); |
void StringTest13()
{
string s1 = "";
s1.insert(0, "x");
s1.insert(0, "xyy");
cout << s1 << endl; // xyyx、
s1.erase(0, 1);
cout << s1 << endl; // yyx
s1.erase(0, 2);
cout << s1 << endl; // x
s1.insert(0, "x");
s1.insert(0, "xyy");
cout << s1 << endl; // xyyxx
s1.erase(s1.begin());
cout << s1 << endl; // yyxx
s1.erase(s1.begin() + 3);
cout << s1 << endl; // yyx
s1.erase(0); //表示删完,默认参数是npos
// s1.erase(0, 100); 这样也是删完了,毕竟只有3个字符
// s1.erase(); // 全部删完 缺省参数为0
cout << s1 << endl;
}
也不推荐用erase,底层实现是数组,删除数据需要挪动数据,效率降低。
assign
| string (1) | string& assign (const string& str); |
|---|---|
| substring (2) | string& assign (const string& str, size_t subpos, size_t sublen); |
| c-string (3) | string& assign (const char* s); |
| buffer (4) | string& assign (const char* s, size_t n); |
| fill (5) | string& assign (size_t n, char c); |
| range (6) | template <class InputIterator> string& assign (InputIterator first, InputIterator last); |
int main ()
{
std::string str;
std::string base="The quick brown fox jumps over a lazy dog.";
str.assign(base);
std::cout << str << '\n';
str.assign(base,10,9);
std::cout << str << '\n'; // "brown fox"
str.assign("pangrams are cool",7);
std::cout << str << '\n'; // "pangram"
str.assign("c-string");
std::cout << str << '\n'; // "c-string"
str.assign(10,'*');
std::cout << str << '\n'; // "**********"
str.assign<int>(10,0x2D);
std::cout << str << '\n'; // "----------"
str.assign(base.begin()+16,base.end()-12);
std::cout << str << '\n'; // "fox jumps over"
return 0;
}
replace

基本用不到。
int main ()
{
std::string base="this is a test string.";
std::string str2="n example";
std::string str3="sample phrase";
std::string str4="useful.";
// replace signatures used in the same order as described above:
// Using positions: 0123456789*123456789*12345
std::string str=base; // "this is a test string."
str.replace(9,5,str2); // "this is an example string." (1)
str.replace(19,6,str3,7,6); // "this is an example phrase." (2)
str.replace(8,10,"just a"); // "this is just a phrase." (3)
str.replace(8,6,"a shorty",7); // "this is a short phrase." (4)
str.replace(22,1,3,'!'); // "this is a short phrase!!!" (5)
// Using iterators: 0123456789*123456789*
str.replace(str.begin(),str.end()-3,str3); // "sample phrase!!!" (1)
str.replace(str.begin(),str.begin()+6,"replace"); // "replace phrase!!!" (3)
str.replace(str.begin()+8,str.begin()+14,"is coolness",7); // "replace is cool!!!" (4)
str.replace(str.begin()+12,str.end()-4,4,'o'); // "replace is cooool!!!" (5)
str.replace(str.begin()+11,str.end(),str4.begin(),str4.end());// "replace is useful." (6)
std::cout << str << '\n';
return 0;
}
swap
void swap (string& str);
template <class T> void swap (T& a, T& b);
void StringTest14()
{
string s1 = "hello";
string s2 = "world";
cout << s1 + s2 << endl;
// 效率高,直接交换指针
s1.swap(s2); // 在类域里面调用
cout << s1 + s2 << endl;
// 效率低,深拷贝交换
swap(s1, s2); // 全局的,调用algorithm库里面的
cout << s1 + s2 << endl;
}
库里面的swap是需要深拷贝交换的,因此效率低了。(前提是C++98)
查找
find
| string (1) | size_t find (const string& str, size_t pos = 0) const; |
|---|---|
| c-string (2) | size_t find (const char* s, size_t pos = 0) const; |
| buffer (3) | size_t find (const char* s, size_t pos, size_t n) const; |
| character (4) | size_t find (char c, size_t pos = 0) const; |
Return the position of the first character of the first match.
If no matches were found, the function returns string::npos.
rfind
| string (1) | size_t rfind (const string& str, size_t pos = npos) const; |
|---|---|
| c-string (2) | size_t rfind (const char* s, size_t pos = npos) const; |
| buffer (3) | size_t rfind (const char* s, size_t pos, size_t n) const; |
| character (4) | size_t rfind (char c, size_t pos = npos) const; |
Searches the string for the last occurrence of the sequence specified by its arguments.
void StringTest15()
{
string file("string.cpp");
size_t pos = file.find('.');
if (pos != string::npos)
{
// 可以通过手动计算子串个数
string suffix1 = file.substr(pos, file.size() - pos);
string suffix2 = file.substr(pos);
cout << "后缀:" << suffix1 << endl;
cout << "后缀:" << suffix2 << endl;
}
else
{
cout << "没找到后缀" << endl;
}
}
如果是像file.cpp.tar.zip这种有多个.呢,怎么取出最后的后缀?
void StringTest16()
{
// 借助rfind倒着找就行
string file("string.cpp.tar.zip");
size_t pos = file.rfind('.');
if (pos != string::npos)
{
string suffix = file.substr(pos);
cout << "后缀:" << suffix << endl;
}
else
{
cout << "没找到后缀" << endl;
}
}
void StringTest17()
{
// 取出url中的协议、域名、资源
string url1("http://www.cplusplus.com/reference/string/string/find/");
string url2("https://leetcode.cn/problems/design-skiplist/solution/tiao-biao-probabilistic-alternative-to-b-0cd8/");
string& url = url2;
// 协议 域名 资源
string protocol;
size_t pos1 = url.find("://");
if (pos1 != string::npos)
{
protocol = url.substr(0, pos1);
cout << "protocol:" << protocol << endl;
}
else
{
cout << "非法url" << endl;
}
string domain;
size_t pos2 = url.find('/', pos1 + 3);
if (pos2 != string::npos)
{
domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << "domain:" << domain << endl;
}
else
{
cout << "非法domain" << endl;
}
string uri = url.substr(pos2 + 1);
cout << "uri:" << uri << endl;
}

运算符相关
operator=
operator+=
operator+
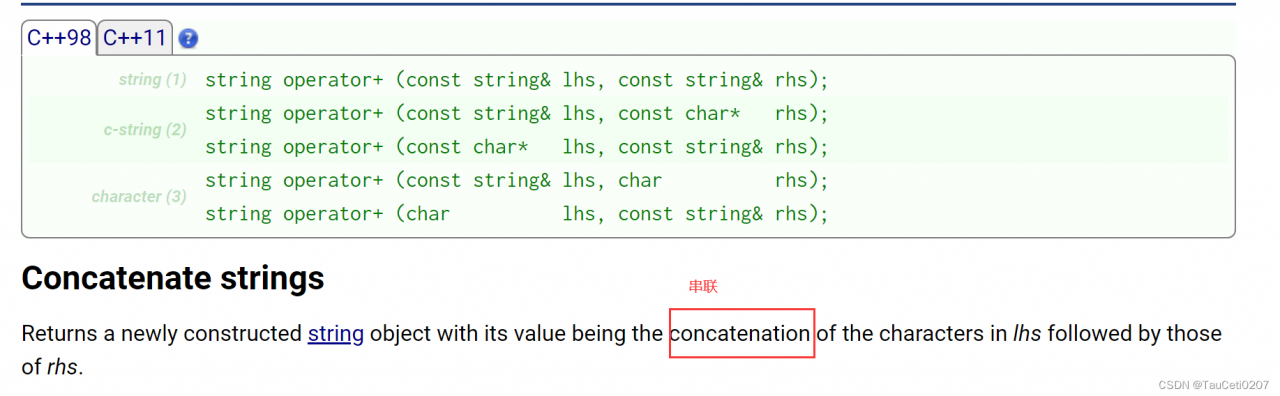
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
string s1("super");
string s2("man");
char str[] = "woman";
char ch = '!';
//string类 + string类
s = s1 + s2;
cout << s << endl; //superman
//string类 + 字符串
s = s1 + str;
cout << s << endl; //superwoman
//字符串 + string类
s = str + s1;
cout << s << endl; //womansuper
//string类 + 字符
s = s1 + ch;
cout << s << endl; //super!
//字符 + string类
s = ch + s1;
cout << s << endl; //!super
return 0;
}
relational operators
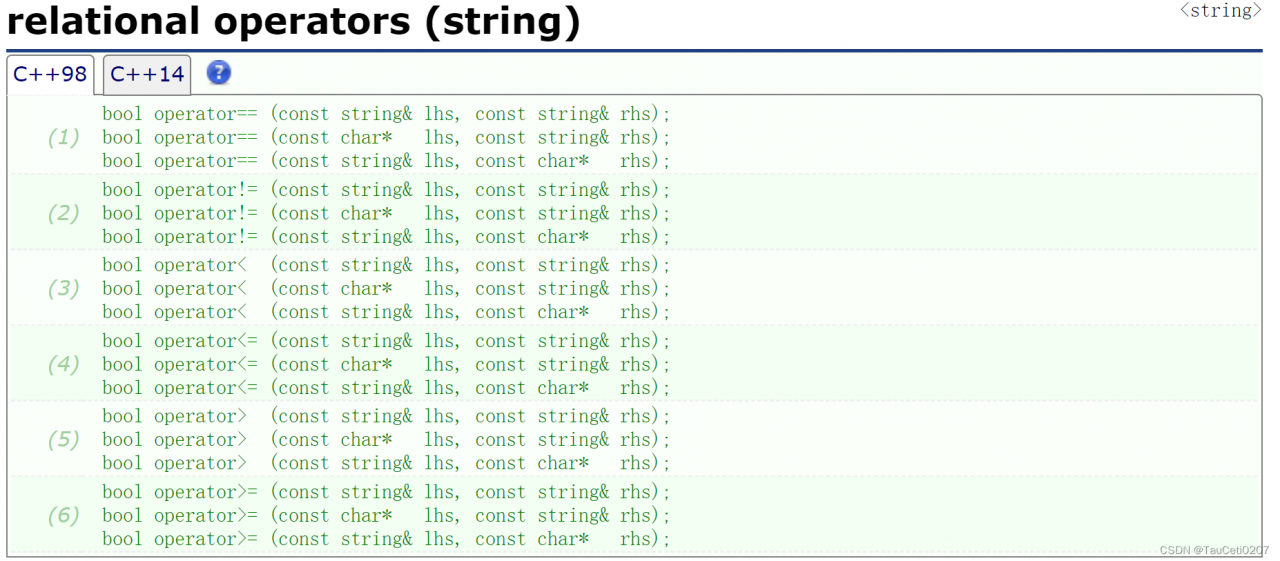
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1("abcd");
string s2("abde");
cout << (s1 > s2) << endl; //0
cout << (s1 < s2) << endl; //1
cout << (s1 == s2) << endl; //0
return 0;
}
operator>> & operator<<
istream& operator>> (istream& is, string& str);
Extracts a string from the input stream is, storing the sequence in str, which is overwritten (the previous value of str is replaced).
Notice that the istream extraction operations use whitespaces as separators; Therefore, this operation will only extract what can be considered a word from the stream. To extract entire lines of text, see the string overload of global function getline().
ostream& operator<< (ostream& os, const string& str);
Inserts the sequence of characters that conforms value of str into os.
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
cin >> s; //in
cout << s << endl; //out
return 0;
}
字符串相关
c_str
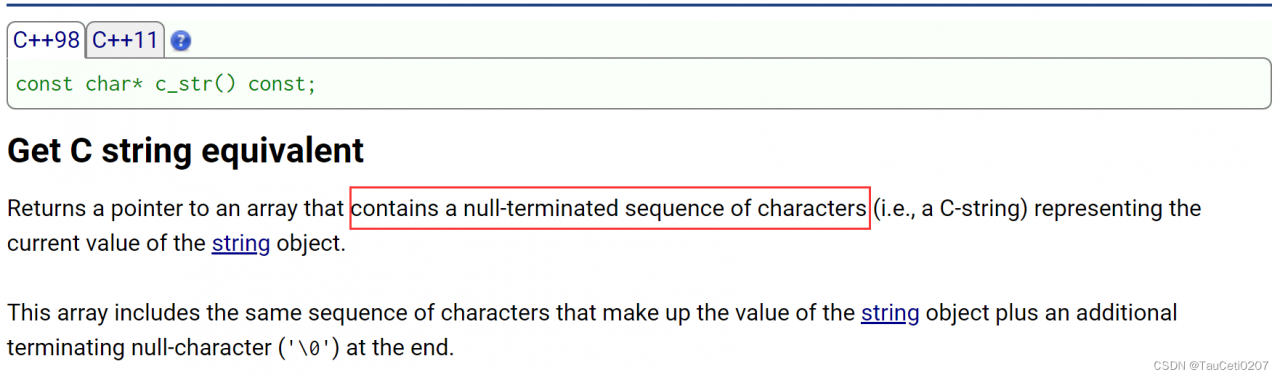
void Test13()
{
string s1("hello world");
cout << s1 << endl; //调用 operator<<(cout, s1)
// hello world
cout << s1.c_str() << endl; //调用 operator<<(cout, const char*)
// hello world
s1.resize(20); //默认增加的\0
s1 += "!!!";
cout << s1 << endl; //调用 operator<<(cout, s1)
// hello world !!!
cout << s1.c_str() << endl; //调用 operator<<(cout, const char*)
// hello world
cout << strlen(s1.c_str()) << endl; // 11
cout << s1.size() << endl; // 23
}
substr
string substr (size_t pos = 0, size_t len = npos) const;
Returns a newly constructed string object with its value initialized to a copy of a substring of this object.
The substring is the portion of the object that starts at character position pos and spans len characters (or until the end of the string, whichever comes first).
int main ()
{
std::string str="We think in generalities, but we live in details.";
std::string str2 = str.substr (3,5); // "think"
std::size_t pos = str.find("live"); // position of "live" in str
std::string str3 = str.substr (pos); // get from "live" to the end
std::cout << str2 << ' ' << str3 << '\n';
return 0;
}
to_string
C++11才支持。
string to_string (int val);
string to_string (long val);
string to_string (long long val);
string to_string (unsigned val);
string to_string (unsigned long val);
string to_string (unsigned long long val);
string to_string (float val);
string to_string (double val);
string to_string (long double val);

void test_string14()
{
int i;
cin >> i;
std::string s = to_string(i);
int val = stoi(s);
}

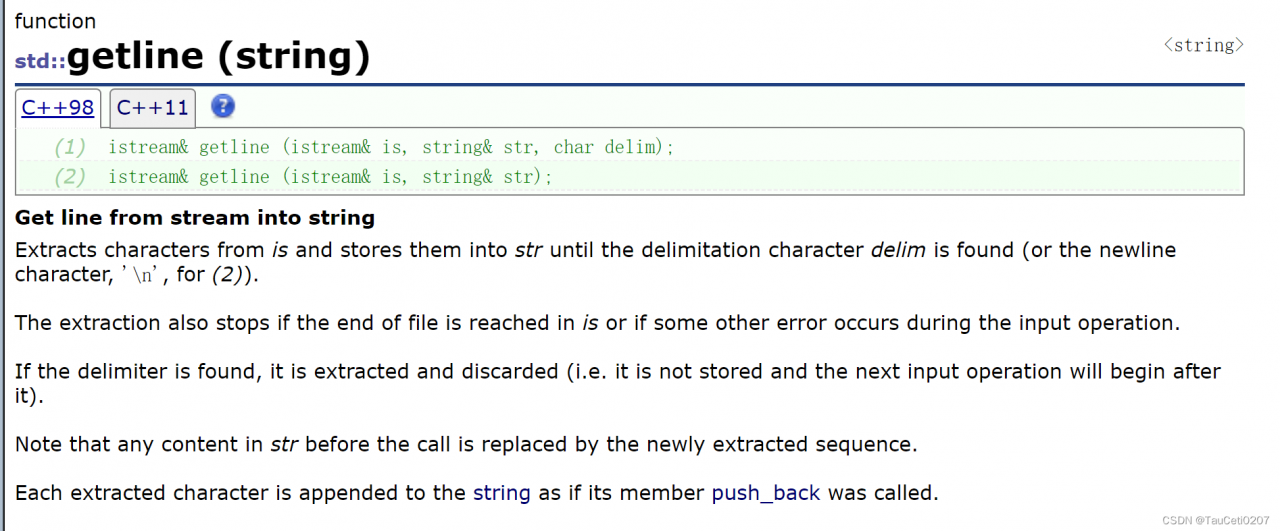
getline
我们知道,使用>>进行输入操作时,当>>读取到空格便会停止读取,基于此,我们将不能用>>将一串含有空格的字符串读入到string对象中。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
cin >> s; //输入:hello CSDN
cout << s << endl; //输出:hello
return 0;
}
getline函数将从is中提取到的字符存储到str中,直到读取到换行符’\n’为止。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
getline(cin, s); //输入:hello CSDN
cout << s << endl; //输出:hello CSDN
return 0;
}
getline函数将从is中提取到的字符存储到str中,直到读取到分隔符delim或换行符’\n’为止。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
getline(cin, s, 'D'); //输入:hello CSDN
cout << s << endl; //输出:hello CS
return 0;
}
4.string类的模拟实现
深浅拷贝
VS下的string类实现比较特别:
深浅拷贝详见这篇博客?戳我
reserve
// 仅对capacity处理
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1]; // 留一个空间给\0
strcpy(tmp, _str);
delete[] _str; // 清理旧空间
_str = tmp; // 指向新空间
_capacity = n;
}
}
resize
考虑3种情况:
- n小于size
- n大于capacity
- n大于size且小于capacity



// resize主要用于扩空间+初始化、删除部分数据保留前n个
// 考虑3种情况
void resize(size_t n, char ch = '\0')
{
// 1.n小于size,直接修改size并添加\0
if (n < _size)
{
_size = n;
_str[_size] = '\0';
}
else
{
// 2.n大于capacity,扩容后在末尾添加ch,注意最后放\0
if (n > _capacity)
{
reserve(n);
}
// 3.n小于capacity且n大于size,直接挨个赋值就行
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
operator[]
// 返回引用为了支持修改,也能减少拷贝
char& operator[](size_t pos)
{
assert(pos < strlen(_str));
return _str[pos];
}
// 提供给const对象调用的,返回的是const引用,不能修改了
const char& operator[](size_t pos) const
{
assert(pos < strlen(_str));
return _str[pos];
}
push_back
_capacity一直是0的话,析构的时候去delete会崩溃。
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity * 2); // 会崩溃
//reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
// 注意处理\0
++_size;
_str[_size] = '\0';
}
// 复用
void push_back2(char ch)
{
insert(_size, ch);
}
迭代器
string里的迭代器其实就是指针。
// string的迭代器其实就是指针
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
void test_string5()
{
yzq::string s1("hello world");
// 遍历
// 1.下标
for (size_t i = 0; i < s1.size(); ++i)
{
s1[i] += 1;
cout << s1[i] << " ";
}
cout << endl;
// 2.迭代器
yzq::string::iterator it = s1.begin();
while (it != s1.end())
{
*it -= 1;
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
try
{
test_string5();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
范围for
底层就是迭代器实现的,而且还规定了迭代器的函数必须为
begin()和end()
当把begin()改成Begin()时,迭代器还能正常运行,但是范围for就报错了。
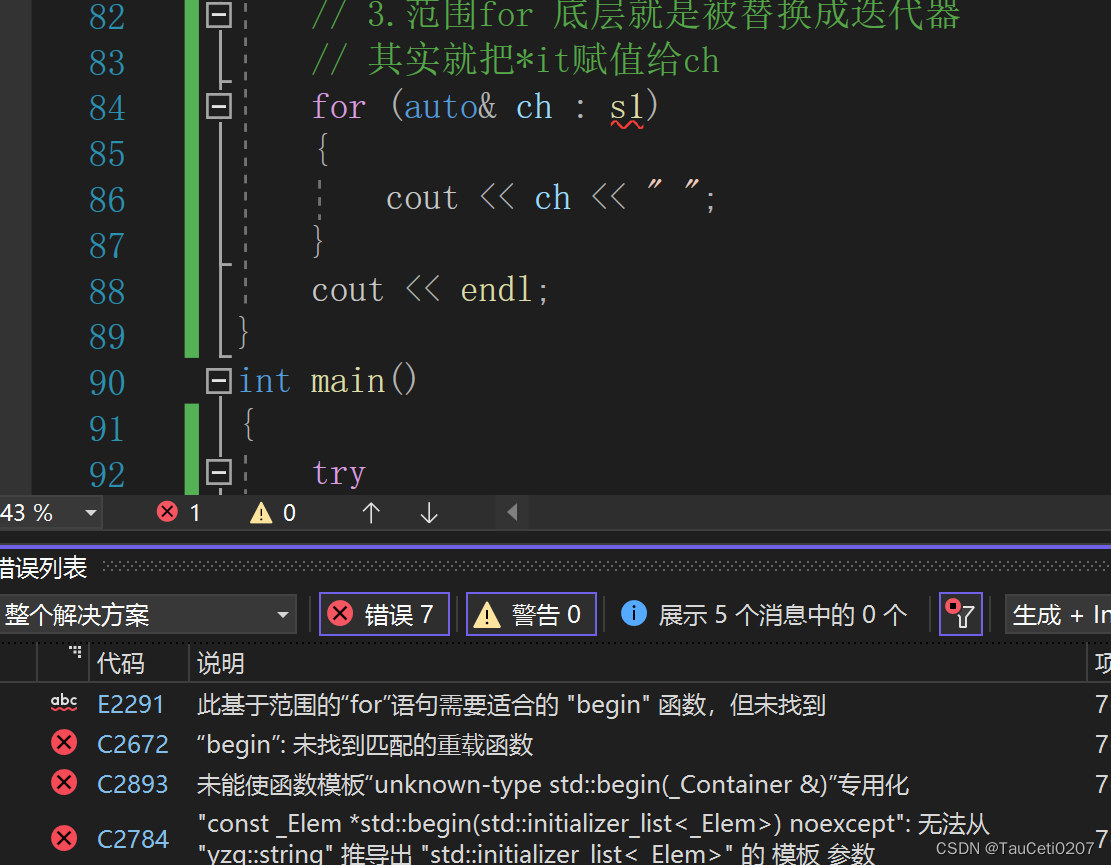
要想改变string的内容,范围for的auto需要传引用:
void test_string5()
{
yzq::string s1("hello world");
// 3.范围for 底层就是被替换成迭代器
// 其实就把*it赋值给ch
for (auto& ch : s1)
{
cout << ch << " ";
}
cout << endl;
for (auto ch : s1)
{
// 改变的只是ch,s1并没有改变
ch += 1;
cout << ch << " ";
}
cout << endl;
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
}
int main()
{
try
{
test_string5();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}

const对象
不修改成员变量的成员函数尽量都用const修饰,例如size()
// 函数内部不改变成员变量尽量都加上const修饰
// 普通对象可以调用,const对象也可以调用
// 其实就是size_t size(const string* this)
size_t size() const
{
return _size;
}
而像operator[]本身是会修改成员变量的,没法加const修饰,因此只能另外写一个const版本的重载函数。
char& operator[](size_t pos)
{
assert(pos < strlen(_str));
return _str[pos];
}
// 提供给const对象调用的,返回的是const引用,不能修改了
const char& operator[](size_t pos) const
{
assert(pos < strlen(_str));
return _str[pos];
}
// 传引用减少拷贝,不改变对象就尽量加上const
void func(const yzq::string& s)
{
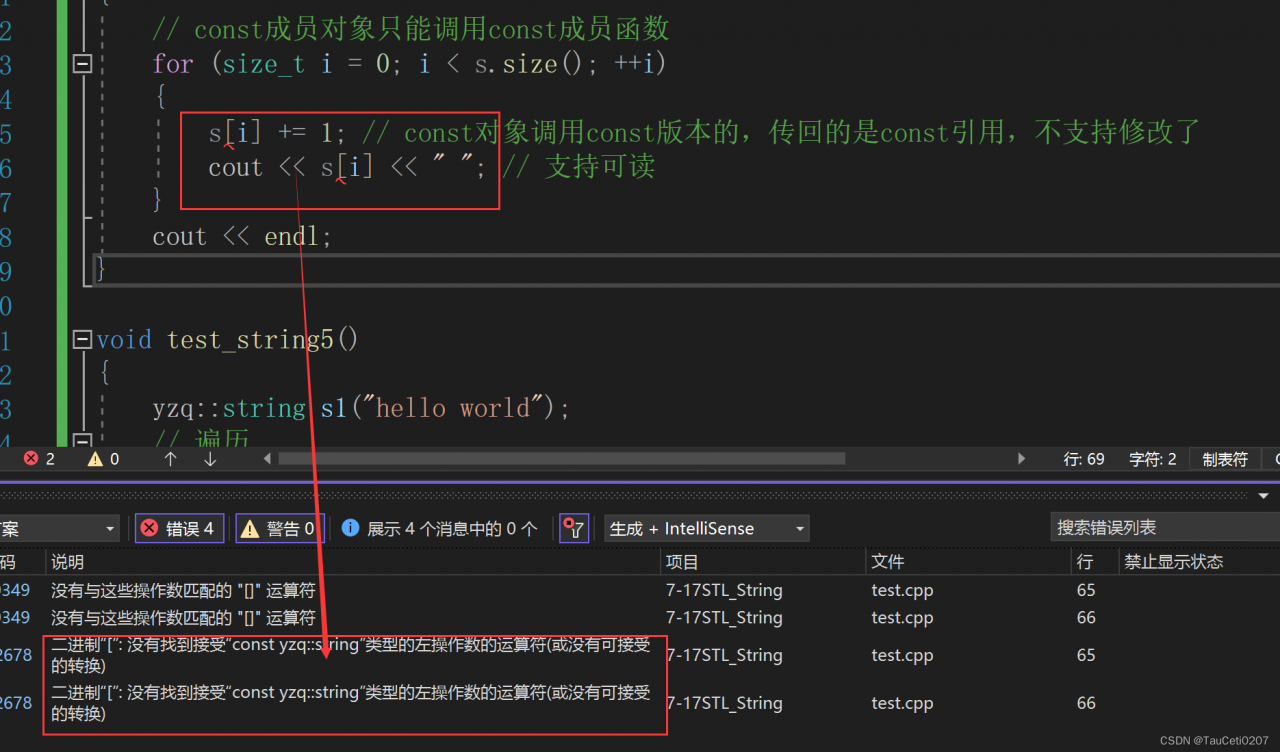
// const成员对象只能调用const成员函数
for (size_t i = 0; i < s.size(); ++i)
{
//s[i] += 1; // const对象调用const版本的,传回的是const引用,不支持修改了
cout << s[i] << " "; // 支持可读
}
cout << endl;
}
void test_string6()
{
yzq::string s1("hello world");
func(s1);
}
int main()
{
try
{
test_string6();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
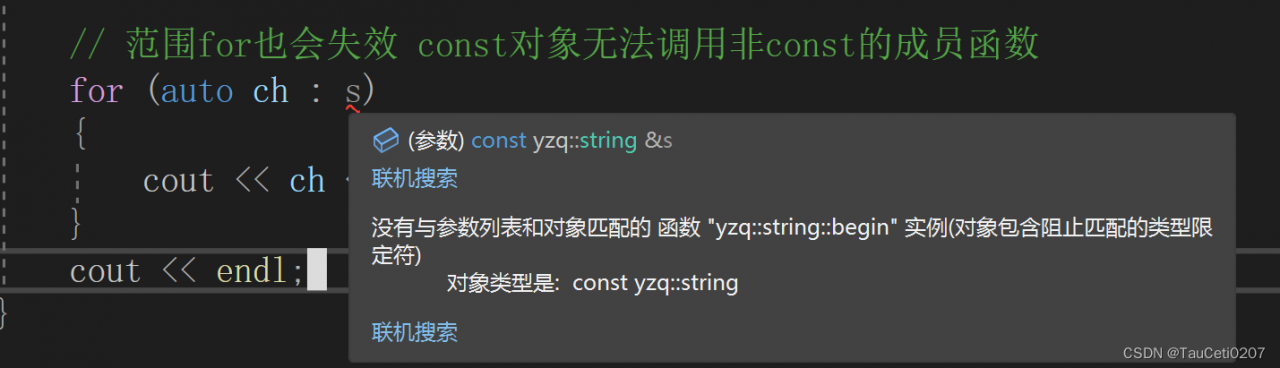
注意:范围for也会失效的。
s是const对象,去调用了非const的begin函数和end函数
因此需要提供一个const版本的迭代器。
如果仅仅提供这样的:?
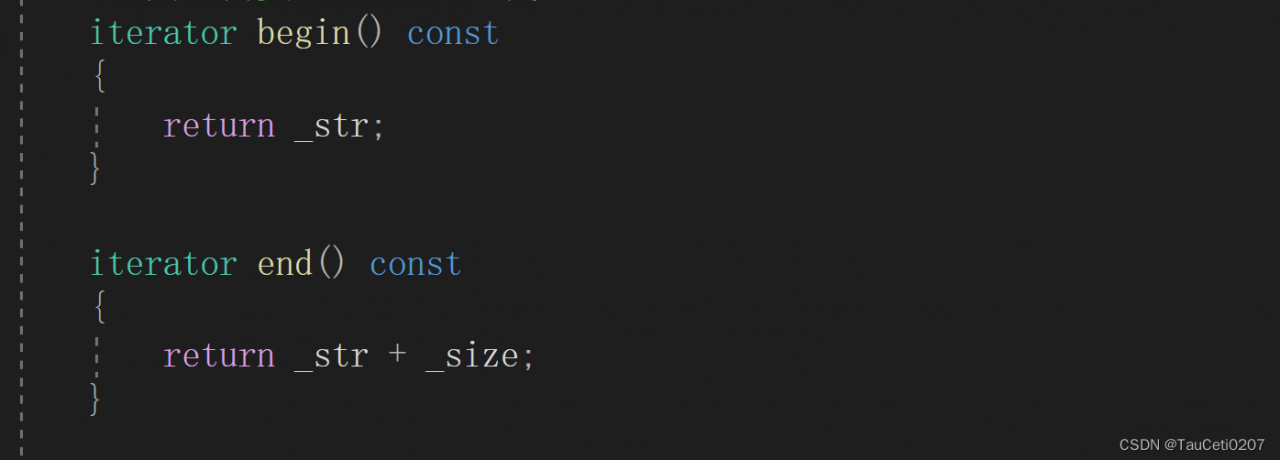
返回的iterator本质是char* 依旧能修改const对象,不满足要求。
因此需要一个额外的const迭代器。
// string的迭代器其实就是指针
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
// 提供一个const版本的迭代器,注意需要返回const char*
// 因此需要也跟const迭代器
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
void func(const yzq::string& s)
{
// const成员对象只能调用const成员函数
for (size_t i = 0; i < s.size(); ++i)
{
//s[i] += 1; // const对象调用const版本的,传回的是const引用,不支持修改了
cout << s[i] << " "; // 支持可读
}
cout << endl;
// 范围for也会失效 const对象无法调用非const的成员函数
for (auto ch : s)
{
cout << ch << " ";
}
cout << endl;
yzq::string::const_iterator it = s.begin();
while (it != s.end())
{
//*it -= 1;
cout << *it << " ";
++it;
}
cout << endl;
}
void test_string6()
{
yzq::string s1("hello world");
func(s1);
}
int main()
{
try
{
test_string6();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
insert
插入单个字符
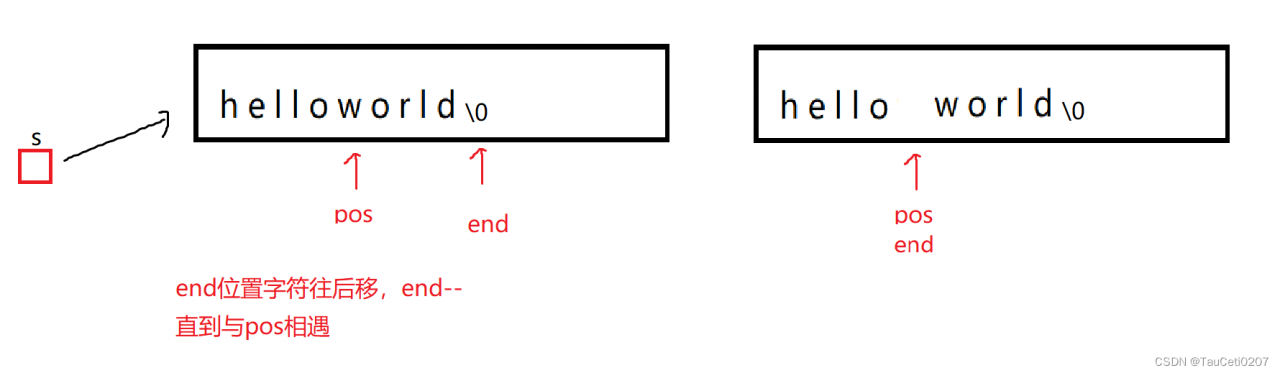
string& insert(size_t pos, char ch)
{
assert(pos <= _size);// =size的时候就是尾插
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size;
while (end >= pos)
{
_str[end + 1] = _str[end];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
这样写的话,头插又会出现问题,end是size_t类型,也就是unsigned int,始终大于等于0,且end减到0之后,再–会变成很大的数,会产生越界。
可以考虑将end和pos都强转成int:
这样就没问题了,但是写法太挫了。
可以考虑让end指向\0的下一个位置。
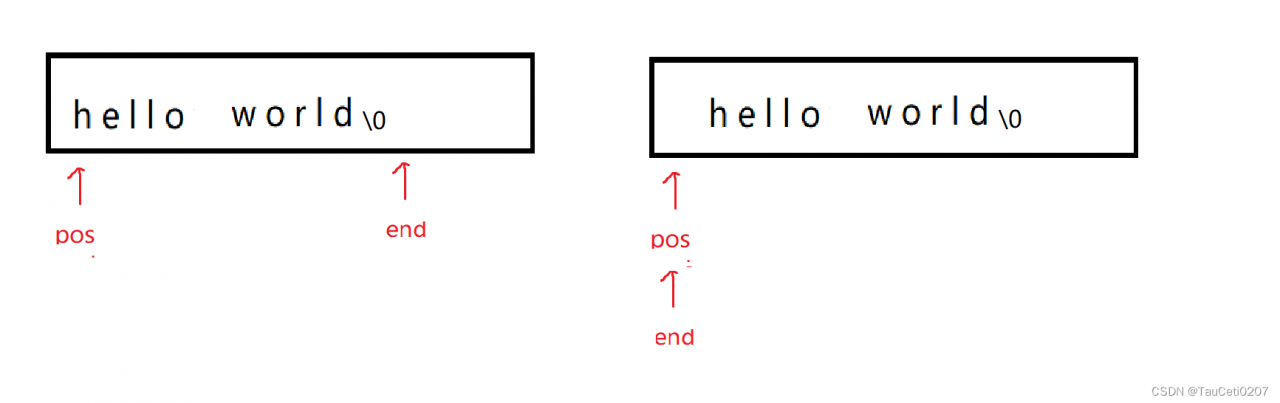
string& insert(size_t pos, char ch)
{
assert(pos <= _size);// =size的时候就是尾插
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end-1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
void test_string7()
{
yzq::string s1("hello world");
s1.insert(6, 'w');
cout << s1.c_str() << endl;
s1.insert(12, 'w');
cout << s1.c_str() << endl;
s1.insert(0, 'w');
cout << s1.c_str() << endl;
}
同样,push_back也可以复用insert来实现。
void push_back2(char ch)
{
insert(_size, ch);
}
void test_string7()
{
yzq::string s1("hello world");
s1.insert(6, 'w');
cout << s1.c_str() << endl;
s1.insert(12, 'w');
cout << s1.c_str() << endl;
s1.insert(0, 'w');
cout << s1.c_str() << endl;
s1.push_back2('a');
cout << s1.c_str() << endl;
s1 += 's'; // +=复用的是push_back
cout << s1.c_str() << endl;
}
插入字符串
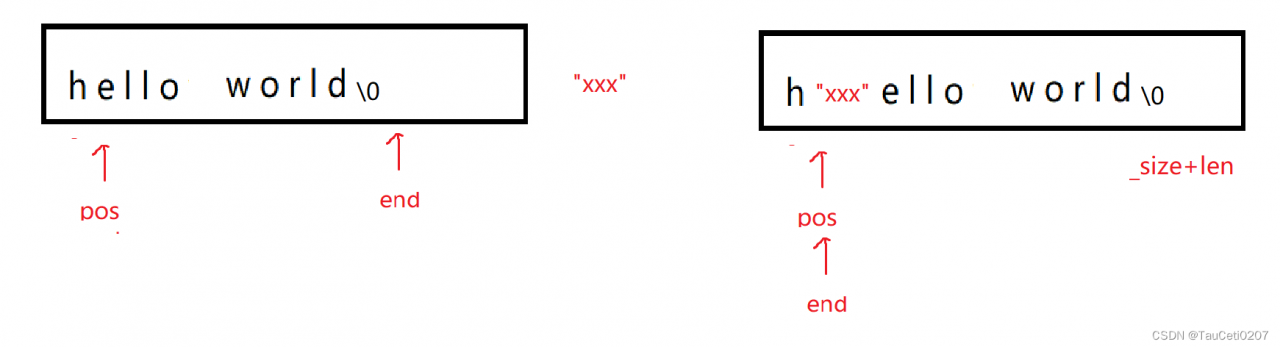
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + 1;
while (end > pos)
{
// _str[_size]就是\0的位置
_str[end + len - 1] = _str[end - 1];
--end;
}
// str拷贝进去
// 用strncpy也行,注意不能用stcpy,stcpy遇到\0就会停止的
//strncpy(_str + pos, str, len);
size_t tmp = len;
while (tmp--)
{
_str[pos] = *str;
++pos, ++str;
}
_size += len;
return *this;
}
void test_string7()
{
yzq::string s1("hello world");
s1.insert(6, 'w');
cout << s1.c_str() << endl;
s1.insert(12, 'w');
cout << s1.c_str() << endl;
s1.insert(0, 'w');
cout << s1.c_str() << endl;
s1.push_back2('a');
cout << s1.c_str() << endl;
s1 += 's'; // +=复用的是push_back
cout << s1.c_str() << endl;
cout << "-------------------------" << endl;
yzq::string s2("hello world");
cout << s2.c_str() << endl;
s2.insert(1, "xxx");
cout << s2.c_str() << endl;
s2.insert(0, "xxx");
cout << s2.c_str() << endl;
s2.insert(3, "11111");
cout << s2.c_str() << endl;
s2.insert(0, " ");
cout << s2.c_str() << endl;
}
注意:
insert效率比较低,如果要大量使用,还不如用尾插+逆置。
erase
考虑只删除部分:

完全删除:

string& erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
// len过长自己清楚,加上\0就行
if (len == npos || len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t begin = pos + len;
while (begin <= _size)
{
_str[begin - len] = _str[begin];
++begin;
}
_size -= len;
}
return *this;
}
npos的定义:

operator<<
void test_string9()
{
// 库里面的string \0虽然不可见,但是会占用位置
// 不过这个版本下的,似乎把\0占用位置给优化了
std::string s1("hello world");
cout << s1 << endl;
cout << s1.c_str() << endl;
s1 += '\0';
s1 += '\0';
s1 += '\0';
s1 += 'x';
s1 += '\0';
s1 += '\0';
s1 += 'x';
cout << s1 << endl;
// 库里的cstr识别到\0就终止了
cout << s1.c_str() << endl;
}
ostream& operator<<(ostream& out, const string& s)
{
//out << s.c_str() << endl; // 这种不行,无法体现\0的存在 遇到\0就终止了
for (auto ch : s)
{
out << ch;
}
return out;
}
void test_string10()
{
yzq::string s1("hello world");
cout << s1 << endl;
cout << s1.c_str() << endl;
s1 += '\0';
s1 += '\0';
s1 += '\0';
s1 += 'x';
cout << s1 << endl;
cout << s1.c_str() << endl;
}
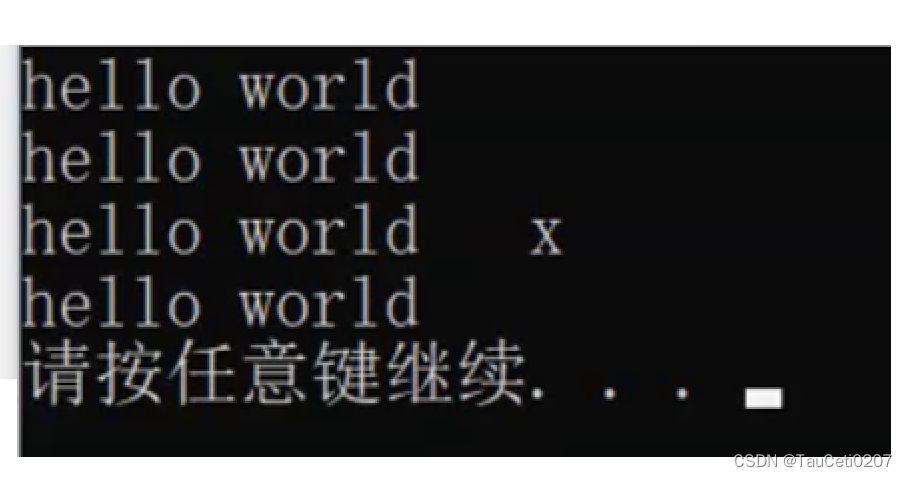
operator>>
cin是读取不了空格或者换行的,在字符串最后一个单词的长度我们也验证过了。
因此需要借助istream中的
get()

istream& operator>>(istream& in, string& s)
{
char ch;
//in >> ch; // cin是获取不了空格或者换行符的,因此会死循环
ch = in.get(); // 一个一个去缓冲区获取字符
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
上述写法频繁+=,会频繁扩容降低效率
利用buff优化一下
istream& operator>>(istream& in, string& s)
{
char ch;
ch = in.get(); // 一个一个去缓冲区获取字符
char buff[128] = { '\0' }; // 优化区间
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
// 继续加上未填满的buff
s += buff;
return in;
}
void test_string10()
{
yzq::string s1("hello world");
cout << s1 << endl;
cout << s1.c_str() << endl;
s1 += '\0';
s1 += '\0';
s1 += '\0';
s1 += 'x';
s1 += '\0';
s1 += '\0';
s1 += 'x';
cout << s1 << endl;
cout << s1.c_str() << endl;
yzq::string s2, s3, s4;
cin >> s2 >> s3 >> s4;
cout << s2 << "-" << s3 << "-" << s4 << endl;
}
int main()
{
try
{
test_string10();
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
测试时发现,还是存在一点bug的。
void test_string11()
{
yzq::string s1("hello world");
cin >> s1;
cout << s1 << endl;
std::string s2("hello world");
cin >> s2;
cout << s2 << endl;
}
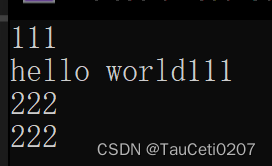
由结果可知,std库里的cin在插入之前会清空s的内容。
因此我们在流提取之前也需要清空一下string对象的内容。
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get(); // 一个一个去缓冲区获取字符
char buff[128] = { '\0' };
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
// 继续加上未填满的buff
s += buff;
return in;
}

getline
遇到换行才停。
istream& getline(istream& in, string& s)
{
//其实和operator>>类似,只是遇到空格不结束罢了
s.clear();
char ch;
ch = in.get(); // 一个一个去缓冲区获取字符
char buff[128] = { '\0' };
size_t i = 0;
while (ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
// 继续加上未填满的buff
s += buff;
return in;
}
void test_string12()
{
yzq::string s3("hello world");
yzq::getline(cin, s3);
cout << s3 << endl;
}

源代码
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <assert.h>
#include <string>
using namespace std;
namespace yzq
{
class string
{
public:
// string的迭代器其实就是指针
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
// 提供一个const版本的迭代器,注意需要返回const char*
// 因此需要也跟const迭代器
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
//提供无参的比较冗余,不如提供一个全缺省
//string为空时,是一个" "
/*string()
:_size(0)
,_capacity(0)
{
_str = new char[1];
_str[0] = '\0';
}*/
// ""是默认常量字符串,后面存在有\0
// "\0" 这样写也是ok的 只不过这样是有2个\0了
// '\0' 这个字符的ASCII码是0,类型不匹配
string(const char* str = "")
// 初始化列表的初始化顺序和成员变量声明顺序一致
:_size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1]; // +1是为\0开的空间
strcpy(_str, str);
}
// s2(s1) s1传给s,s2传给this指针
// 注意避免多次调用strlen,O(N)的复杂度
// 传统写法深拷贝
/*string(const string& s)
:_size(strlen(s._str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, s._str);
}*/
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
// 传统写法的拷贝构造深拷贝,老老实实去干活,该开空间就开空间,该拷贝数据就拷贝数据
// 现代写法:一种剥削行为,安排别人去干活
string(const string& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
// 就是去利用传过来的s的_str去构造新的tmp
// 但是tmp是个临时对象,出作用域时会销毁
// 而swap过去的指针是随机值,delete时可能会崩溃
// 因此自身的成员变量最好初始化一下
string tmp(s._str);
/*
swap(_str, tmp._str);
swap(_size, tmp._size);
swap(_capacity, tmp._capacity);
*/
// 利用自己写的swap函数
swap(tmp);
}
/*
// s1 = s3 也就是s1.operator=(&s1, s3)
string& operator=(const string& s)
{
if (this != &s) // 避免自己赋值给自己
{
//万一开空间失败了,s1却已经被释放了
//delete[] _str;//释放s1的空间
//_str = nullptr;
//_str = new char[strlen(s._str) + 1];// 开辟和s3一样大的空间
//strcpy(_str, s._str);
// 先开空间比较合适
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this; // 为了支持连续赋值,返回左操作数
}
*/
// 赋值重载现代写法1 s3 = s1
/*
string& operator=(const string& s)
{
if (this != &s)
{
string tmp(s._str);
swap(tmp);
}
return *this;
}
*/
// 现代写法2 更加剥削 s3 = s1
// s1传过来直接就是拷贝构造 拷贝构造完成深拷贝后 再直接交换
string& operator=(string s)
{
swap(s);
return *this;
}
~string()
{
if (_str)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}
const char* c_str() const
{
return _str;
}
// 返回引用为了支持修改,也能减少拷贝
char& operator[](size_t pos)
{
//assert(pos < strlen(_str));
assert(pos < _size);
return _str[pos];
}
// 提供给const对象调用的,返回的是const引用,不能修改了
const char& operator[](size_t pos) const
{
assert(pos < strlen(_str));
return _str[pos];
}
// 函数内部不改变成员变量尽量都加上const修饰
// 普通对象可以调用,const对象也可以调用
// 其实就是 size_t size(const string* this)
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
// 仅对capacity处理
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1]; // 留一个空间给\0
strcpy(tmp, _str);
delete[] _str; // 清理旧空间
_str = tmp; // 指向新空间
_capacity = n;
}
}
// resize主要用于扩空间+初始化、删除部分数据保留前n个
// 考虑3种情况
void resize(size_t n, char ch = '\0')
{
// 1.n小于size,直接修改size并添加\0
if (n < _size)
{
_size = n;
_str[_size] = '\0';
}
else
{
// 2.n大于capacity,扩容后在末尾添加ch,注意最后放\0
if (n > _capacity)
{
reserve(n);
}
// 3.n小于capacity且n大于size,直接挨个赋值就行
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
void push_back(char ch)
{
if (_size == _capacity)
{
//reserve(_capacity * 2); // 会崩溃
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
// 注意处理\0
++_size;
_str[_size] = '\0';
}
void push_back2(char ch)
{
insert(_size, ch);
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
// append要考虑2倍空间也可能不够的问题
void append(const char* str)
{
size_t len = _size + strlen(str);
if (len > _capacity)
{
reserve(len);
}
// 直接拷贝到后面
strcpy(_str + _size, str);
_size = len;
// 也可以复用insert
//insert(_size, str);
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);// =size的时候就是尾插
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
/* 这样也行的,就是比较挫
size_t end = _size;
while ((int)end >= (int)pos)
{
_str[end + 1] = _str[end];
--end;
}
*/
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + 1;
while (end > pos)
{
// 一次性挪动len个位置
// _str[_size]就是\0的位置
_str[end + len - 1] = _str[end - 1];
--end;
}
// str拷贝进去
// 用strncpy也行,注意不能用stcpy,stcpy遇到\0就会停止的
//strncpy(_str + pos, str, len);
size_t tmp = len;
while (tmp--)
{
_str[pos] = *str;
++pos, ++str;
}
_size += len;
return *this;
}
string& erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
// len过长自己清楚,加上\0就行
if (len == npos || len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t begin = pos + len;
while (begin <= _size)
{
_str[begin - len] = _str[begin];
++begin;
}
_size -= len;
}
return *this;
}
size_t find(char ch, size_t pos = 0)
{
for (; pos < _size; ++pos)
{
if (_str[pos] == ch)
{
return pos;
}
}
// 找不到
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
// KMP在实际中并不实用,BM用的才比较多
const char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
// 指针相减返回的才是需要的下标
return p - _str;
}
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
private:
char* _str;
size_t _size;// 有效字符个数
size_t _capacity;// 实际存储有效字符空间
// \0不算有效字符
const static size_t npos;
};
// 静态成员变量类内声明,类外定义
const size_t string::npos = -1;
ostream& operator<<(ostream& out, const string& s)
{
//out << s.c_str() << endl; // 这种不行,无法体现\0的存在 遇到\0就终止了
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
/*
char ch;
//in >> ch; // cin是获取不了空格或者换行符的,因此会死循环
ch = in.get(); // 一个一个去缓冲区获取字符
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
*/
// 上述写法频繁+=,会频繁扩容降低效率
// 利用buff优化一下
s.clear();
char ch;
ch = in.get(); // 一个一个去缓冲区获取字符
char buff[128] = { '\0' };
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
// 继续加上未填满的buff
s += buff;
return in;
}
istream& getline(istream& in, string& s)
{
//其实和operator>>类似,只是遇到空格不结束罢了
s.clear();
char ch;
ch = in.get(); // 一个一个去缓冲区获取字符
char buff[128] = { '\0' };
size_t i = 0;
while (ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
// 继续加上未填满的buff
s += buff;
return in;
}
// 直接调用c库里面的字符串比较函数来比,利用c_str写成全局函数
bool operator<(const string& s1, const string& s2)
{
// strcmp 返回值小于0表示的就是s1 < s2
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 < s2);
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}
}
尾声
???
写文不易,如果有帮助烦请点个赞~ ???
Thanks♪(・ω・)ノ???
???
??由于笔者水平有限,在今后的博文中难免会出现错误之处,本人非常希望您如果发现错误,恳请留言批评斧正,希望和大家一起学习,一起进步ヽ( ̄ω ̄( ̄ω ̄〃)ゝ,期待您的留言评论。
附GitHub仓库链接