
Mysql到Elasticsearch的数据同步,一般用ETL来实现,但性能并不理想,目前大部分的ETL是定时查询Mysql数据库有没有新增数据或者修改数据,如果数据量小影响不大,但如果几百万上千万的数据量性能就明显的下降很多,本文是使用Go实现的go-mysql-transfer中间件来实时监控Mysql的Binlog日志,然后同步到Elasticsearch,从实时性、性能效果都不错。
一、go-mysql-transfer
go-mysql-transfer是使用Go语言实现的MySQL数据库实时增量同步工具。能够实时监听MySQL二进制日志(binlog)的变动,将变更内容形成指定格式的消息,发送到接收端。在数据库和接收端之间形成一个高性能、低延迟的增量数据(Binlog)同步管道, 具有如下特点:
1、不依赖其它组件,一键部署
2、集成多种接收端,如:Redis、MongoDB、Elasticsearch、RabbitMQ、Kafka、RocketMQ,不需要再编写客户端,开箱即用
3、内置丰富的数据解析、消息生成规则;支持Lua脚本,以处理更复杂的数据逻辑
4、支持监控告警,集成Prometheus客户端
5、高可用集群部署
6、数据同步失败重试
7、全量数据初始化
详情及安装说明 请参见: MySQL Binlog 增量同步工具go-mysql-transfer实现详解
项目开源地址:go-mysql-transfer
二、配置
# app.ymltarget: elasticsearch #目标类型#elasticsearch连接配置es_addrs: 127.0.0.1:9200 #连接地址,多个用逗号分隔es_version: 7 # Elasticsearch版本,支持6和7、默认为7#es_password: # 用户名#es_version: # 密码三、数据转换规则
相关配置如下:
rule: - schema: eseap #数据库名称 table: t_user #表名称 #order_by_column: id #排序字段,存量数据同步时不能为空 #column_lower_case: true #列名称转为小写,默认为false #column_upper_case:false#列名称转为大写,默认为false column_underscore_to_camel: true #列名称下划线转驼峰,默认为false # 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列 #include_columns: ID,USER_NAME,PASSWORD #exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空 #default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥 #date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd #datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss #Elasticsearch相关 es_index: user_index #Index名称,可以为空,默认使用表(Table)名称 #es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导 # - # column: REMARK #数据库列名称 # field: remark #映射后的ES字段名称 # type: text #ES字段类型 # analyzer: ik_smart #ES分词器,type为text此项有意义 # #format: #日期格式,type为date此项有意义 # - # column: USER_NAME #数据库列名称 # field: account #映射后的ES字段名称 # type: keyword #ES字段类型示例一
t_user表,数据如下:

自动创建的Mapping,如下:
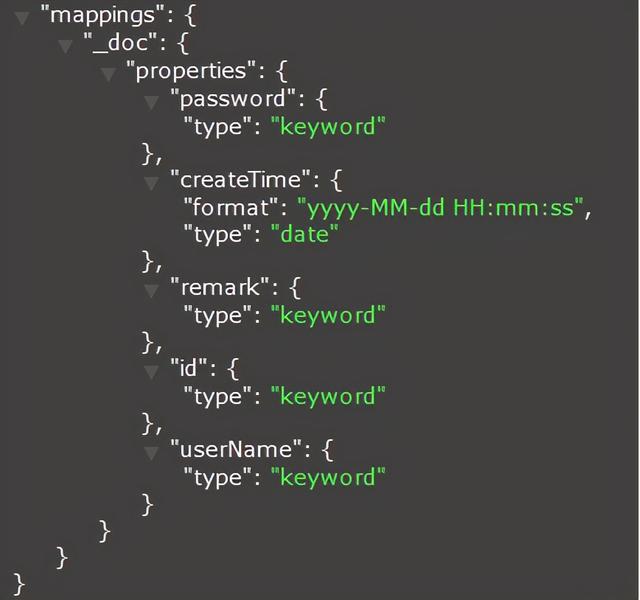
同步到Elasticsearch的数据如下:

示例二
t_user表,同实例一
使用如下配置:
rule: - schema: eseap #数据库名称 table: t_user #表名称 order_by_column: id #排序字段,存量数据同步时不能为空 column_lower_case: true #列名称转为小写,默认为false #column_upper_case:false#列名称转为大写,默认为false #column_underscore_to_camel: true #列名称下划线转驼峰,默认为false # 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列 #include_columns: ID,USER_NAME,PASSWORD #exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空 default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥 #date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd #datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss #Elasticsearch相关 es_index: user_index #Index名称,可以为空,默认使用表(Table)名称 es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导 - column: REMARK #数据库列名称 field: remark #映射后的ES字段名称 type: text #ES字段类型 analyzer: ik_smart #ES分词器,type为text此项有意义 #format: #日期格式,type为date此项有意义 - column: USER_NAME #数据库列名称 field: account #映射后的ES字段名称 type: keyword #ES字段类型es_mappings 定义索引的mappings(映射关系),不定义es_mappings则使用列类型自动创建索引的mappings(映射关系)。
自动创建的Mapping,如下:

同步到Elasticsearch的数据如下:

四、Lua脚本
使用Lua脚本可以实现更复杂的数据处理逻辑,go-mysql-transfer支持Lua5.1语法。
示例一
t_user表,数据如下:

引入Lua脚本:
#规则配置 rule: - schema: eseap #数据库名称 table: t_user #表名称 order_by_column: id #排序字段,存量数据同步时不能为空 lua_file_path: lua/t_user_es.lua #lua脚本文件 es_index: user_index #Elasticsearch Index名称,可以为空,默认使用表(Table)名称 es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导 - field: id #映射后的ES字段名称 type: keyword #ES字段类型 - field: userName #映射后的ES字段名称 type: keyword #ES字段类型 - field: password #映射后的ES字段名称 type: keyword #ES字段类型 - field: createTime #映射后的ES字段名称 type: date #ES字段类型 format: yyyy-MM-dd HH:mm:ss #日期格式,type为date此项有意义 - field: remark #映射后的ES字段名称 type: text #ES字段类型 analyzer: ik_smart #ES分词器,type为text此项有意义 - field: source #映射后的ES字段名称 type: keyword #ES字段类型es_mappings 定义索引的mappings(映射关系),不定义es_mappings则根据字段的值自动创建mappings(映射关系)。根据es_mappings 生成的mappings如下:

user_index索引mappings
Lua脚本:
local ops = require("esOps") --加载elasticsearch操作模块local row = ops.rawRow() --当前数据库的一行数据,table类型,key为列名称local action = ops.rawAction() --当前数据库事件,包括:insert、update、deletelocal id = row["ID"] --获取ID列的值local userName = row["USER_NAME"] --获取USER_NAME列的值local password = row["PASSWORD"] --获取USER_NAME列的值local createTime = row["CREATE_TIME"] --获取CREATE_TIME列的值local remark = row["REMARK"] --获取REMARK列的值local result = {} -- 定义一个table,作为结果集result["id"] = idresult["userName"] = userNameresult["password"] = passwordresult["createTime"] = createTimeresult["remark"] = remarkresult["source"] = "binlog" -- 数据来源if action == "insert" then -- 只监听新增事件 ops.INSERT("t_user",id,result) -- 新增,参数1为index名称,string类型;参数2为要插入的数据主键;参数3为要插入的数据,tablele类型或者json字符串end 同步到Elasticsearch的数据如下:
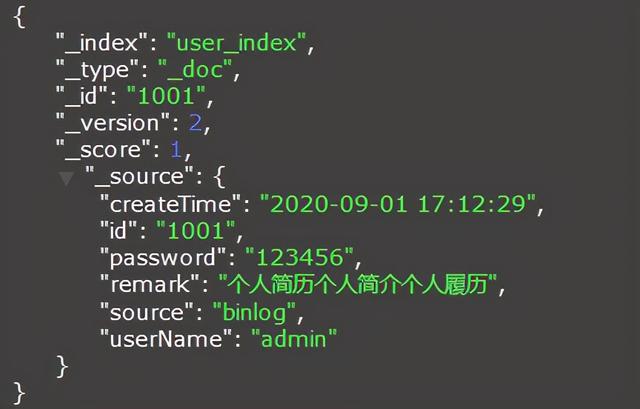
示例二
t_user表,同实例一
引入Lua脚本:
schema: eseap #数据库名称 table: t_user #表名称 lua_file_path: lua/t_user_es2.lua #lua脚本文件未明确定义index名称、mappings,es会根据值自动创建一个名为t_user的index。
使用如下脚本:
local ops = require("esOps") --加载elasticsearch操作模块local row = ops.rawRow() --当前数据库的一行数据,table类型,key为列名称local action = ops.rawAction() --当前数据库事件,包括:insert、update、deletelocal id = row["ID"] --获取ID列的值local userName = row["USER_NAME"] --获取USER_NAME列的值local password = row["PASSWORD"] --获取USER_NAME列的值local createTime = row["CREATE_TIME"] --获取CREATE_TIME列的值local result = {} -- 定义一个table,作为结果集result["id"] = idresult["userName"] = userNameresult["password"] = passwordresult["createTime"] = createTimeresult["remark"] = remarkresult["source"] = "binlog" -- 数据来源if action == "insert" then -- 只监听新增事件 ops.INSERT("t_user",id,result) -- 新增,参数1为index名称,string类型;参数2为要插入的数据主键;参数3为要插入的数据,tablele类型或者json字符串end 同步到Elasticsearch的数据如下:

esOps模块提供的方法如下:
- INSERT: 插入操作,如:ops.INSERT(index,id,result)。参数index为索引名称,字符串类型;参数index为要插入数据的主键;参数result为要插入的数据,可以为table类型或者json字符串
- UPDATE: 修改操作,如:ops.UPDATE(index,id,result)。参数index为索引名称,字符串类型;参数index为要修改数据的主键;参数result为要修改的数据,可以为table类型或者json字符串
- DELETE: 删除操作,如:ops.DELETE(index,id)。参数index为索引名称,字符串类型;参数id为要删除的数据主键,类型不限;
文章来源:https://www.jianshu.com/p/5a9b6c4f318c