Google Colab环境下运行
在Colab环境下安装包
使用GPU

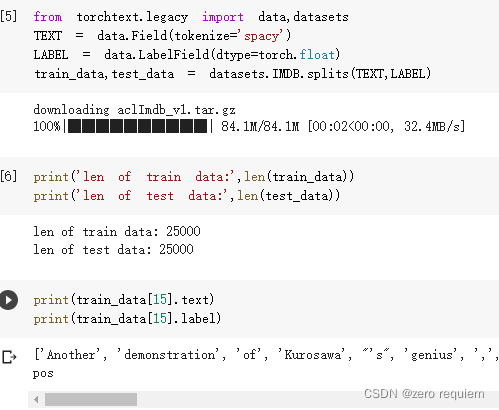
获得训练集与测试集
定义LSTM模型
class RNN(nn.Module):
def __init__(self,vocab_size,embedding_dim,hidden_dim):
super(RNN,self).__init__()
# [vocab_size 10000] => [embedding_dim:100]
self.embedding = nn.Embedding(vocab_size,embedding_dim)
# [embedding_dim 100] => [hidden_dim 256] 两层 双向lstm dropout防止过拟合
self.rnn = nn.LSTM(embedding_dim,hidden_dim,num_layers=2,bidirectional=True,dropout=0.5)
# lstm输出的h层信息[256*2] => 1
self.fc = nn.Linear(hidden_dim*2,1)
self.dropout = nn.Dropout(0.5)
def forward(self,x):
# [seq,b,1] => [seq,b,100]
embedding = self.dropout(self.embedding(x))
# output:[seq,b,hidden*2]
# hidden/h:[num_layers*2,b,hid_dim]
# cell/c:[num_layers*2,b,hid_dim]
output,(hidden,cell) = self.rnn(embedding)
# [num_layers*2,b,hid_dim] => 拼接2个[b,hid_dim] => [b,hid_dim*2]
hidden = torch.cat([hidden[-2],hidden[-1]],dim=1)
hidden = self.dropout(hidden)
# [b,hid_dim*2] => [b,1]
out = self.fc(hidden)
return out
定义训练和评估函数
def train(rnn,iterator,optimizer,criterion):
avg_acc = []
rnn.train()
for i,batch in enumerate(iterator):
# [seq,b] => [b,1] = [b]
pred = rnn(batch.text).squeeze(1)
loss = criterion(pred,batch.label)
acc = binary_acc(pred,batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10==0:
print(i,acc)
avg_acc = np.array(avg_acc).mean()
print('avg_acc',avg_acc)
def binary_acc(preds,y):
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds,y).float()
acc = correct.sum()/len(correct)
return acc
def eval(rnn,iterator,criterion):
avg_acc = []
rnn.eval()
with torch.no_grad():
for batch in iterator:
pred = rnn(batch.text).squeeze(1)
loss = criterion(pred,batch.label)
acc = binary_acc(pred,batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:',avg_acc)
开始训练
- 加载GLoVe预训练模型
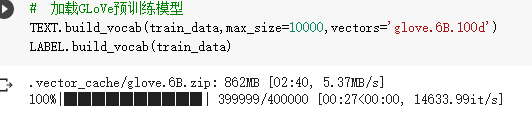
2. 初始化模型 用GLoVe编码的权重 替换 模型的embedding权重
设置batch_size optimizer criterion

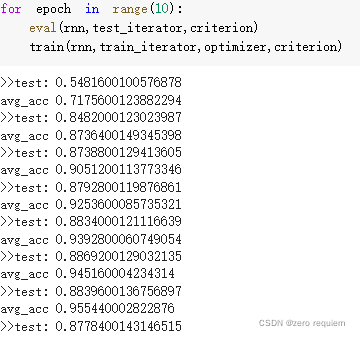
epoch 训练
**关于embedding层的权重替换
用Gensim/GLoVe/Bert预训练获得的词向量进行LSTM训练 会获得更好的性能
可以见这篇blogNLP 预训练
版权声明:本文为weixin_43201090原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。