一、核心概念
1、索引是什么?
索引的作用是辅助快速检索数据,不同的索引形式(B\B+\倒排索引),实际上
就是数据结构不同,最终索引的落地形式还是文件,也就是不同的数据结构的文件数据,
就是不同的索引,适用于不同的场景。
2、B+树结构的索引能解决大数据检索的问题吗?
(1)、一般全文检索,检索的是文本,文本数据一般是比较大的,如果B+树的节点存储的是文本,那么会造成一个磁盘块存储不了多少数据,
最终造成B+树的深度增大.IO次数变多,搜索效率就会很慢。
(2)、B+树结构无法解决模糊检索的要求,用mysql里面的模糊匹配,很容易会造成全表扫描,搜索精准度差。
3、全文检索基本概念:
在数据存入的时候,索引系统扫描设定的字段,对字段进行分词处理,对分词项创建索引,索引指明数据的唯一标识/当前词项在文档中出现的频率和位置。
在查询数据的时候,根据查询的文本,对文本进行分词处理,然后去匹配索引,根据索引找到数据的唯一标识,最后通过唯一标识找出对应的数据。
4、倒排索引的结构
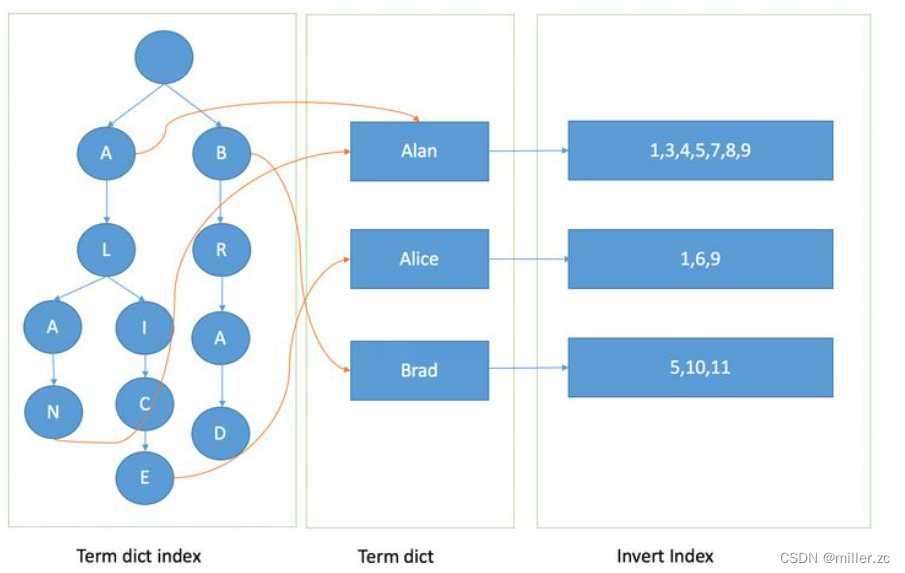
(1)、term index:
词项字典的索引,存在于内存中(磁盘中也会存在一份,后缀为.tip),实际上就是包含trem词项前缀的树形结构。根据term index可以快速定位到
某个offset(某个节点分支上)。通过Term Index 找到对应的Term Dictionary的 block(磁盘块),然后再去磁盘直接找到term,减少磁盘的随机读写次数,大大的提升查询效率。
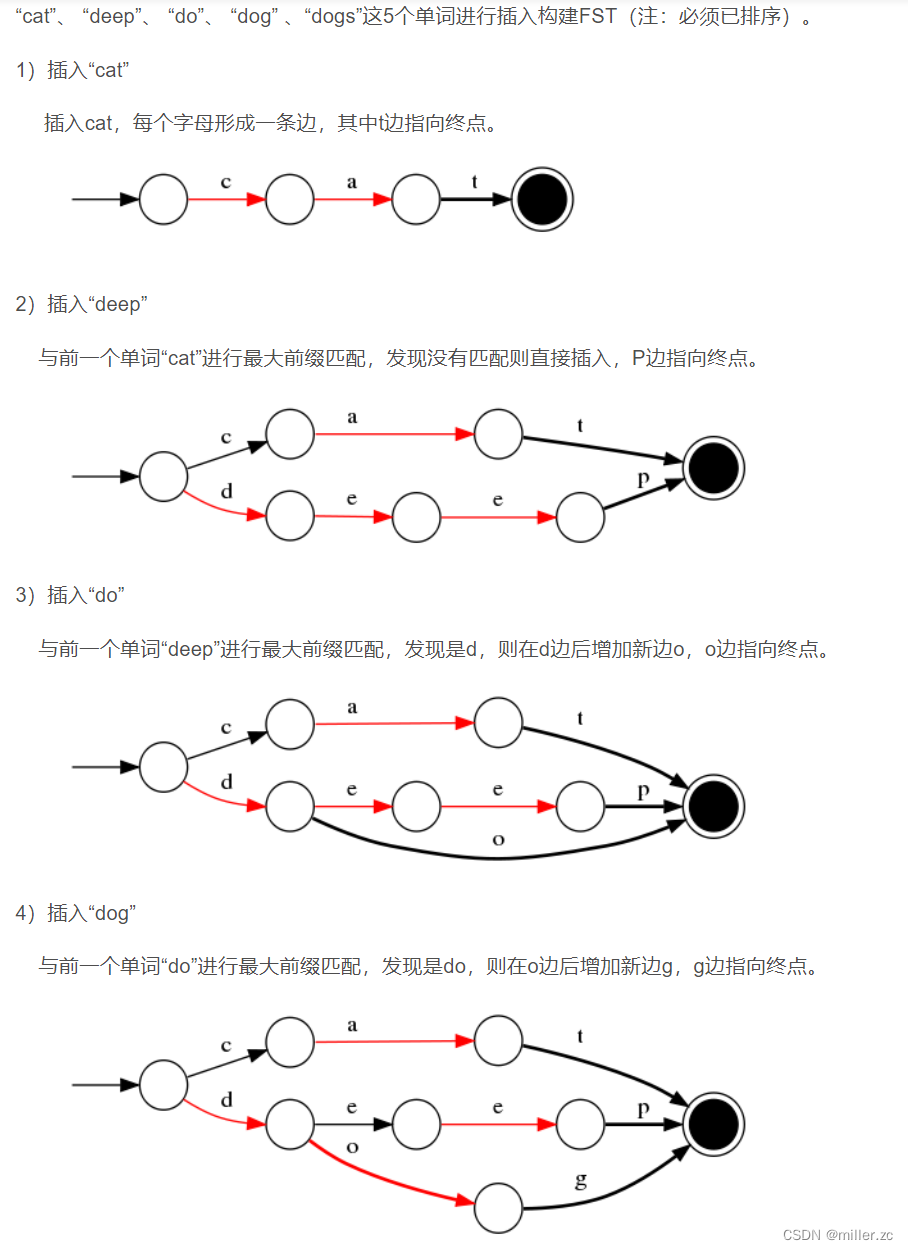
term index的数据结构是FST(有限状态转换),实际上就是第一次插入数据的时候,根据分词形成一条连接线
后面再插入的时候,与前一个分词进行最大前缀匹配,发现没有匹配就直接插入,
发现可以匹配,就在最大匹配的分词节点上开辟一个分支,后面的分词就是另外一条连接路径。
FST的优点就在于压缩率好,节省内存空间。分词完成之后,内存里面就会存在这样一个FST数据结构,
后面查询的时候,根据查询条件,先在FST结构上快速匹配出节点信息,然后再找到对应的Term Dictionary的 block(磁盘块),最后根据Term Dictionary里面的词项找到对应的PostingList里面的文档id等数据。
(2)、term dictionary(词项索引)
存储在磁盘,文件后缀是.tim,所有的分词都会存储在磁盘,由于分词项很多,所以会对分词项进行排序,查找的时候就用二分法进行查找。
term index的每个节点,都会指向tim文件对应的某个block(磁盘块),所以可以根据term index快速定位到
分词项所处的磁盘块。
(3)、posting List (倒排表)
存储的是文档对应的id/分词出现的频率/分词出现的次数等信息,和term dictionary里面的词项对应上。
Frame Of Reference(FOR)编码技术对里边的数据进行压缩,节约磁盘空间。
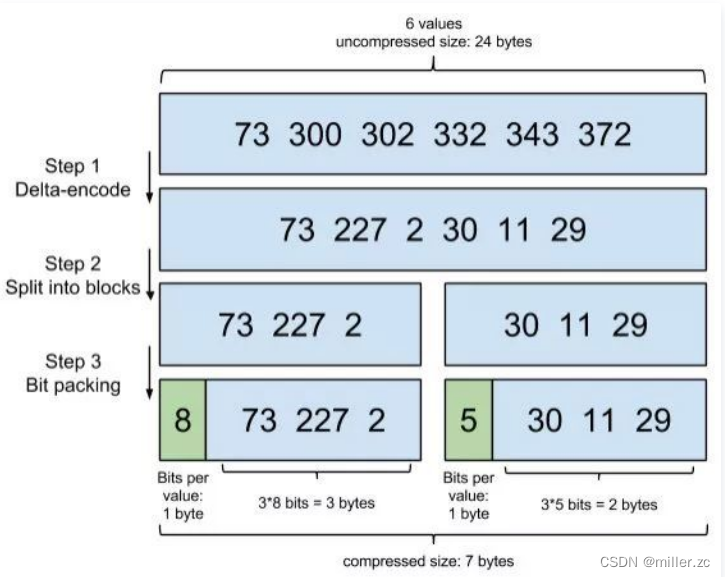
FOR:
如果不数据压缩,一个id就要用一个int表示(4个字节,4*8个bit),所以可以通过for算法,
尽量按照规律把数据变小,以便用最少的bit存储数据。
for采用的方法就是 记录增量数据,如果数据稠密(数据之间相差不大),增量数据是很小的,
所以就满足了变成小数的步骤。
Roaring Bitmaps:
如果数据稀疏(数据之间的增量很大),用FOR算法效果也是很差的,所以就有了Roaring Bitmaps算法。
使用Roaring Bitmaps的好处就是可以节省空间和快速得出交并集的结果。

快速查找原理
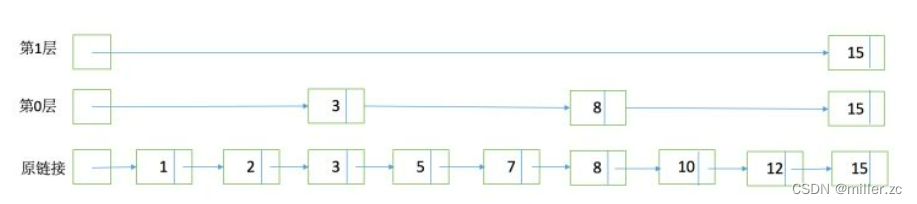
posting List里面的id是按顺序排列的,其中的数据结构是SkipList。
元素排序的,对应到我们的倒排链,lucene是按照docid进行排序,从小到大。
跳跃有一个固定的间隔,这个是需要建立SkipList的时候指定好,例如下图以间隔是3
SkipList的层次,这个是指整个SkipList有几层
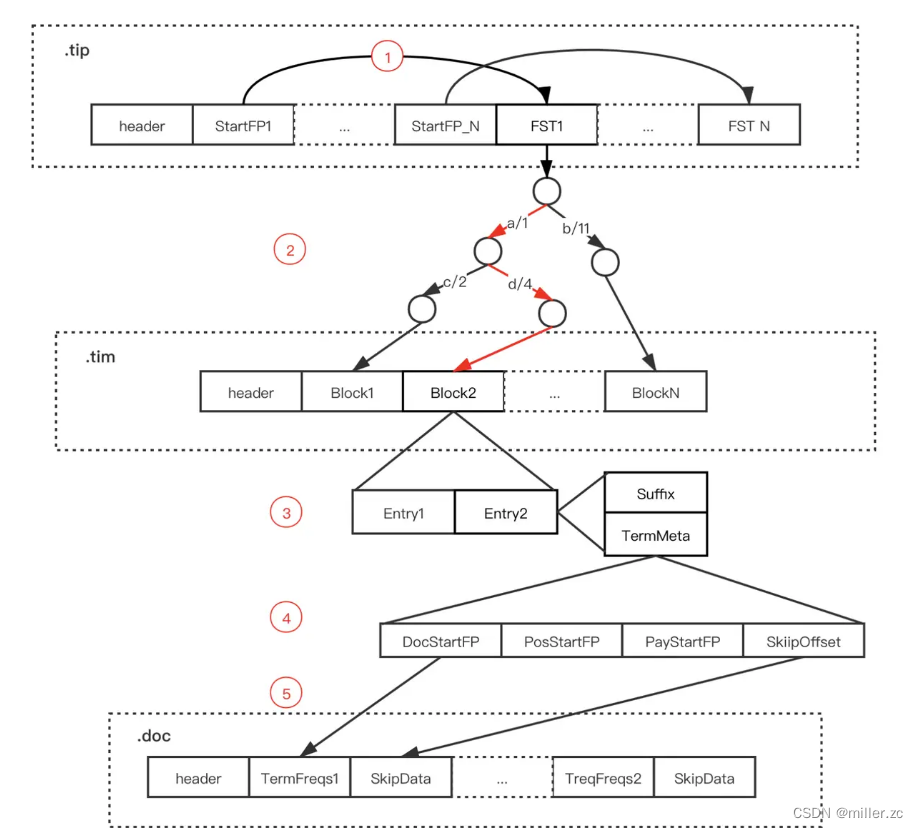
总体的数据结构图:
5、倒排查询逻辑
(1)、通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
(2)、通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
(3)、将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
(4)、存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
(5)、如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通
过SkipData快速跳转
版权声明:本文为qq_39188150原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。