•ajax可以使用网页实现异步更新,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
获取ajax数据的方式:
1.直接分析ajax调用的接口。然后通过代码请求这个接口。
2.使用Selenium+chromedriver模拟浏览器行为获取数据。
• selenium是一个web的自动化测试工具,最初是为网站自动化测试而开发的,selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏
• chromedriver是一个驱动Chrome浏览器的驱动程序,使用他才可以驱动浏览器。当然针对不同的浏览器有不同的driver。以下列出了不同浏览器及其对应的driver:
• Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads
• Firefox:https://github.com/mozilla/geckodriver/releases
• Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
• Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
一、定位元素(以定位输入框为例)
1、通过Id来定位
driver.find_element_by_id(‘kw’).send_keys(‘python’)
或者
driver.find_element(By.ID,‘kw’).send_keys(‘python’)
2、通过class name来定位
driver.find_element_by_class_name(‘s_ipt’).send_keys(‘python’)
或者
driver.find_element(By.CLASS_NAME,‘s_ipt’).send_keys(‘python’)
3、通过name 来定位
driver.find_element_by_name(‘wd’).send_keys(‘python’)
或者
driver.find_element(By.NAME,‘wd’).send_keys(‘python’)
4、通过xpath定位
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python')
其中,括号中的'//*[@id="kw"]'是用如下方法得到的,并不需要手写: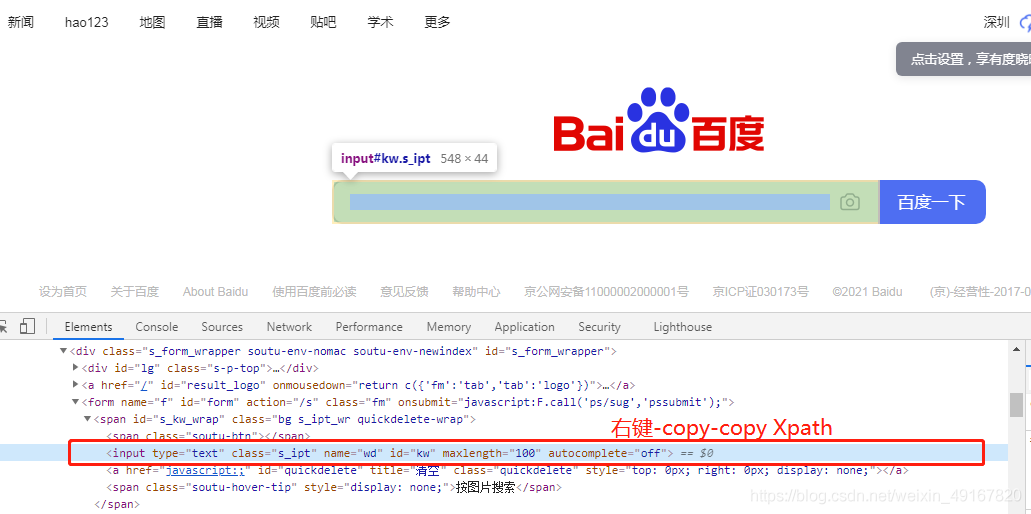
鼠标移动到红框处时,我们看到定位到了输入框;在红框处右键-copy-copy Xpath(右键确认),再粘贴到括号中即可。
5、通过标签的名字
head = driver.find_element_by_tag_name(‘head’)
print(head)
6、找多个
find_elements_by_tag_name(其他同理,就是用elements替换element)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome(r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe')
driver.get('https://www.baidu.com/')
inputTag = driver.find_elements_by_tag_name('input')
print(len(inputTag),inputTag)
结果: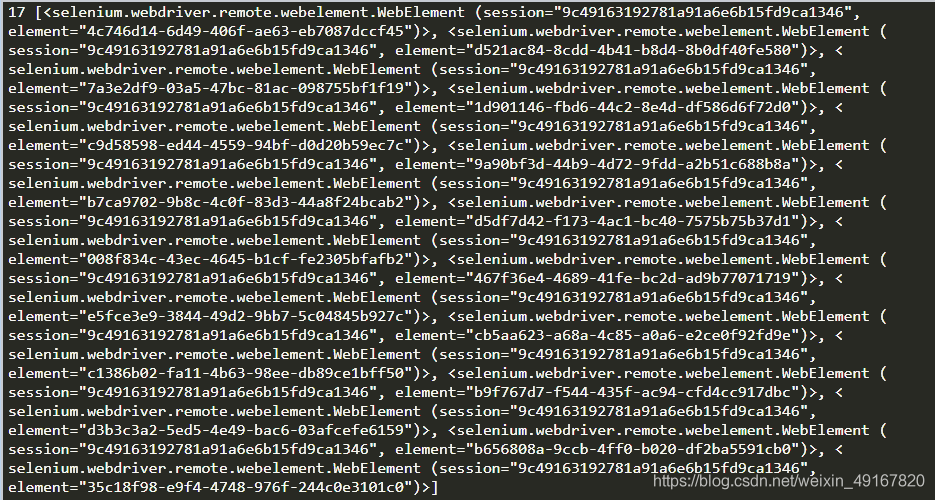
要注意,find_element是获取第一个满足条件的元素。find_elements是获取所有满足条件的元素,返回的是一个列表。
二、操作元素
1、操作输入框:分为两步。
第一步:找到这个元素。(定位元素)
第二步:使用send_keys(value),将数据填充进去。
(使用clear方法可以清除输入框中的内容)
2、 操作按钮
操作按钮有很多种方式。比如单击、右击、双击等。这里讲一个最常用的单击。直接调用click函数就可以了。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
time.sleep(2)
# inputTag.clear() # 清空内容
button = driver.find_element_by_id('su')
button.click()
3、选择select标签(下拉菜单)
select元素不能直接点击。因为点击后还需要选中元素。这时候selenium就专门为select标签提供了一个类from selenium.webdriver.support.ui import Select。将获取到的元素当成参数传到这个类中,创建这个对象。以后就可以使用这个对象进行选择了。
以网站https://www.17sucai.com/pins/demo-show?id=5926为例。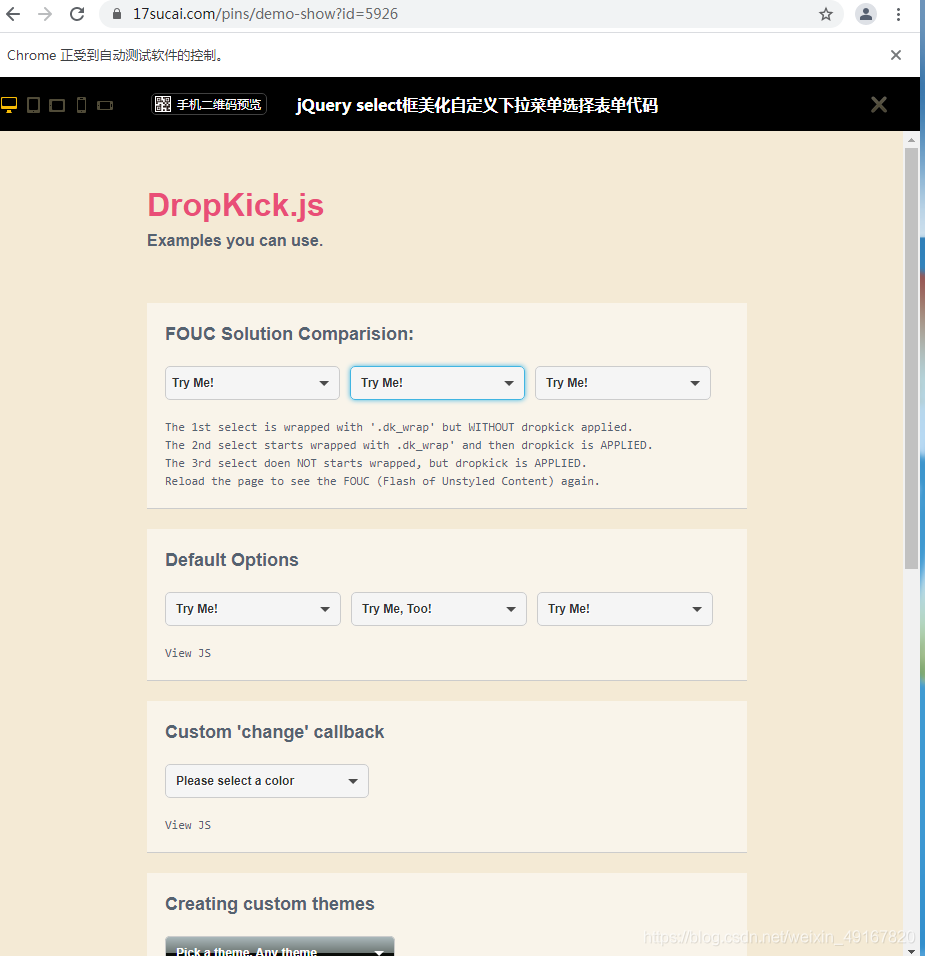
(1)怎么知道是select元素:
(2)选择方式,有两种:
1 是根据值来选择
selectTag.select_by_value(‘JP’)
2 是根据索引来选择(也就是下拉列表中排第几个,默认从0开始)
selectTag.select_by_index(4)
(上图红框处,JP是排在第5个)
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://www.17sucai.com/pins/demo-show?id=5926')
selectTag = Select(driver.find_element_by_class_name('nojs'))
selectTag.select_by_value('JP')
结果: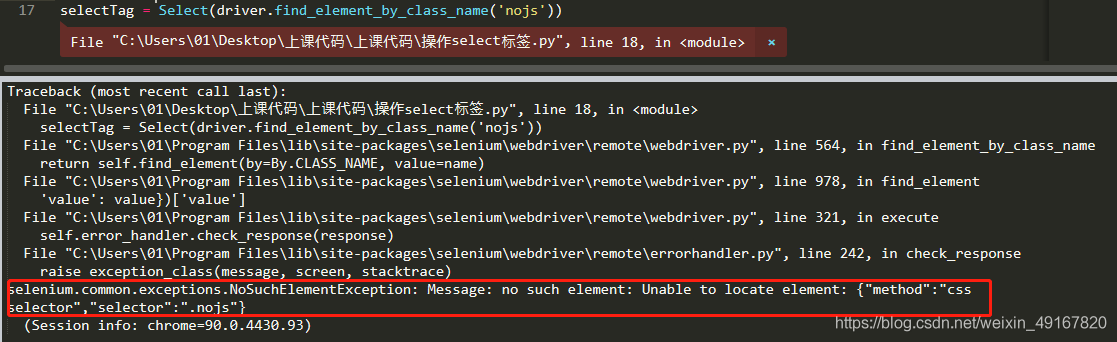
报错说没有这个元素,但实际我们又能看到这个元素。
我们注意到,上面有个iframe标签: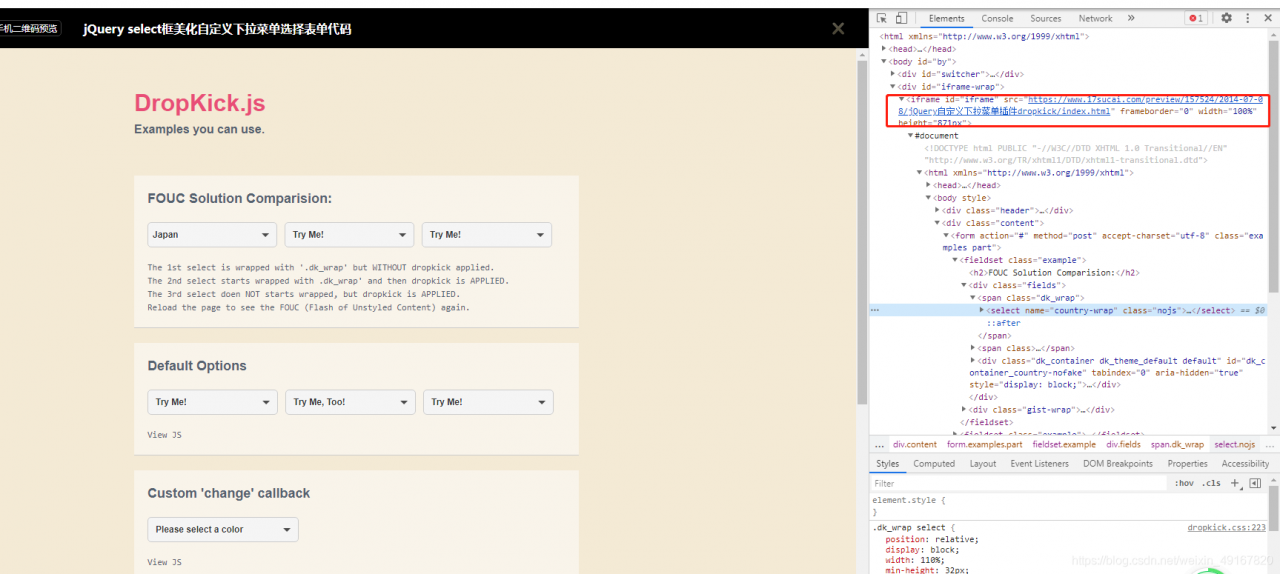
我们打开红框处的src地址,可以发现新的网页和当前的网页一模一样。
这里补充下关于iframe标签的知识点:
iframe 是HTML的标签 作用:文档中的文档 所以如果有ifram标签 而这个标签里面嵌套的内容正好就有你要操纵的元素,此时此刻就需要先切换iframe。
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://www.17sucai.com/pins/demo-show?id=5926')
# 切换iframe :driver.switch_to.frame()
driver.switch_to.frame(driver.find_element_by_id('iframe'))
# select标签
selectTag = Select(driver.find_element_by_class_name('nojs'))
selectTag.select_by_value('JP')
结果: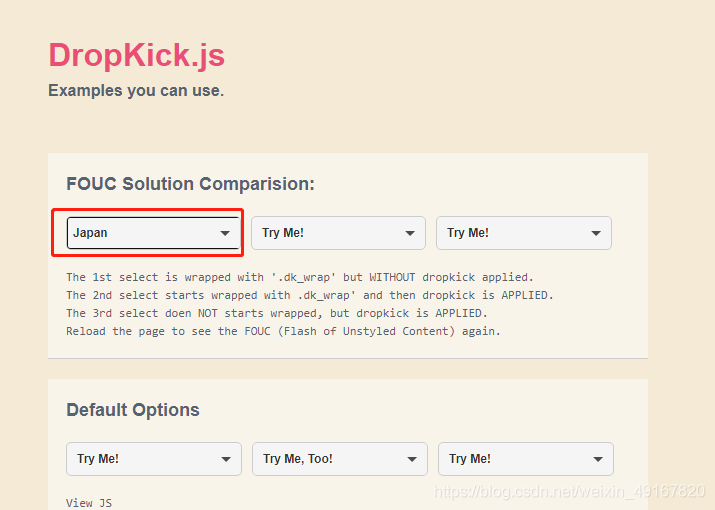
4、选择非select标签(下拉菜单)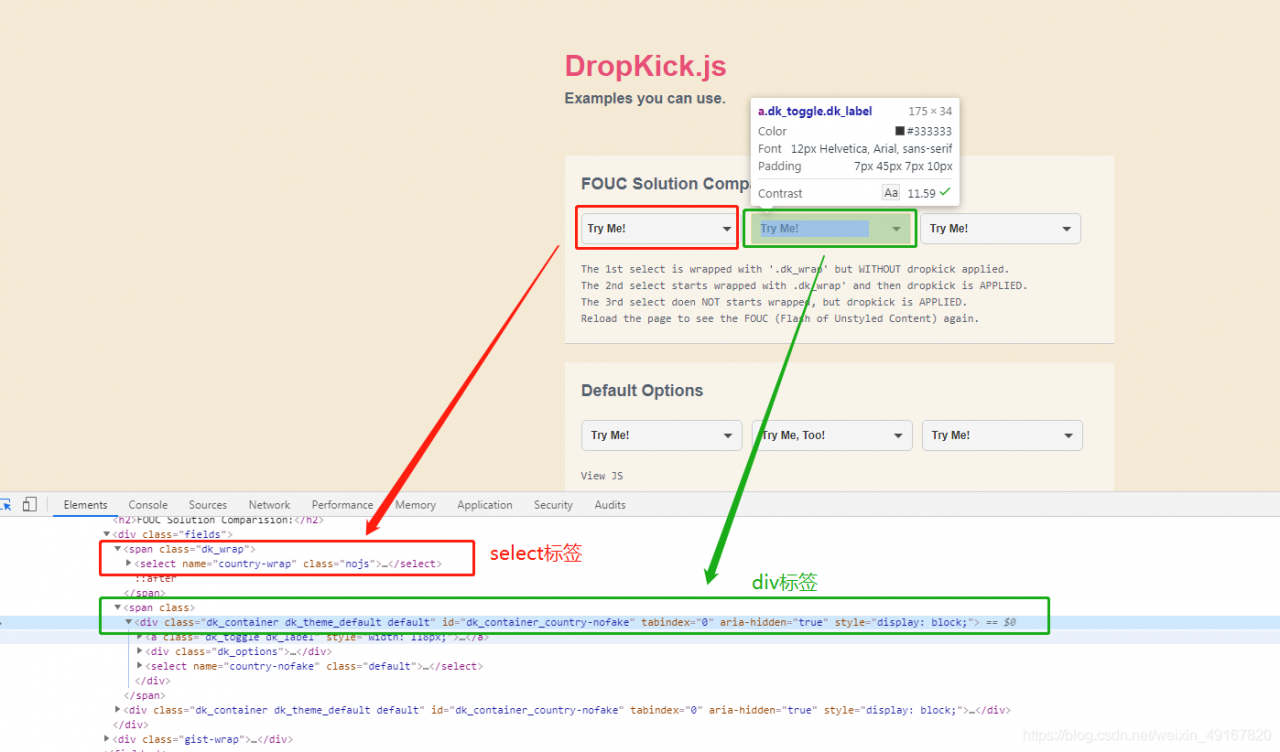
如上图,绿色框处,是一个div标签,也是下拉菜单的表现形式。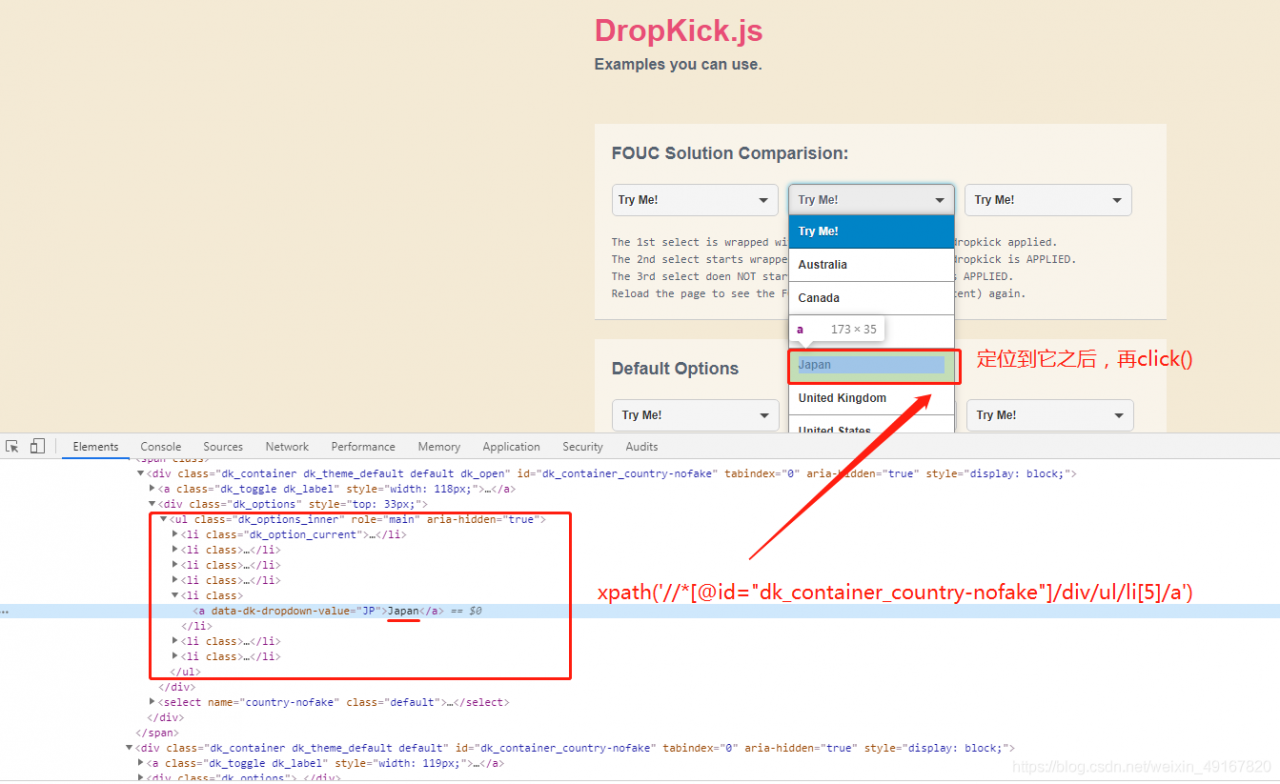
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://www.17sucai.com/pins/demo-show?id=5926')
# 切换iframe
driver.switch_to.frame(driver.find_element_by_id('iframe'))
divTag = driver.find_element_by_id('dk_container_country-nofake')
divTag.click()
driver.find_element_by_xpath('//*[@id="dk_container_country-nofake"]/div/ul/li[5]/a').click()
结果:(体会下,上述代码中的click(),实际上就是我们手动操作网页的点击。)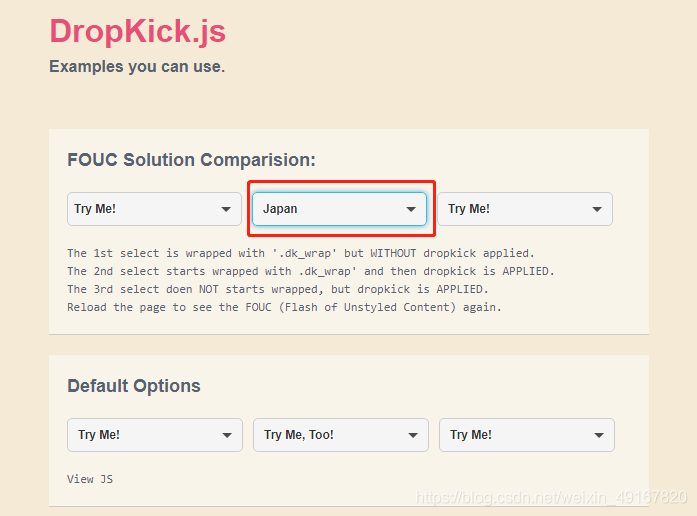
三、模拟登陆豆瓣
首先,我们在豆瓣https://www.douban.com/看到,登录时要选择短信登录,还是密码登录。我们这里要的是密码登录,手动操作时,是需要点击下图中的红框1处的;接着我们在检查网页代码时,在红框2处可以定位到红框1,并发现它是在一个iframe标签之下,所以我们要先切换iframe,代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
driver.get('https://www.douban.com/')
# 切换iframe
driver.switch_to.frame(driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')) #用copy Xpath获取
# 当属性有空格的时候 account-tab-account on 如何解决呢?
# 1.可以选其中的一部分来试试 2.xpath来定位
driver.find_element_by_class_name('account-tab-account').click() # 切换登录方式:千万不要忘记click()
time.sleep(2)
# 定位账号和密码 并输入内容
driver.find_element_by_id('username').send_keys('xxxxxx')
time.sleep(1)
driver.find_element_by_id('password').send_keys('xxxxxx')
# 点击登录按钮
driver.find_element_by_class_name('btn').click()
四、selenium获取cookie:get_cookies()
爬虫当中cookie的作用:
(1) 模拟登录(有的网站加上cookie也登录不了)
(2) 反反爬(检查cookie)
通过selenium获取的cookie 需要我们进一步做解析,解析成能够使用的样式。
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe')
driver.get('https://www.baidu.com/')
# 获取百度的cookie
cookies = driver.get_cookies() # 返回的是list
#print(type(cookies),cookies)
for cookie in cookies:
print(cookie)
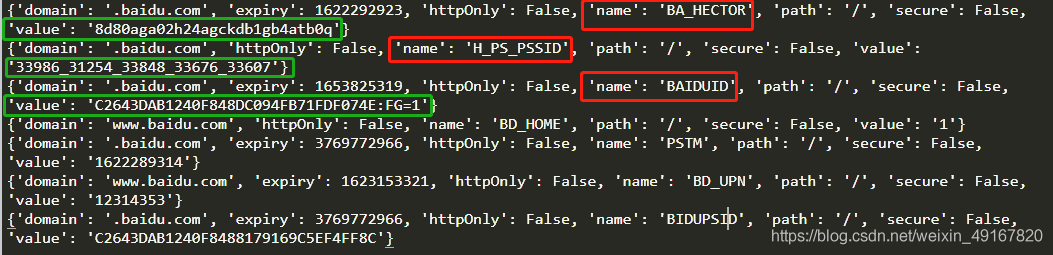
结果:
打开了一个新的网页,如图: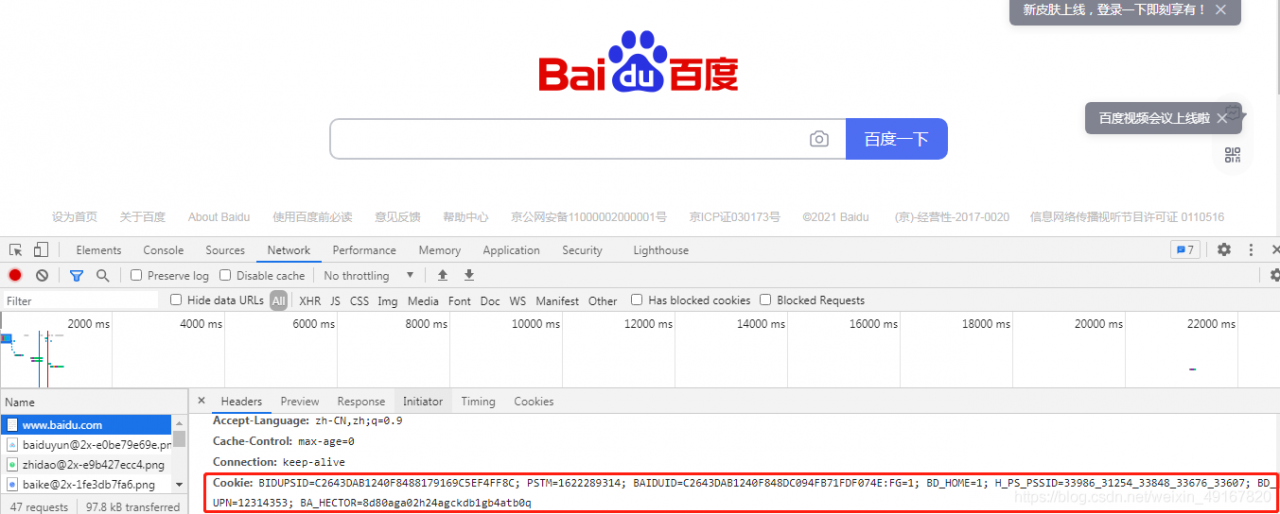
我们检查可以得到这个网页的cookie;
而我们的代码运行打印的cookie如下,观察它与上图中cookie,发现我们只需要打印出来的neme和value,将两者拼接起来就是该网页完整的cookie