Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis中的数据特征
Redis是一种内存级数据库,所有数据均存放在内存中,内存中的数据可以通过TTL指令获取其状态
XX :具有时效性的数据
-1 :永久有效的数据
-2 :已经过期的数据或被删除的数据或未定义的数据
在我们了解完基础知识后我们进入主题,来看看它的删除策略!
Redis 缓存删除策略分为定时删除、定期删除与惰性删除。前两个是主动删除,后一个是被动删除。
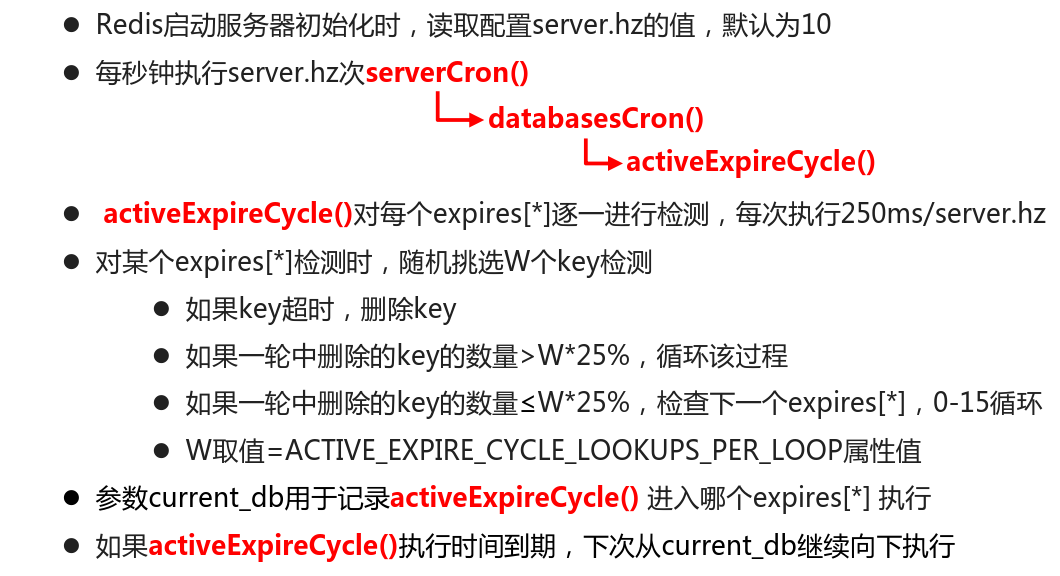
一、数据删除策略
数据删除策略的目标:在内存占用与CPU占用之间寻找一种平衡,顾此失彼都会造成整体redis性能的下降,甚至引发服务器宕机或
内存泄露。
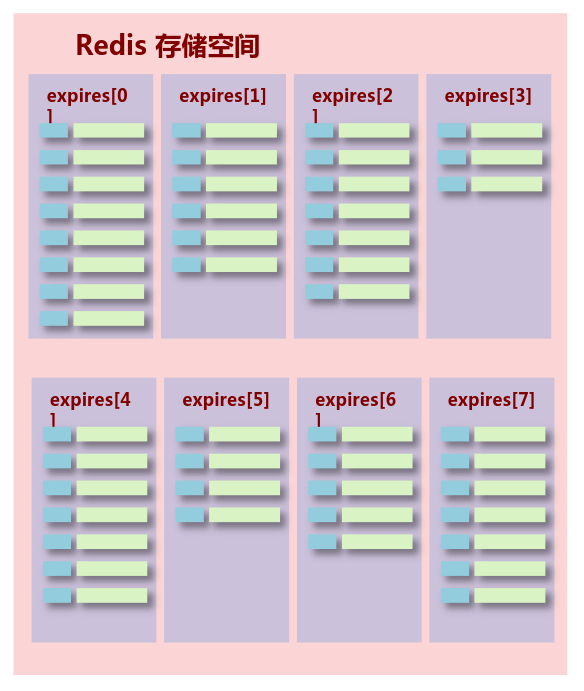
时效性数据的存储结构: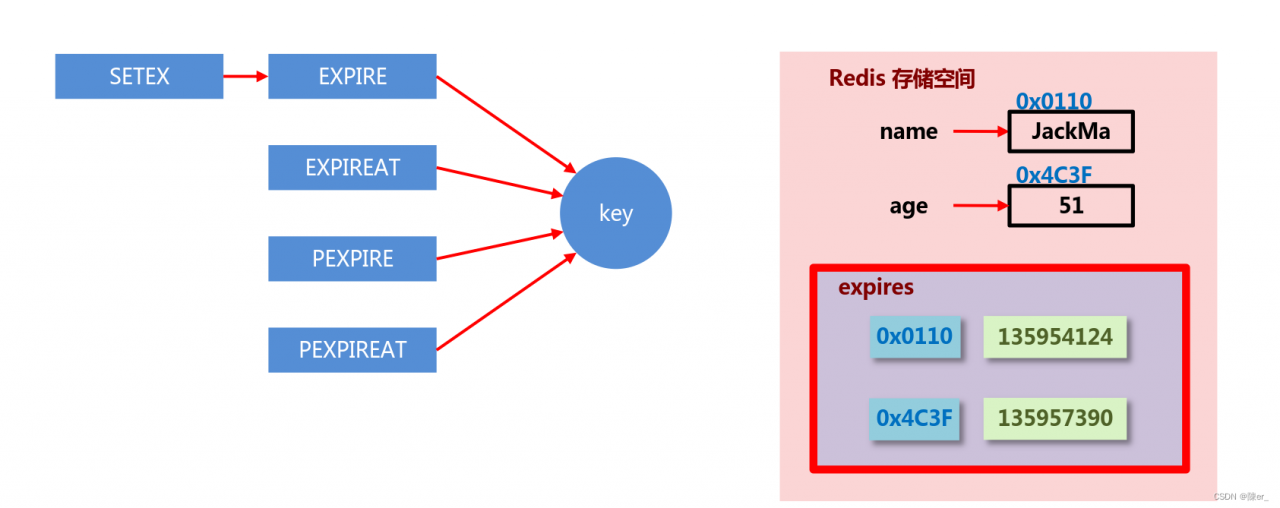
定时删除
- 创建一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作
- 优点:节约内存,到时就删除,快速释放掉不必要的内存占用
- 缺点:CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
- 总结:用处理器性能换取存储空间 (拿时间换空间)
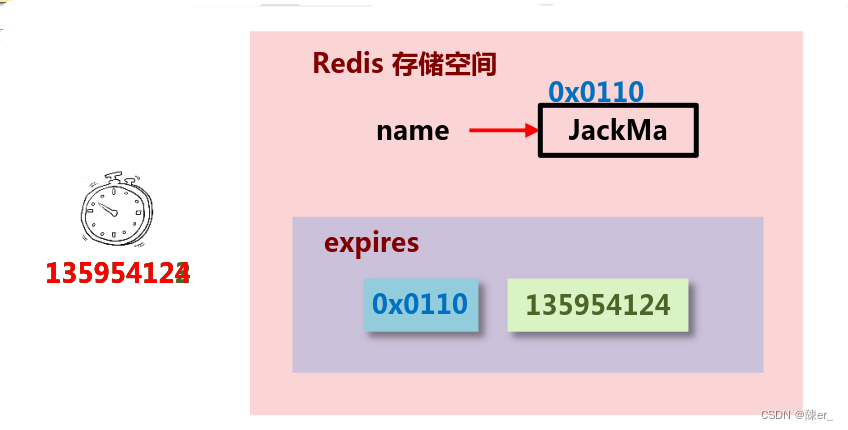
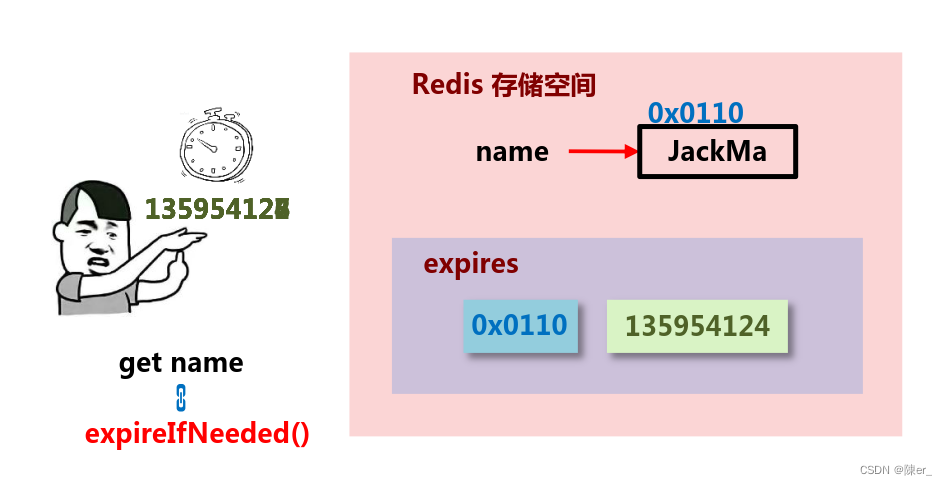
2. 惰性删除
- 数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据 ;发现已过期,删除,返回不存在。
- 优点:节约CPU性能,发现必须删除的时候才删除
- 缺点:内存压力很大,出现长期占用内存的数据
- 总结:用存储空间换取处理器性能(拿空间换时间)
3. 定期删除
- 两种方案都走极端,有没有折中方案?
- 周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
- 特点1:CPU性能占用设置有峰值,检测频度可自定义设置
- 特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
- 总结:周期性抽查存储空间 (随机抽查,重点抽查)
删除策略比对
| 内存占用 | CPU占用 | 特征 | |
|---|---|---|---|
| 定时删除 | 节约内存,无占用 | 不分时段占用CPU资源,频度高 | 时间换空间 |
| 惰性删除 | 内存占用严重 | 延时执行,CPU利用率高 | 空间换时间 |
| 定期删除 | 内存定期随机清理 | 每秒花费固定的CPU资源维护内存 | 随机抽查,重点抽查 |
在redis里,会使用惰性删除和定期删除两种方式
策略失效场景
惰性删除因为直到访问过期 key 时才删除它,可能导致内存出现大量过期的 key。而定期删除是一种随机抽取策略,有些 key 可能一直没有被抽取到,导致一直驻留在内存中。所以这两种策略都可能导致 Redis 的内存占有率越来越高。这时就需要内存淘汰机制来解决这一问题。
逐出算法
当内存被永久数据占满(删除策略只能清除过期数据),新数据进入redis时,如果内存不足怎么办?
Redis使用内存存储数据,在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足。如果内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。清理数据的策略称为逐出算法
注意:逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕后,如果不能达到内存清理的要求,将出现如下错误信息:

影响数据逐出的相关配置
- maxmemory:redis可使用内存占物理内存的最大比例,默认为0,表示不限制redis使用内存。生产环境中根据需求设定,通常设置在50%以上
- maxmemory-samples:每次选取待删除数据的个数,选取数据时并不会全库扫描,导致严重的性能消耗,降低读写性能。因此采用随机获取数据的方式作为待检测删除数据
- maxmemory-policy:达到最大内存后的,对被挑选出来的数据进行删除的算法
内存淘汰机制
Redis 有两种数据集,一种是设置了过期 key 的集合(volatile),另一种是包含所有 key 的集合(allkeys)。它们都拥有以下这些内存淘汰机制。
检查可能会过期的数据集server.db[i].expires内的数据
- volatile-lru:挑选最近最少使用(最长时间不使用的)的数据淘汰,使用较多
- volatile-lfu:挑选最近使用次数最少的数据淘汰
- volatile-ttl :挑选将要过期的数据淘汰
- volatile-random:任意选择数据淘汰,一般用的少
检测全库数据(所有数据集server.db[i].dict)
- allkeys-lru:挑选最近最少使用的数据淘汰
- allkeys-lfu:挑选最近使用次数最少的数据淘汰
- allkeys-random:任意选择数据淘汰
(1)LRU
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”3。
本质上是把最久未被访问的元素淘汰掉。
(2)Random
淘汰掉随机选取的某些元素。
(3)LFU
LFU(Least frequently used) 最不经常使用,如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小4。
LFU 是选择一段时间内使用次数最少的那个元素,而 LRU 是选择在内存中排在队尾的那个最近没有被使用过的元素,因为如果元素被使用过,那么会被排在队头。
(4)TTL
TTL 是 Time To Live5。当 key 过期,会被马上清除。
放弃数据驱逐
no-enviction(驱逐):禁止驱逐数据(redis4.0中默认策略),会引发错误OOM(Out Of Memory)
maxmemory-policy volatile-lru数据逐出策略配置依据
使用INFO命令输出监控信息,查询缓存 hit 和 miss 的次数,根据业务需求调优Redis配置 。