prometheus 监控 k8s pod 容器服务状态
Prometheus+Grafana作为监控K8S的解决方案,大部分都是在K8S集群内部部署,所以监控起来很方便,可以直接调用集群内的cert及各种监控url,但是增加了集群的资源开销,
**需求:**每个 pod 重启/删除时,都能发出告警。要及时和准确
前几期也讲过 报警,可以回顾哦
实现 效果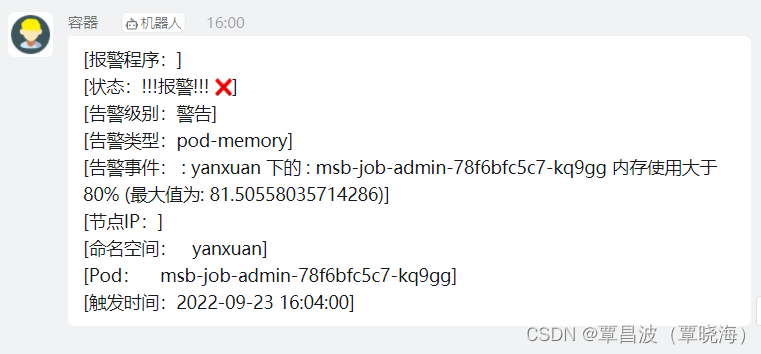
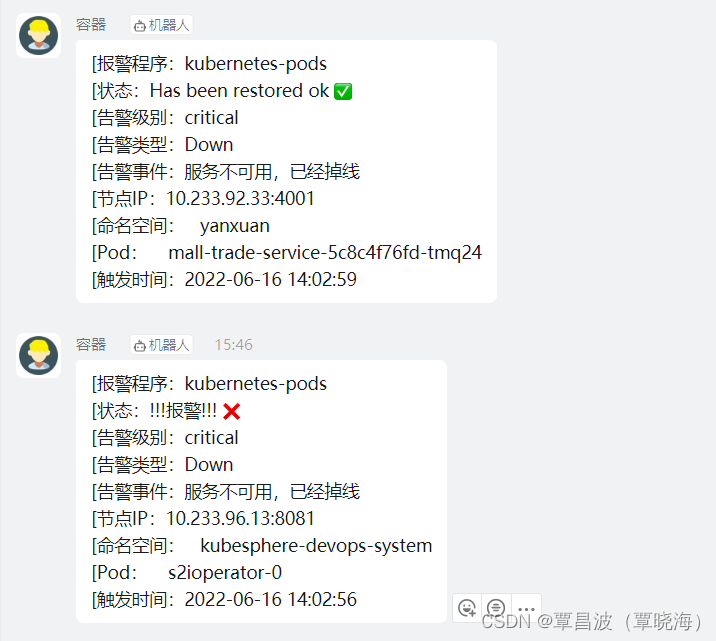
配置 rbac 相关认证
Prometheus 需要访问 Kubernetes 的一些资源对象,所以需要配置 rbac 相关认证,内容如下:
1)创建一个用于Prometheus pod 中的ServiceAccount
2)创建ClusterRole,定义规则权限
3)创建ClusterRoleBinding 将ServiceAccount 与 ClusterRole进行绑定
apiVersion: v1
kind: Namespace
metadata:
name: monitor
labels:
name: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
---
1.配置 prometheus-config
告警规则 和 监控
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
---
告警规则
- name: Down
rules:
- alert: Down
expr: up == 0
for: 30s
labels:
severity: critical
annotations:
description: "服务不可用,已经掉线"
- alert: NodeCPUHigh
expr: (1 - avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100 > 75
for: 5m
labels:
severity: warning
annotations:
description: "{{$labels.instance}}: CPU usage is above 75% (当前值:{{ $value }})"
- alert: NodeCPUIowaitHigh
expr: avg by (instance) (irate(node_cpu_seconds_total{mode="iowait"}[5m])) * 100 > 50
for: 5m
labels:
severity: warning
annotations:
description: "{{$labels.instance}}: CPU iowait usage is above 50% (当前值:{{ $value }})"
- alert: NodeMemoryUsageHigh
expr: (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 90
for: 5m
labels:
severity: warning
annotations:
description: "{{$labels.instance}}: Memory usage is above 90% (当前值:{{ $value }})"
- alert: NodeDiskRootLow
expr: (1 - node_filesystem_avail_bytes{fstype=~"ext.*|xfs",mountpoint ="/"} / node_filesystem_size_bytes{fstype=~"ext.*|xfs",mountpoint ="/"}) * 100 > 80
for: 10m
labels:
severity: warning
annotations:
description: "{{$labels.instance}}: Disk(the / partition) usage is above 80% (当前值:{{ $value }})"
- alert: NodeDiskBootLow
expr: (1 - node_filesystem_avail_bytes{fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{fstype=~"ext.*|xfs",mountpoint ="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
annotations:
description: "{{$labels.instance}}: Disk(the /boot partition) usage is above 80% (当前值:{{ $value }})"
- alert: NodeLoad5High
expr: (node_load5) > (count by (instance) (node_cpu_seconds_total{mode='system'}) * 2)
for: 5m
labels:
severity: warning
annotations:
description: "{{$labels.instance}}: Load(5m) is 2 times the number of CPU cores (当前值:{{ $value }})"
Deployment部署应用
1)将前面创建的pvc和配置文件configMap 作为volume挂载到Prometheus 中
2)在Prometheus中使用前面创建的ServiceAccount
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
securityContext: #指定运行的用户为root
runAsUser: 0
serviceAccountName: prometheus
containers:
- image: prom/prometheus:v2.30.2
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml" #通过volume挂载prometheus.yml
- "--storage.tsdb.path=/prometheus" #通过vlolume挂载目录/prometheus
- "--storage.tsdb.retention.time=24h"
- "--web.enable-admin-api" #控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" #支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
name: http
resources:
requests:
cpu: '1'
memory: 1000Mi
limits:
cpu: '2.5'
memory: 2000Mi
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
- name: rules
mountPath: /etc/prometheus-rules
volumes:
- name: data
emptyDir: {}
- name: config-volume
configMap:
name: prometheus-config
- name: rules
configMap:
name: prometheus-rules
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30003
然后需要在你的k8s容器服务里添加
```bash
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "$JAR_PORD"
运行一个 demo
$a=web-admin
kubectl apply -f demo.yaml
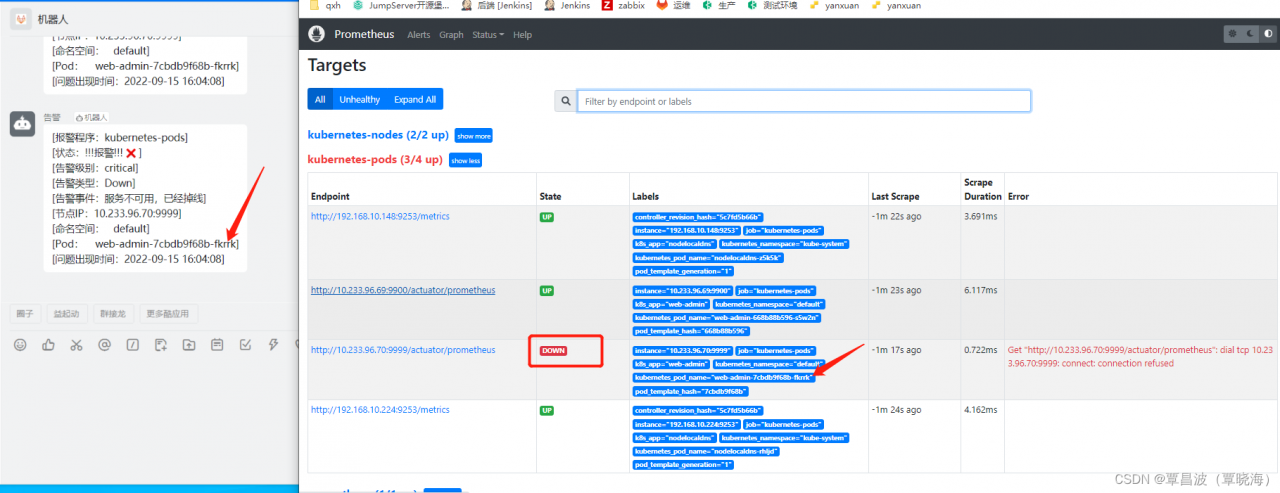
修复问题后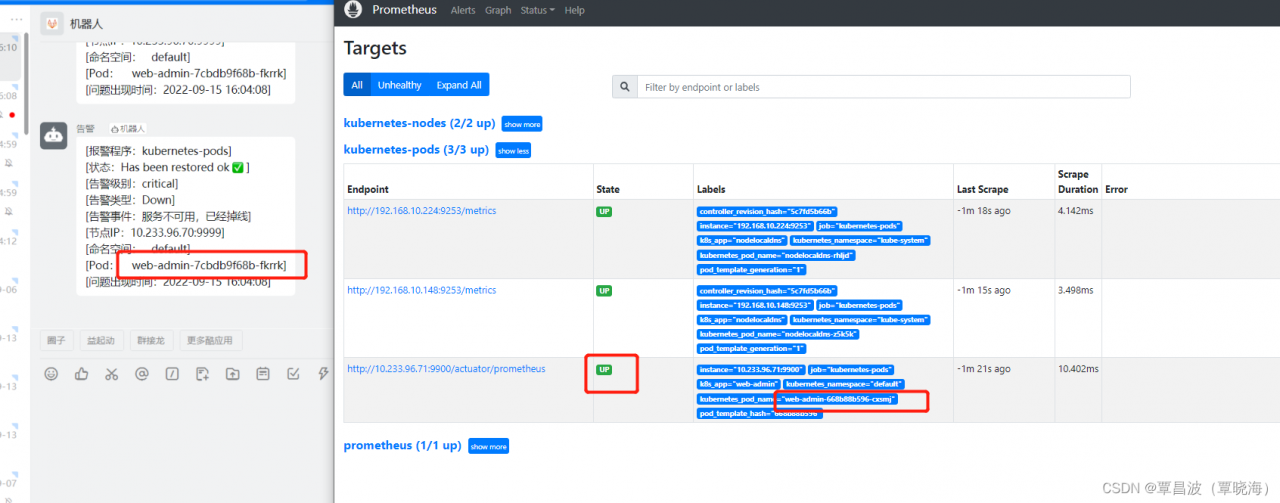
版权声明:本文为qq_40178286原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。