这次我们深入了解malloc,malloc究竟分配多么大的空间,以及整个过程是如何进行的。
malloc其实并没有想象中那么低效,在底层的设计中也是充满着精妙之处的。
以下分解内容以VC6版本为基础。
main()的准备工作
下图展示了调用main之前编译器都做了什么。
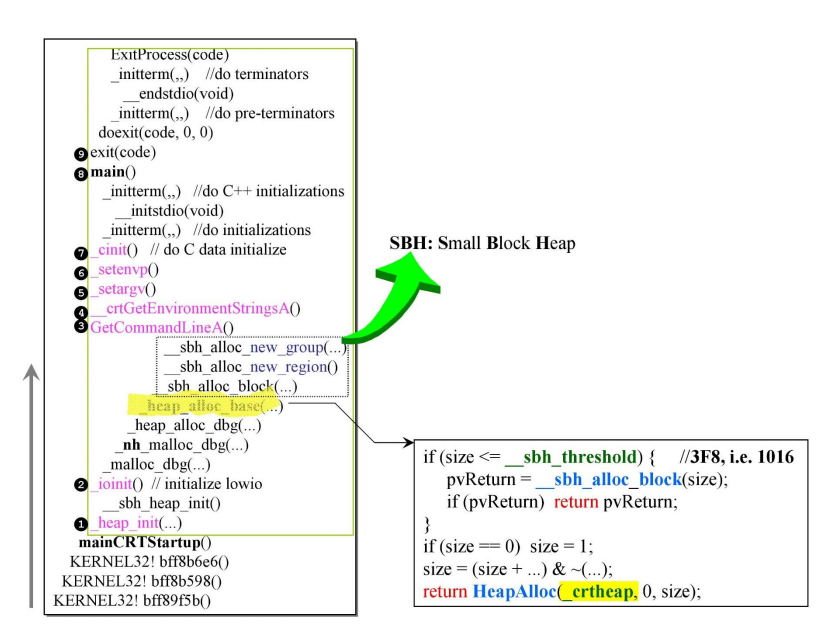
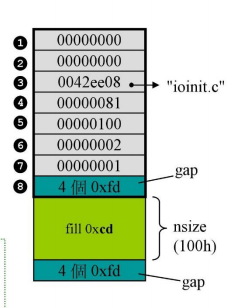
按照从下往上的顺序,依次调用了1-7这些初始化程序准备函数。
在其中,又会有一些嵌套式的调用。我们可以看到在ioinit中调用了诸如malloc_dbg(),堆分配相关的初始化,以及非常重要的sbh相关函数。
SBH小区块管理

从heap_alloc_base()这段代码中就可以看出,在申请空间小于1016时会调用_sbh_alloc_block(),而其他空间大小则会直接使用系统的HeapAlloc
这里的sbh代表Small Block Heap,是对于申请堆区小空间的管理方式。
而这部分内容在VC10时,这些管理方式被包装到了OS里面。
SBH就是我们要分析的重点。
SBH之始
在开始时,系统会先建立一个_crtheap,初值为4096。
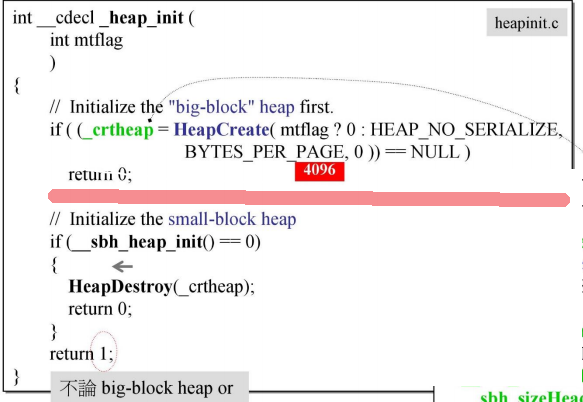
然后调用_sbh_heap_init(),分配配置SBH所需的管理空间。
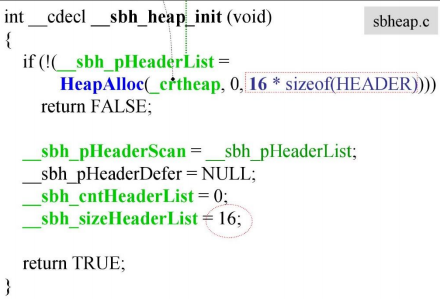
可以看到这里分配了16个HEADER,类似链表的结构。

而之后动态配置中申请的空间就要与1016比较了,小于就从SBH取,大于就调用HeapAlloc()从_crtheap取
Header的结构如下:
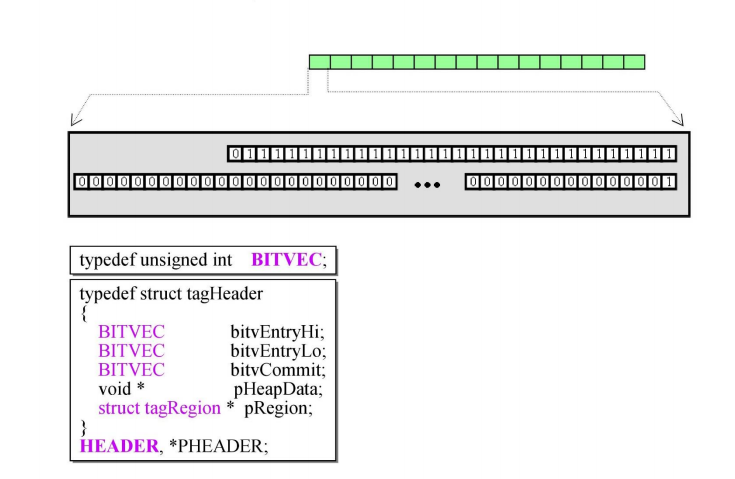
其中Hi和Lo共有64位。Commit有32位。
还有一个指针以及一个结构体指针,这些在后面都会用到。
malloc()的真相
ioinit()申请空间
接下来就会进行一系列的内存分配与管理了。
首先调用的是ioinit(),这里会申请一些信息文件,大小为32*8=256 也就是16进制的100h
然后进入到debug模式

malloc就会对其进行包装。(这些包装都是为了debug做准备的)
debug模式包装
接下来就会在这100h的空间上下功夫。
首先整个区块的大小分为以下几块:

包括_CrtMemBlockHeader的大小,申请空间的大小以及无人区的大小。
这里就是动态申请,所以可以用这里的blocksize选择分配空间的方式(SBH还是系统)
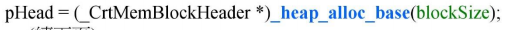
_CrtMemBlockHeader是什么呢?其实就是我们以前所说的malloc分配的debug header。
但这次我们可以更清楚它是由什么组成的。

对照结构体的定义可以看出:
1和2是前后指针,用于连接多个block。
3指向的是申请这块空间的程序地址(所在的文件)。
4是记录申请使用该内存空间所在文件的行号
5是申请空间的实际大小,这里就是100h
6表示当前内存块的类型。这里有宏定义:

对应此处的是CRT块,也就是系统申请的内存。
7代表操作操作流水号
8则是无人区,一共上下共8个,大小是0xfd
这样无人区可以把实际申请内存空间像栏杆一样保护住。如果有内存越界发生可以在debug下及时发现。
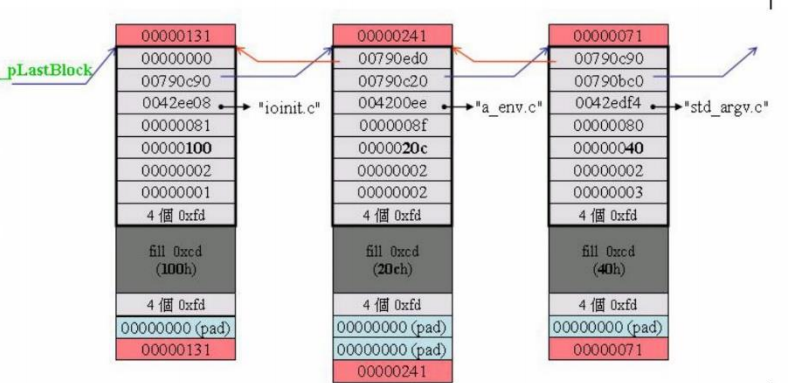
这里的前后指针实现的效果如下:
就是将各个块连接在一起。
管理机制
在使用heap_alloc_base()申请空间时,如果符合小区块,那么会调用
sbh_alloc_block()
sbh_alloc_new_region()
sbh_alloc_new_group()
在sbh_alloc_block()里,会加入pad填充部分把大小调整至16的倍数,然后再加上下cookie(每个cookie大小为4字节)
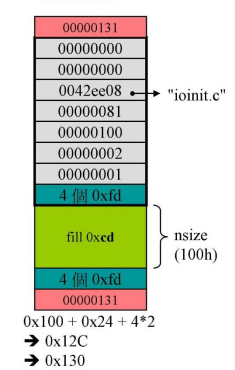
这里的cookie记录总的大小,注意是131h而不是130h,这是因为16进制结尾都是0,如果某块分给了客户端,就用1代表分配出去了。
sbh_alloc_new_region()则实现了管理空间,真正开始分配。
管理中心
region,是内存的管理中心。
前面我们说过有16个HEADERS,而每一个HEADER都管理着这样一个空间。
先来看结构体:

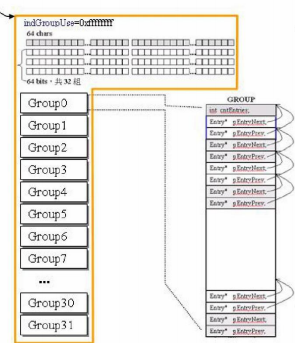
region有一个char类型的数组,64位。最重要的是bitvGroupHi和bitvGroupLow,一共有32组,每组都是64位的。
还有一个tagGroup结构体,用来管理32个group
这个结构体如下:

除了有一个用于计数的cntEntires,还有64个tagListHead
tagListHead其实就是一个双向链表结构

所以这64个相当于32组。
最后整体就是这样的结构:
总览全局
结合每一个Header和所有申请的内存,我们可以得到这样的管理图。
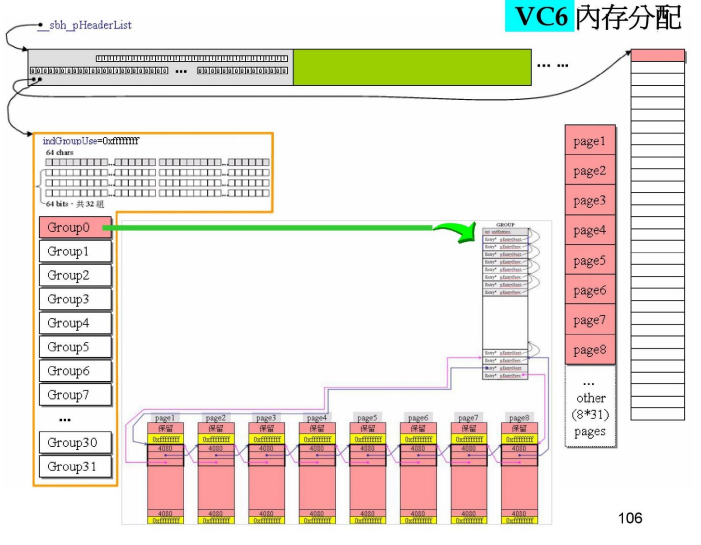
先来看右边的一列,这是Header管理的空间但是是虚拟内存空间,只有当真正申请时才会真正分配。
而这些空间的总大小为1MB,共有32块,那么每块为32k
这32k会被分为8个page,每个page大小4k
然后将其首尾相接,交给管理中心。注意位置是在group0的最后一对前后指针。
**这里管理大于1k的内容。**因为1024k/16=64,刚好对应group的64个位置。所以大于1024的内容都交给最后一块管理。
这8个page也不是直接将4k串连起来,而是进行了一点处理。
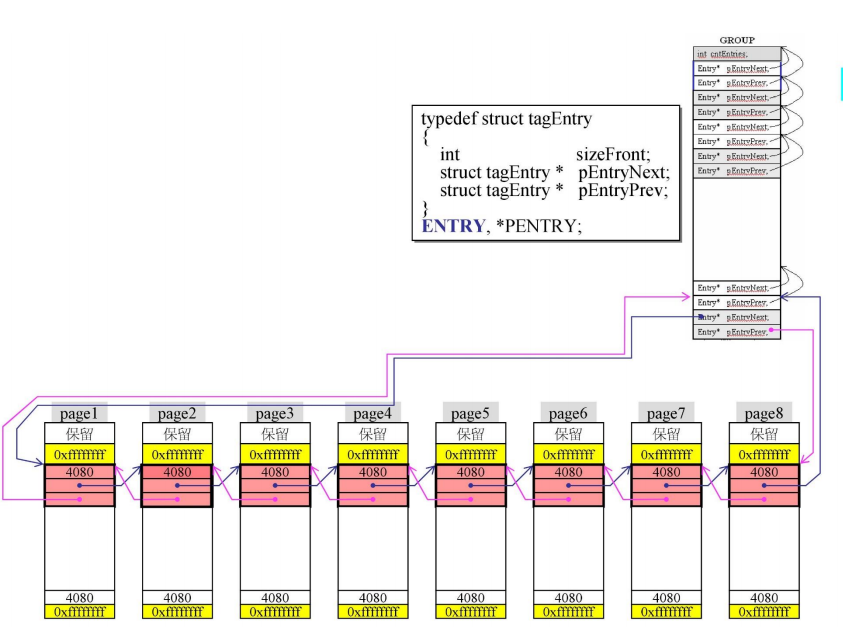
每个部分为4096bytes,先分出两个边界(黄色部分),是2*4=8bytes,剩余4088,调整到16的倍数,为4080,剩余的8作为保留。
这里的黄色部分为回收做了准备。
而分配的空间,就来自于这些切割好的空白部分。
比如前面ioinit申请的30h的空间,就可以从这里分出去。
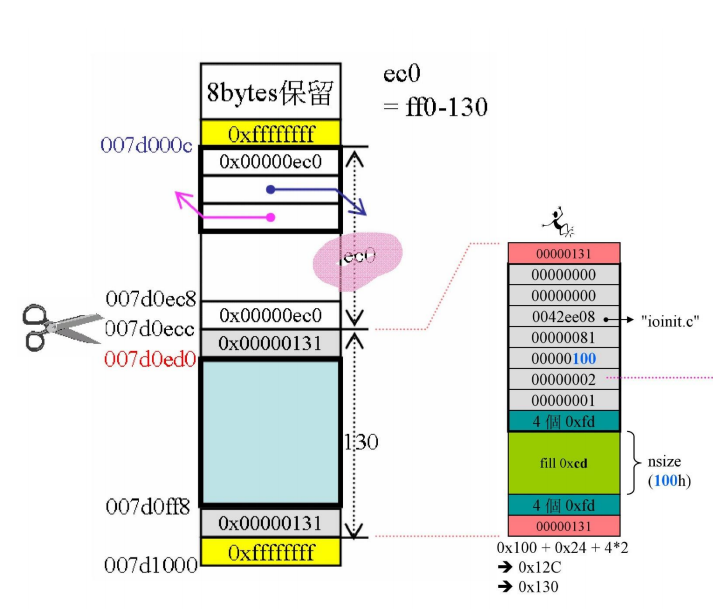
100h的实际申请空间+24h的debug header再加上两个cookies,总大小130h,这时对于进行debug header构造的程序来说,得到的地址就是这块空间的起始地址007d0ed0
内存分配流程
根据几张图,类似alloc那样来进行分配,看看发生了什么。
ioinit申请100h大小,区块大小130h,查找18号链表,发现无空闲。
先保留1MB的地址空间(没有分配),再实际分配32k的大小,分成8个page,再从page中分130h的空间。
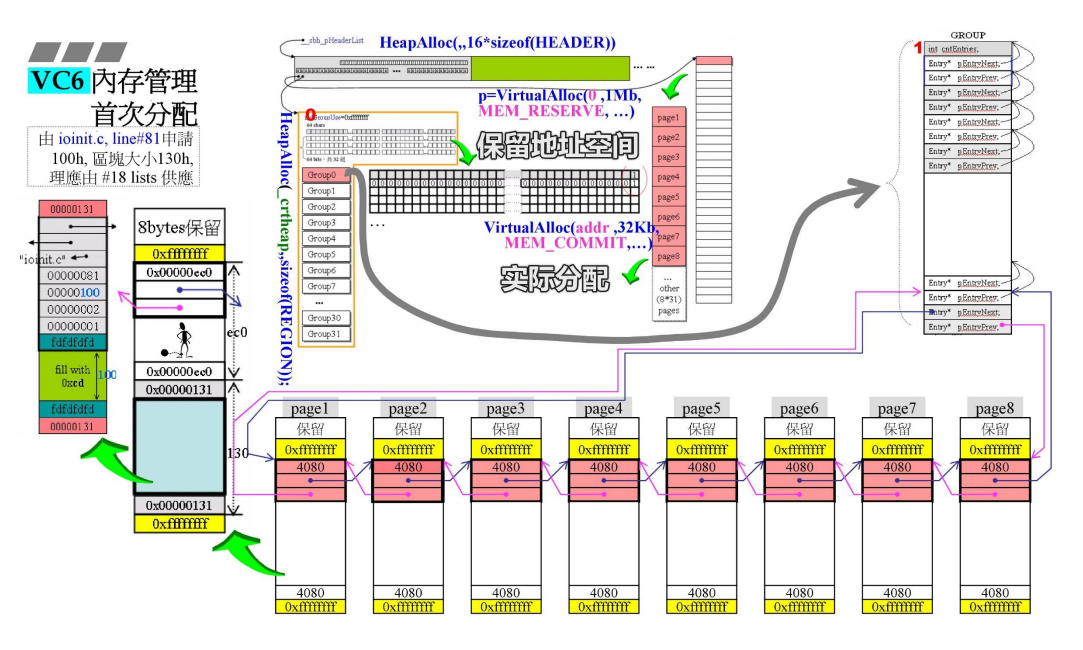
对于一个page来说,还剩余ec0的空间。
管理中心是如何记录这些变化的呢?
首先,group0的cntEntries会+1,说明有一块空间被分配了出去。
然后,header中的32组64bytes的数据结构可以记录对应的链表信息。
比如这时只有最后一条链表连有数据块,所以对应的group0的最后一位置为1
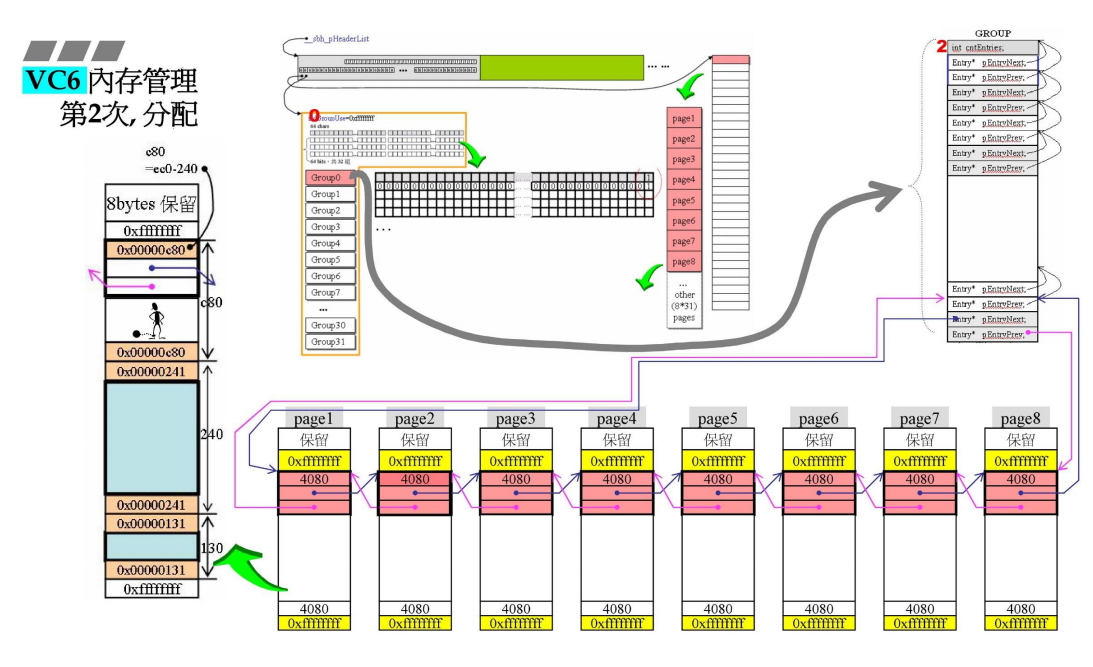
继续申请240h的空间大小,由page分配,剩余c80
group0的cntEntries继续+1变为2,有两块空间被分配。
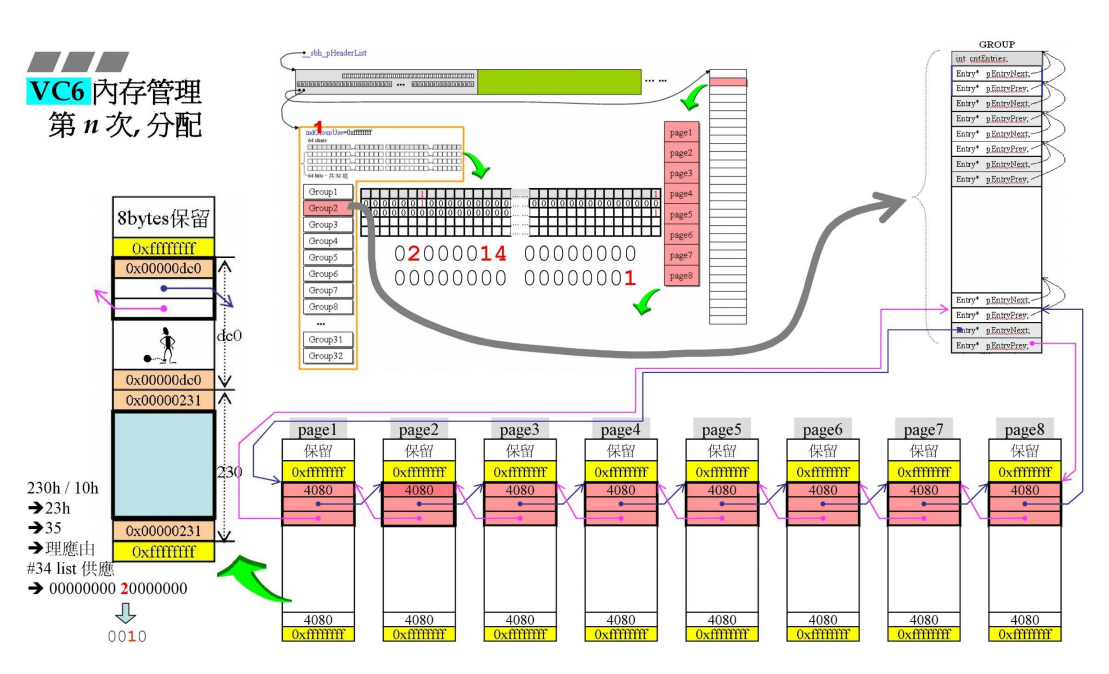
假设已经经历了14次分配,此时对应的cntEntries也变为了14
这时有一块空间需要回收,大小是240h,那么应该还给240h/10h=36-1=35号链表。于是就把这块空间的前后指针拉向#35。cntEntries-1 变为13
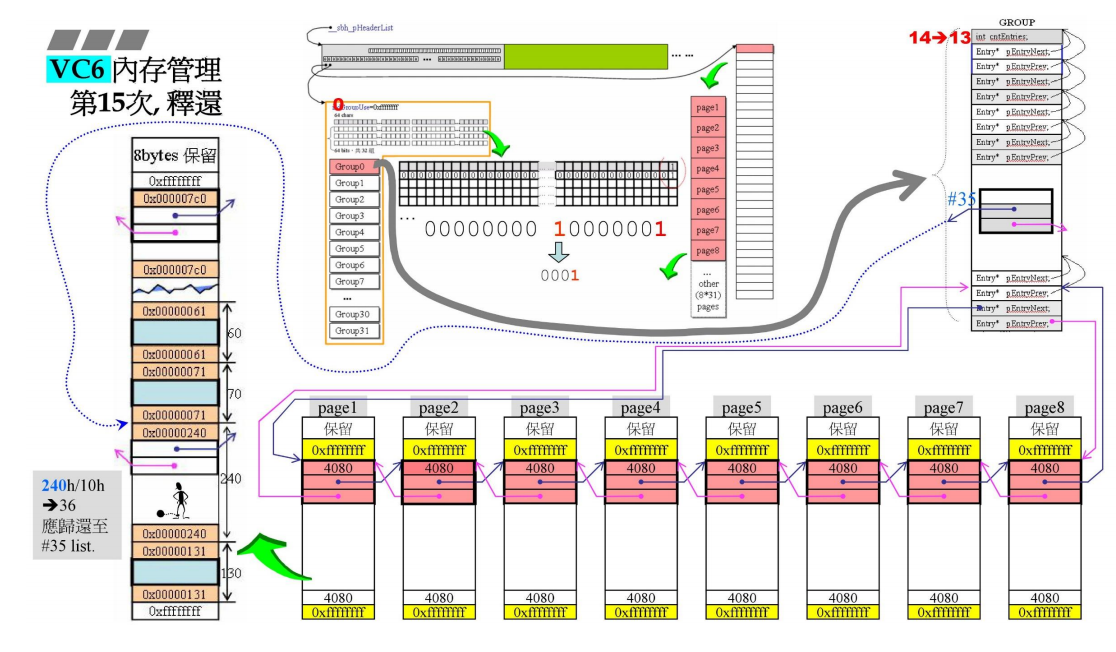
同时管理中心改变group0对应的值
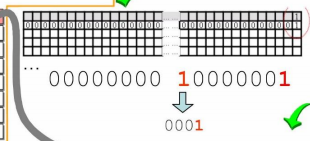
表示第35号有连接数据块。
这里的前后指针依旧是嵌入式指针,在分配出去的时候是完整的空间,在回收时才会把前面的空间当作指针使用。
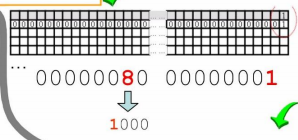
再申请b0的空间,按顺序检查链表,发现最近的有空间的链表是#35,所以从35号的空间中分出b0,剩余190。
cntEntries+1变为14
重新调整,把190h分给190h/10h=25-1=#24号链表。
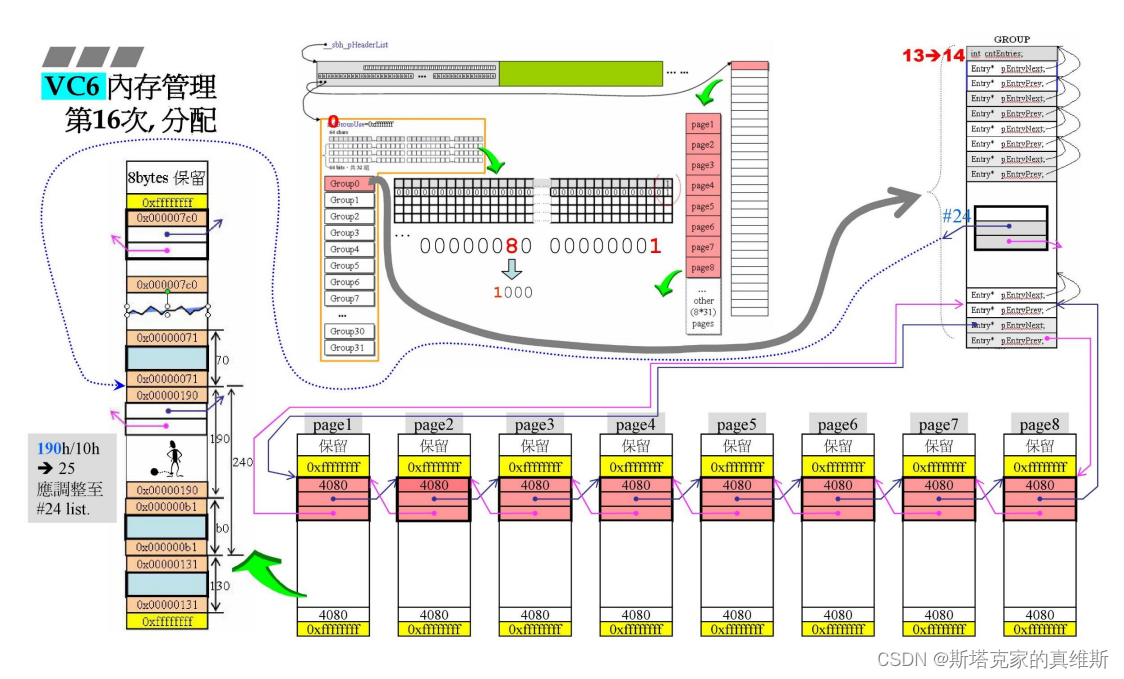
同时修改管理中心的信息。
在经历了n次分配后,可能已经跳到了group1,管理中心对应的数据逐渐增加调整。
空间回收
malloc与free对应,而free并不是像alloc一样把区块据为己有,而是做到了真正的回收。
这时就用到了上下cookie。
cookie用来记录大小,但为什么要一对呢?因为当某一块为空时,直接根据其上下cookie就可以把上方和下方与之相连的空闲块都一次性回收。
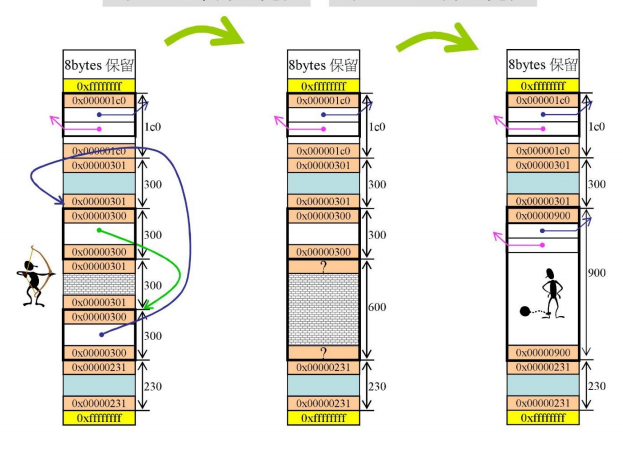
free§在寻找区块时经历了以下过程:
首先看p在哪一个header中,再看p在哪一个group中,再看p在哪一个list中(看cookie)
这样的分段管理是非常利于归还内存的。
全回收
如何判断给出了几块空间,还有几块空间没收回?
还记得在group里有一个变量cntEntries,它可以记录有几块空间被分配了出去。
如果该值为0,那么说明空间已经全回收了。
但最后一块链表连接的8个page暂时不收回。为了预防下次再有申请内存的行为。直到出现两个全回收的group后,才会真正把所有空间归还。
实现方式是用_sbh_pHeaderDefer指针指向全回收的group所属的header,但暂时不释放,当第二个全回收group出现的时候去检查该指针的状态,如果为Defer那么就可以释放了。
malloc与allocator
我们知道了malloc的实现方式,那么与之前说的alloc这种设计有什么关联呢?
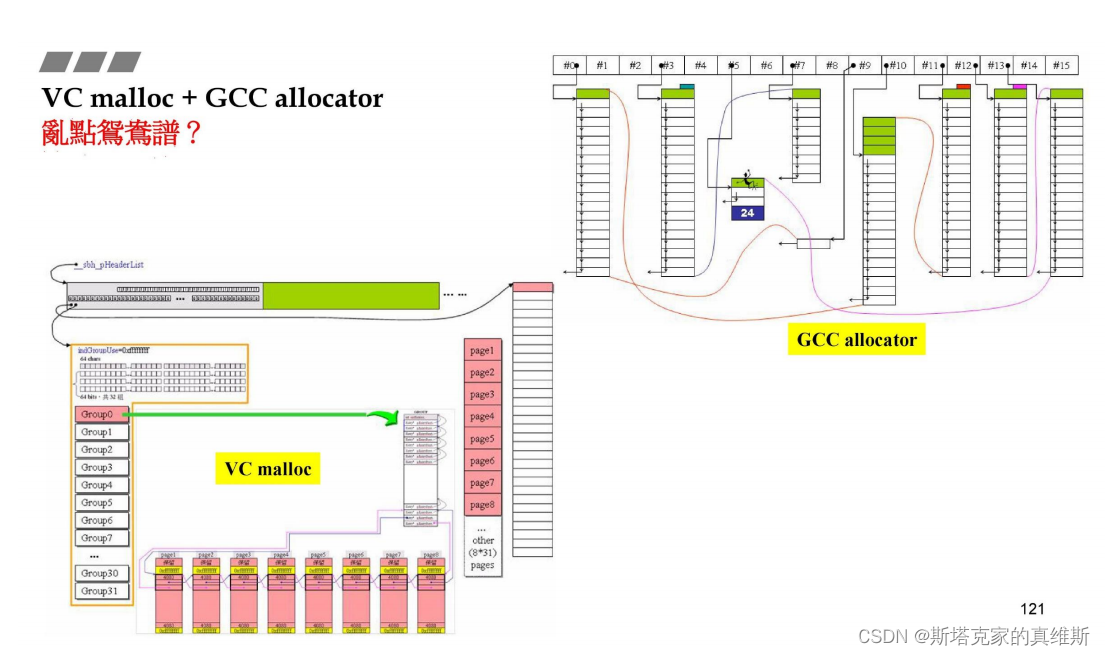
对于alloc来说,管理的区块最大是128bytes,而这么大的区块对于malloc来说就是SBH所管理的小区块。
malloc已经足够快了,单独设计并不是想要提升效率,而是为了减少cookie。
那一层一层的设计是否有些多余呢?
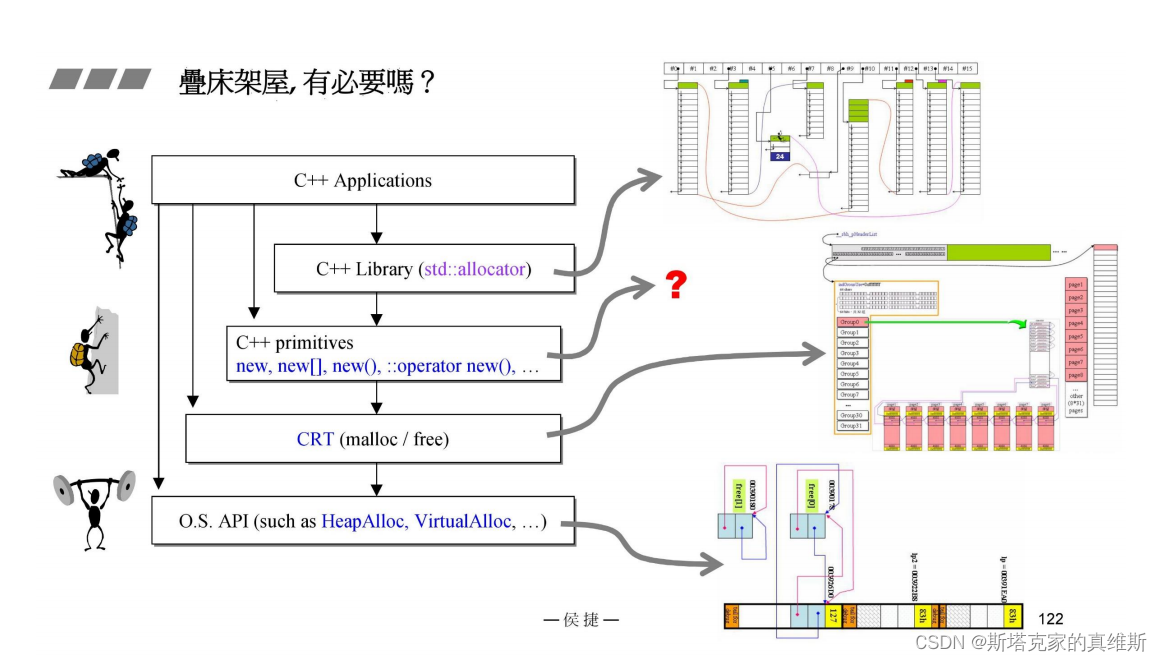
既然下层已经有这么精妙的设计,上层还有必要重新设计么?
当然是有的,抛开新的管理方式不谈,上层无法预测自己的使用场景,也就无法预测下层是否做了相应的管理,所以还是有必要的。