1、代码
str1 = '>tr|K6Z612|K6Z612_9ALTEBetalactamase Toho1 OS=Glaciecola arctica BSs20135 GN=bla PE=4 SV=1'
re1 = str1.split('|')
print(re1)
re2 = str1.split('|')[1]
print(re2)
我的需求是从str1字符串中来截取| |直接的内容两个分割的结果如下图所示,第一行是先对fastaname进行截取,然后分为三部分,之后我们对截取的内容直接取第二个即可。
2、读取文件
当fastaname数据太多,数据来自fasta文件的时候。先读取文件,然后遍历取出文件(从列表中来取元素),最后从字符串中进行指定字符串进行提取。
import csv
with open('readcsv_test01.csv', 'r') as f:
# 把需要读取的文件和这个python文件放到一个路径下
reader = csv.reader(f)
print(type(reader))
for row in reader:
print(row)#列表
# print(type(row))#打印类型——列表
rowStrings=row#把列表中的内容赋值给另外一个字符串
for rowString in rowStrings:#遍历
print(rowString)
re1 = rowString.split('|')
print("======re1=======")
print(re1)
re2 = rowString.split('|')[1]
print("======re2=======")
print(re2)
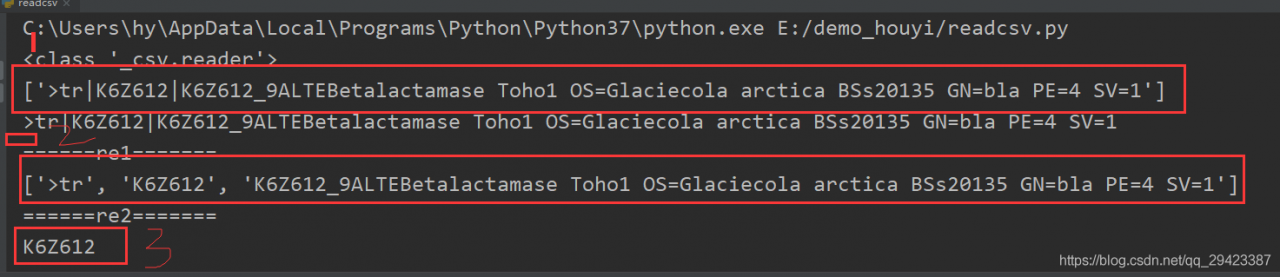
3、读取数据存入文件
import csv
with open('readcsv_test01.csv', 'r') as f:
# 把需要读取的文件和这个python文件放到一个路径下
reader = csv.reader(f)
print(type(reader))
for row in reader:
print(row)
# print(type(row))#打印类型——列表
rowStrings=row
for rowString in rowStrings:
print(rowString)
re1 = rowString.split('|')
print("======re1=======")
print(re1)
re2 = rowString.split('|')[1]
print("======re2=======")
print(re2)
#把结果在写入csv文件
tmp = open("writercsv_test02.csv", 'w', newline='') # r只读模式,newline 新行
writer = csv.writer(tmp, delimiter=' ') # reader是一个迭代器,delimiter分隔符
writer.writerow([1])
writer.writerows([[re2]])
tmp.close()
print("======close=======")

版权声明:本文为qq_29423387原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。