Abstract
bert是transformer的双向编码器。BERT的设计是通过联合调节所有层的左右上下文,从未标记的文本中预训练深度双向表示。因此,预先训练过的BERT模型可以通过一个额外的输出层来进行微调,从而为广泛的任务创建最先进的模型,如问题回答和语言推理,而不需要实质性的任务特定的体系结构修改。(在很多任务上表现优良)
Introduction
两种策略将预训练语言表示应用到下游任务:
基于微调的方式:生成式预训练transformer(被单向限制)
基于特征的方式:elmo
bert有两个任务:完形填空 下一句预测
Related Work
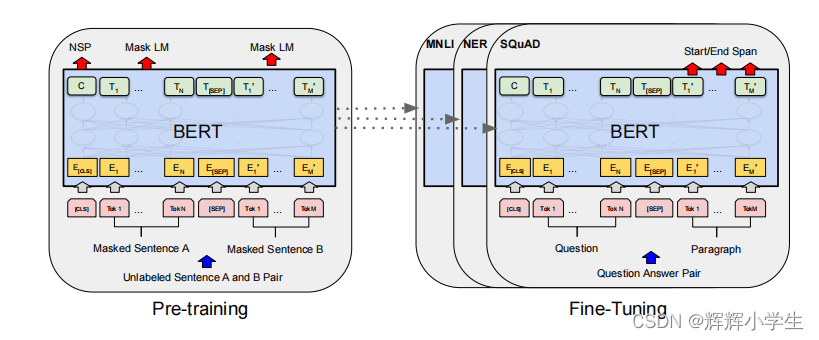
Figure 1: Overall pre-training and fifine-tuning procedures for BERT. Apart from output layers, the same architec
tures are used in both pre-training and fifine-tuning. The same pre-trained model parameters are used to initialize
models for different down-stream tasks. During fifine-tuning, all parameters are fifine-tuned. [CLS] is a special
symbol added in front of every input example, and [SEP] is a special separator token (e.g. separating ques
tions/answers).
BERT (model)
There are two steps in our framework: pre-training ( trained on unlabeled data )and fifine-tuning(trained on labeled data and each downstream task has sep arate fifine-tuned models ).
A distinctive feature of BERT is its unifified architecture across different tasks. There is mini mal difference between the pre-trained architec ture and the fifinal downstream architecture.
two model sizes: bertbase and bertlarge
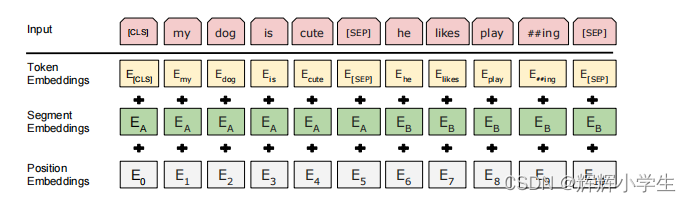
For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings. A visualiza tion of this construction can be seen in Figure 2 .
task1MLM中:复杂的mask 机制是为了缓解 【mask】token造成的预训练微调阶段分布不匹配的问题。
task2NSP:略
Experiments
略
版权声明:本文为huihuixiaoxue原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。