TableGPT: Few-shot Table-to-Text Generation with Table Structure Reconstruction and Content Matching
摘要
- table2text仍然面临三个挑战:
1)任务所需要的输入结构和自然语言输入的不同
2)缺少表格结构的建模
3)提升文本保真度用更少的和表格矛盾的不正确的表达 - tableGPT解决的方法:
1)首先用带有模版的表格转换模块去用自然语言重写结构化的表格作为GPT2的输入
2)另外我们用两个备用的任务用来保持表格的结构信息:通过GPT2的表征重建表格结构,用文本匹配任务对齐表格和生成文本的信息来提升文本的保真度。 - 实验数据集:Humans、Songs、Books
介绍
关于table2text的任务已经取得了很多的成就,包括WIKIBIO和E2E数据集上这种大数据上都有了很好的表现。但是对于存在的很多少量标签的数据来说,也就是few-shot learning在table2text上还没有完全开发。
另外对于预训练的语言模型来说也同样有了大量的成就(NLP),但是由于上面提到的挑战,在table2text上还没有探索出方法。
背景
任务定义
E=(S,T),其中E表示任务,给定一个S为record的集合,期望生成描述性的文本T。每个record中包含两个元素:属性r i . a r_i.ari.a和值r i . v r_i.vri.v。预训练模型
GPT2
方式
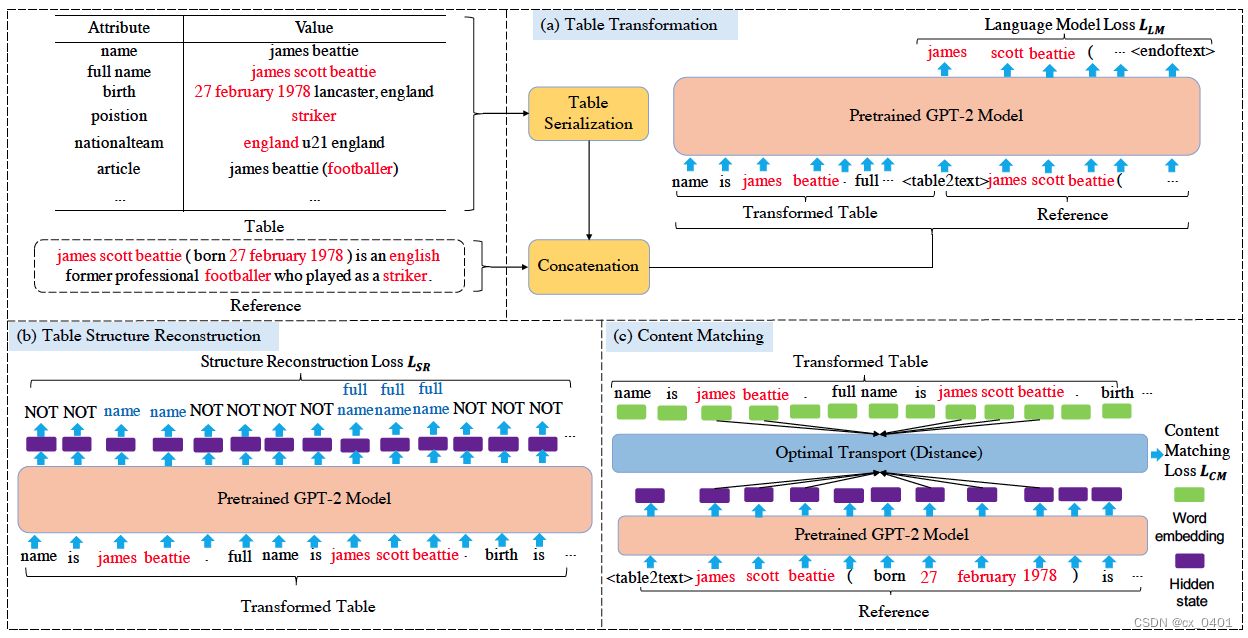
表格转换
这里用一个表格序列化的模版,例如将“name: jack reynolds"转换为"name is jack reynolds",然后再将所有的record连接起来。
在得到序列化的表格之后,我们用一个特殊令牌" <table2text> “将它连接起来,作为一个功能化的令牌,用来编码整个表格信息并作为生成文本的一个开始信号。整个文本用”<endoftext>"来作为结束特殊令牌。用这种方式,我们的模型可以像GPT2一样编码整个结构化表格并且学习去预测目标序列的单词。表格结构重建
在将表格转化为文本的这个过程中我们丧失了表格信息,受前人工作启发,我们的模型将属性名称作为模型的标签去重建结构信息。
具体过程是将序列化的文本在GPT2的最后一层隐藏层对应的每个value的token做一个属性分类。在这个任务的引导下,TableGPT能够被引导编码结构信息。内容匹配
生成流畅的文本也十分重要,通常情况直接copy表格中的文本会导致高流畅度的文本。但是,在transformer中集成一个copy机制是不容易的,因为这样可能破坏模型的表征。
内容匹配任务是显示地匹配表格重要的信息在对应的生成文本中,用一个不匹配的loss去硬性匹配表格和生成文本的信息是不连续的。受到optimal transport(OT)的启发,我们用这个来测量源序列和目标序列之间的距离(保持端到端的训练过程)。
这个计算过程暂存。。。
对于nlg任务来说,OT距离通常是将源序列和整个目标序列进行匹配,但是在table2text中,表格和文本中都有一些冗余的信息,为了应用OT距离,我们只匹配在表格和参考文本中出现过的单词。
最终多任务学习的目标是综合上面两个任务和模型本身的loss