1、in 的执行过程:
- 首先执行子查询,获取子结果集;
- 主查询再去子结果集里找符合要求的列表,符合要求的则输出,不符合要求的就不输出;
所以适合,in 的子查询的记录数少的情况。
如下面的sql
select * from t1 where t1.name in (select name from t2);
首先执行子查询 select name from t2
然后主查询去子查询里找符合要求的。
需要注意的是,in 查询的子查询中,只能返回一个字段,返回多个字段则会报错。![]()
2、exists 的执行过程
- 首先执行一次外部查询
- 对于外部查询的每一行,分别执行一次子查询
- 根据子查询的返回结果来确定外部查询的结果集
exists 查询分为两种情况,一种是外部查询和 exists 的子查询相关;另一种是外部查询和 exists 的子查询不相关。
比如下面的业务,寻找一个作业的最大版本输出,原始表记录是这样的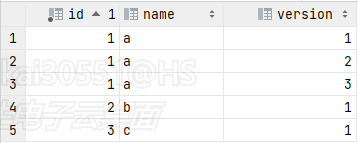
期望输出结果: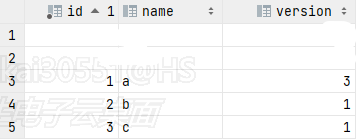
sql 可以这样写:
select * from mytest1 t1 where not exists (
select 1 from mytest1 t2 where t1.id=t2.id and t1.version < t2.version
)
这个 sql 中,外部表和内部表是关联的,首先查询出外面 t1 表的所有记录,5 条。
然后每 1 条都作为条件去子查询里查。
首先拿第一条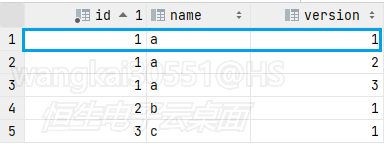
因为是按id匹配,这条蓝色框的记录会和以下三条黄色框的记录做判断: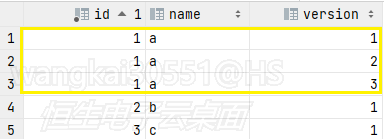
由于 1 < 2 , 1 < 3 ,满足 t1.version < t2.version ,又是 not exists ,这条记录不予返回。
所以,只有下面这条绿色的记录是不满足子查询条件的: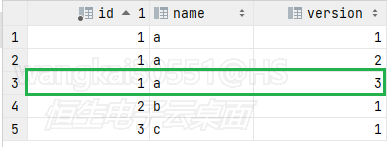
可以作为结果集返回。
其他结果由于都是相等的,所以都作为结果集返回。
最终的结果是: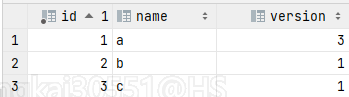
版权声明:本文为qq_24434251原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。