点击上方关注,直达人工智能前沿!
如果你计划在python中学习数据分析,机器学习或数据科学工具,那么pandas库会是你的不二之选,Pandas是一个在python中操作和分析数据的开源库。
数据导入
练习数据导入最简单方法就是加载表(和excel文件),然后以多种方式对它们进行切片和切块:
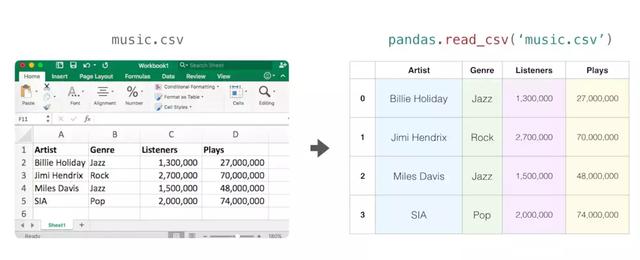
Pandas允许我们加载电子表格并在python中以编程方式对其进行操作。pandas中的中心概念是称为DataFrame的对象类型 —- —- 就是是一个表,每行和列都有一个标签。下面加载这个包含音乐流媒体服务数据的基本CSV文件:
df = pandas.read_csv('music.csv')现在变量df是一个pandas DataFrame:
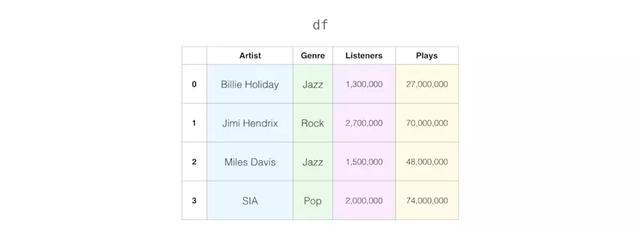
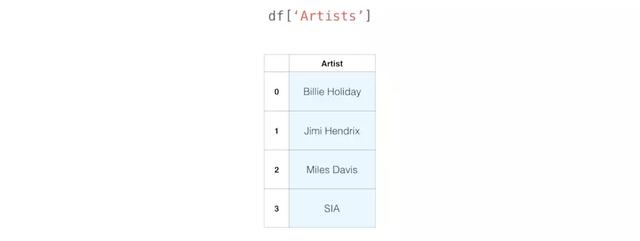
选择
可以使用其标签选择任何列:
可以通过数字索引选择一行或多行:
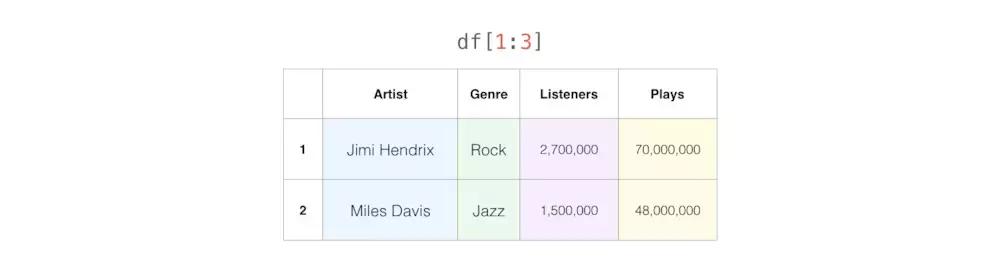
我们可以使用列标签和行号来选择表的任何切片loc(但这里它将包括两个边界行号):

过滤
可以使用特定行的值轻松过滤行。例如,过滤爵士音乐家Jazz:

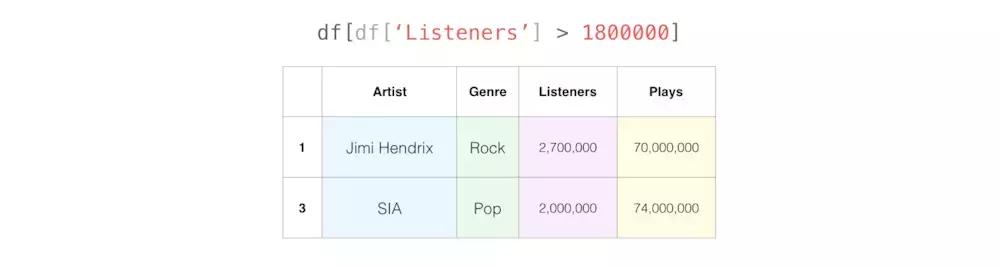
筛选拥有超过1,800,000名听众的艺术家:
处理缺失值
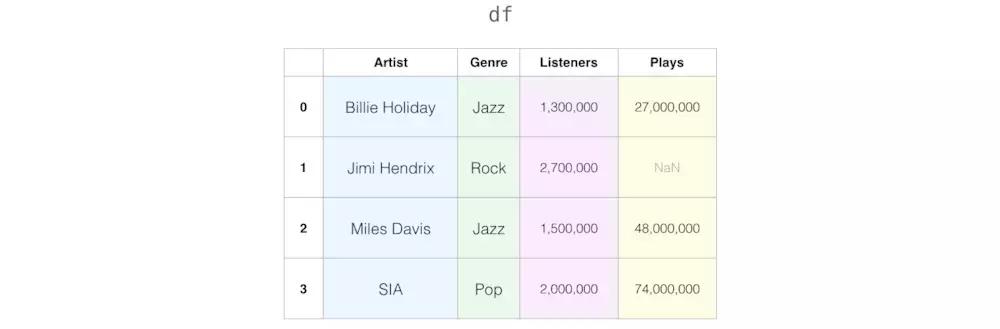
在数据科学中许多数据集都包含缺失值,如下:
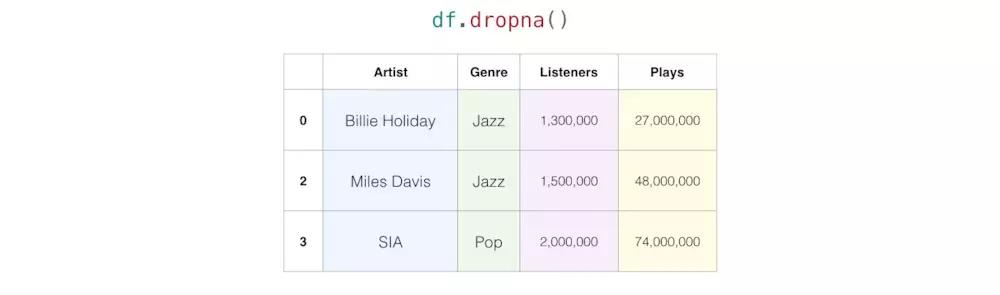
pandas提供了多种方法来解决这个问题。最简单的方法是删除缺少值的行:
另一种方法是使用fillna()(例如0)填充缺失值。
分组
使用特定条件对行进行分组并聚合其数据时,可以按类型对数据集进行分组,看看每种类型的音乐有多少听众和爱好者:
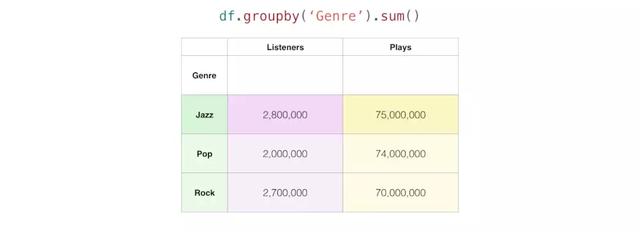
Pandas将上图中两个”Jazz”行组合成一个,通过sum()聚合,将Jazz的听众和爱好者加在一起,并显示总和。
通过groupby(),可以实现数据集的折叠并从中发现数据的规律,聚合也是统计学的基础工具之一。
除了sum(),Pandas还提供多种聚合功能,包括mean()计算平均值,min(),max()等多个其他功能。
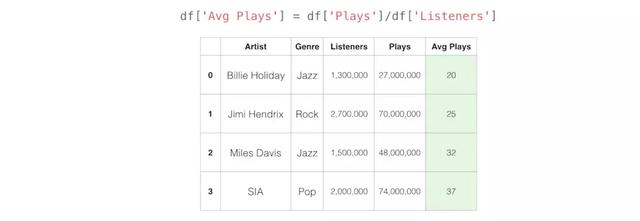
添加新列
通常在数据分析过程中,需要从现有列添加新列。这在Pandas里轻而易举。