leveldb是一个google出品的单机kv数据库。用C++编写,代码量很小,大概只有1~2万行。代码写的可以用优雅来形容,毫无疑问是我至今看到的最优雅的c++代码。而且由于代码量比较小,可以直接通读整个源码,了解一个完整的kv系统的构建流程。是一个很好的学习材料。这也是我第一次读数据库方面的源码,尝试用博客记录阅读过程。在阅读源码的过程中,感觉自己有了很大的提高。希望再写一遍,把这种提高深刻以下!
本系列的leveldb源码剖析就从数据编码开始
必要性
数据编码算法实现在util/coding.h和util/coding.cpp两个文件中。
leveldb中的数据编码主要是将整型数编码成可以和ASCII码区分的二进制形式,然后实现和kv统一的存储方式。比如在存储一个键值对时
key = "hello" , value = "world"如果我们直接像下面这样将kv的Ascii都相邻存储

那肯定是不行的,因为在实际查找的时候,我们根本区分不出key和value的边界。一种可行的方式是这样的

这样,我们根据key和value的长度,就可以对它们进行区分了。但是这里的K_len和V_len的存储还有一些其他的讲究。
回到前面的例子。对于key = “hello” value = “world”,我们采用这里的存储方式的话,则内存布局可能是这样的:

这里,我们直接将数字的ascii码存储进去。本例中恰好都是单位的数字,如果是多位,则先将数字转换成字符串,再将每位依次存储。当然,这样存储数字是不对的。因为如果key或者value刚好是数字字符串,那就乱套了。
所以我们可以看出对数字进行编码存储的必要性。
实现
leveldb对数字的编码很简单:将数字按连续的字节直接存储。整型数包括32位和64位,下面我们以32位为例看一下它是怎么对数字进行编码的。
对于数字54,它的二进制形式如下:
110110当然,这里只列了最低的8位,后面的24位都是0,则按照编码它在内存中的形式如下:

最高的三个字节都是0,最低的字节为00110110,这里我们会发现一个问题,为了与字符ASCII码区分,以免造成kv存储混乱,我们没有按照 ‘5”4’的形式存储54,但是这里的00110110对应的却是另一个字符的ASCII码—6.于是前面所做的努力于事无补了。当然也并不是那么糟糕,比如我们可以事先固定下来用于存储k_len的是32位8个字节,这样直接读取8个字节进来当k_len也可以,这种固定长度的编码实现在EncodeFixed32 函数中。但是显然这样会造成存储浪费,比如这里的54,前面三个字节都是0,我们实际只需要存储后面的一个字节就可以了,如果存储4个字节的话会造成75%的存储浪费,太不值得了。leveldb采用了变长编码来解决这个问题:
变长编码主要是建立在ASCII码的特点上。从标准的ASCII码
我们可以观察到,所有字符的ASCII码的最高位都是0。所以我们可以利用这个最高位来区分用于存储数值的区域和用于存储key-value的区域。我们这里也以32位为例进行说明,对32位整型数的变成编码实现在
EncodeVarint32函数中。因为最高位要用来做标记位,因此变长编码不像前面的算法那样以每个字节为单位进行编码,它以7位为一个单位进行编码:

最后面的3位为补位,也就是说对于一个32位的整型数,最长需要5*8=40位来对它进行编码存储。这里的意思就是对于32位的整型数字, 它的每七位存储在一个字节中,这样空出的一位用来做标记位,以区分每个字节对应的是ASCII码信息还是数值信息。
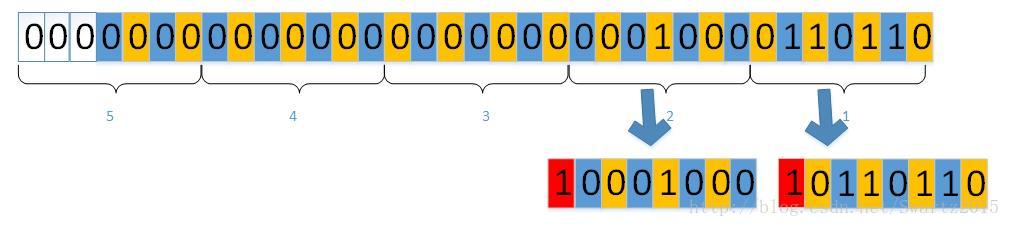
因为现在我们可以区分每个字节应该用于计算数值还是它是属于key-value值,因此就不必要像前面那样固定存储的字节数,现在只需要存储 有效位数就可以了。由于数值至少有一个字节,因此对于每个key-value存储域,它的第一个字节,以及key值后的第一个字节肯定是用于计算长度,不属于具体的key-value值, 因此leveldb对于变长编码的第一个字节并不做标记处理,这里以防读代码的时候有困惑。
总结
leveldb数值编码主要包括 fixed固定型编码和Variant变长型编码。固定型编码很简单,就是将整型数按字节编码,因为实现约定了用于存储数值的长度,因此不会造成和具体的key-value存储产生混乱,但是这种编码会造成空间浪费。于是响应引入了变长编码,变长编码基于所有字符的ASCII码的最高位都是0的特点,用最高位做标记,在每个字节中只存储整型数的7位,最高位做标记用,这样就只需要通过判断标记位就可以区分用于表示数值的域和用于存储key-value的具体值的域了。
leveldb编码部分还是相对比较简单的。详细实现再看源码,这里就不贴了。再接再厉!