目录
任务简介:
学习网络模型中采用的神经网络层,包括卷积层,池化层,全连接层和激活函数层,学会如何区分二维卷积和三维卷积;
详细说明:
本节学习池化层,全连接层和激活函数层,在池化层中有正常的最大值池化,均值池化,还有图像分割任务中常用的反池化——MaxUnpool,在激活函数中会学习Sigmoid,Tanh和Relu,以及Relu的各种变体,如LeakyReLU,PReLU, RReLU。
一、池化层——Pooling Layer
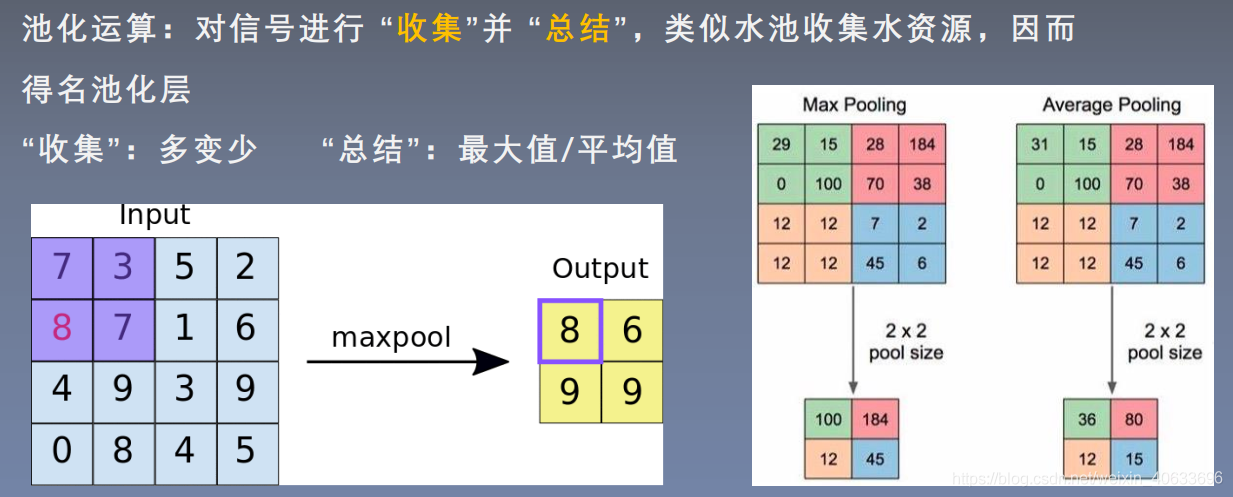
池化的作用:冗余信息剔除,减少后面的计算量。
1.最大值池化
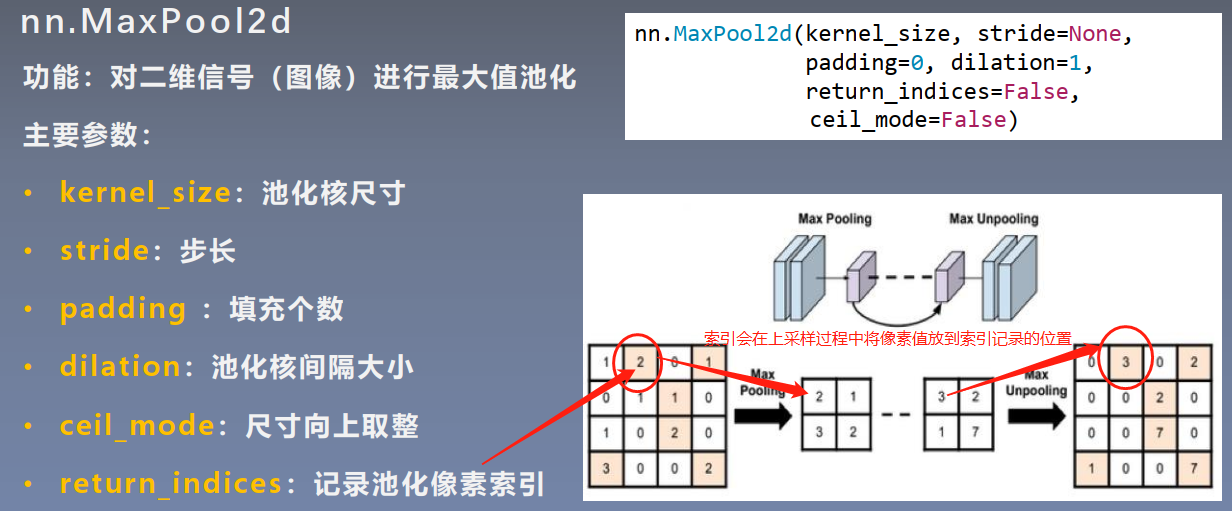
代码:
# -*- coding: utf-8 -*-
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import torch
import random
import numpy as np
import torchvision
import torch.nn as nn
from torchvision import transforms
from matplotlib import pyplot as plt
from PIL import Image
path_tools = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "tools", "common_tools.py"))
assert os.path.exists(path_tools), "{}不存在,请将common_tools.py文件放到 {}".format(path_tools, os.path.dirname(path_tools))
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed, transform_invert
set_seed(1) # 设置随机种子
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255
# convert to tensor
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
img_tensor.unsqueeze_(dim=0) # C*H*W to B*C*H*W
# ================================= create convolution layer ==================================
# ================ maxpool
flag = 1
# flag = 0
if flag:
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = maxpool_layer(img_tensor)
# ================ avgpool
# flag = 1
flag = 0
if flag:
avgpoollayer = nn.AvgPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = avgpoollayer(img_tensor)
# ================ avgpool divisor_override
# flag = 1
flag = 0
if flag:
img_tensor = torch.ones((1, 1, 4, 4))
avgpool_layer = nn.AvgPool2d((2, 2), stride=(2, 2), divisor_override=3)
img_pool = avgpool_layer(img_tensor)
print("raw_img:\n{}\npooling_img:\n{}".format(img_tensor, img_pool))
# ================ max unpool
# flag = 1
flag = 0
if flag:
# pooling
img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float)
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True)
img_pool, indices = maxpool_layer(img_tensor)
# unpooling
img_reconstruct = torch.randn_like(img_pool, dtype=torch.float)
maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2))
img_unpool = maxunpool_layer(img_reconstruct, indices)
print("raw_img:\n{}\nimg_pool:\n{}".format(img_tensor, img_pool))
print("img_reconstruct:\n{}\nimg_unpool:\n{}".format(img_reconstruct, img_unpool))
# ================ linear
# flag = 1
flag = 0
if flag:
inputs = torch.tensor([[1., 2, 3]])
linear_layer = nn.Linear(3, 4)
linear_layer.weight.data = torch.tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]])
linear_layer.bias.data.fill_(0.5)
output = linear_layer(inputs)
print(inputs, inputs.shape)
print(linear_layer.weight.data, linear_layer.weight.data.shape)
print(output, output.shape)
# ================================= visualization ==================================
print("池化前尺寸:{}\n池化后尺寸:{}".format(img_tensor.shape, img_pool.shape))
img_pool = transform_invert(img_pool[0, 0:3, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_pool)
plt.subplot(121).imshow(img_raw)
plt.show()输出:
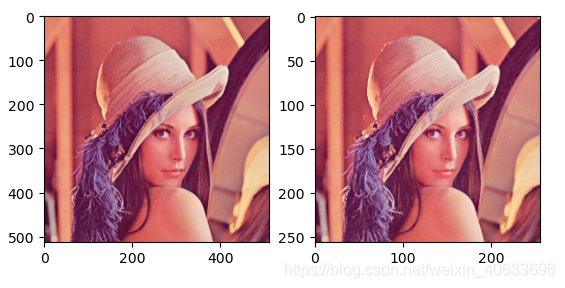
池化前尺寸:torch.Size([1, 3, 512, 512])
池化后尺寸:torch.Size([1, 3, 256, 256])
2.平均值池化

代码:
# ================ avgpool
flag = 1
# flag = 0
if flag:
avgpoollayer = nn.AvgPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = avgpoollayer(img_tensor)输出:
池化前尺寸:torch.Size([1, 3, 512, 512])
池化后尺寸:torch.Size([1, 3, 256, 256])
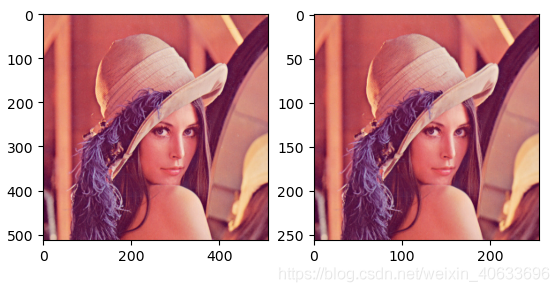
相对于最大值池化,平均值池化亮度稍小,因为最大值池化取的是区域最大值。
将平均值池化的divisor_override值设置为3,代码:
# ================ avgpool divisor_override
flag = 1
# flag = 0
if flag:
img_tensor = torch.ones((1, 1, 4, 4))
avgpool_layer = nn.AvgPool2d((2, 2), stride=(2, 2), divisor_override=3)
img_pool = avgpool_layer(img_tensor)
print("raw_img:\n{}\npooling_img:\n{}".format(img_tensor, img_pool))输出:
raw_img:
tensor([[[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]]])
pooling_img:
tensor([[[[1.3333, 1.3333],
[1.3333, 1.3333]]]])3.最大值上采样池化
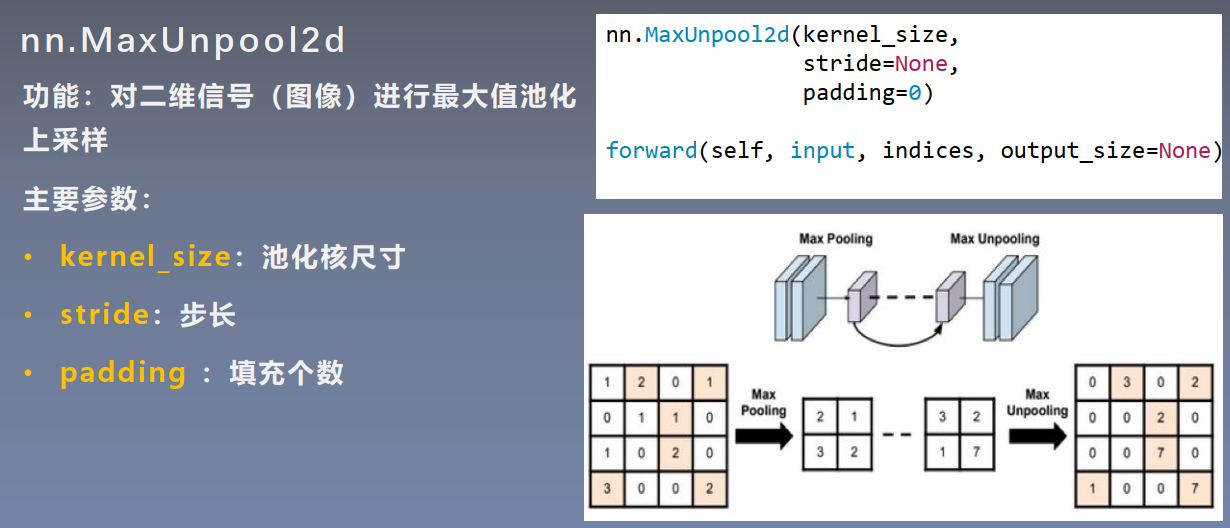
上采样过程见1.中PPT内容。
代码:
# ================ max unpool
flag = 1
# flag = 0
if flag:
# pooling
img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float)
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True)
img_pool, indices = maxpool_layer(img_tensor)
# unpooling
img_reconstruct = torch.randn_like(img_pool, dtype=torch.float)
maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2))
img_unpool = maxunpool_layer(img_reconstruct, indices)
print("raw_img:\n{}\nimg_pool:\n{}".format(img_tensor, img_pool))
print("img_reconstruct:\n{}\nimg_unpool:\n{}".format(img_reconstruct, img_unpool))输出:
raw_img:
tensor([[[[0., 4., 4., 3.],
[3., 3., 1., 1.],
[4., 2., 3., 4.],
[1., 3., 3., 0.]]]])
img_pool:
tensor([[[[4., 4.],
[4., 4.]]]])
img_reconstruct:
tensor([[[[-1.0276, -0.5631],
[-0.8923, -0.0583]]]])
img_unpool:
tensor([[[[ 0.0000, -1.0276, -0.5631, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[-0.8923, 0.0000, 0.0000, -0.0583],
[ 0.0000, 0.0000, 0.0000, 0.0000]]]])二、线性层(全连接层)——Linear Layer
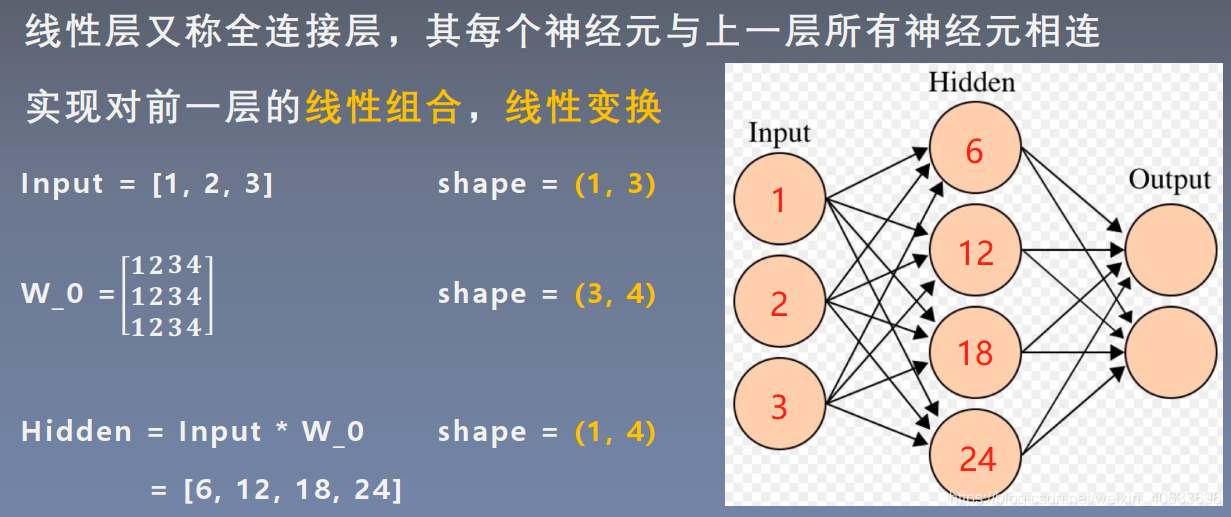
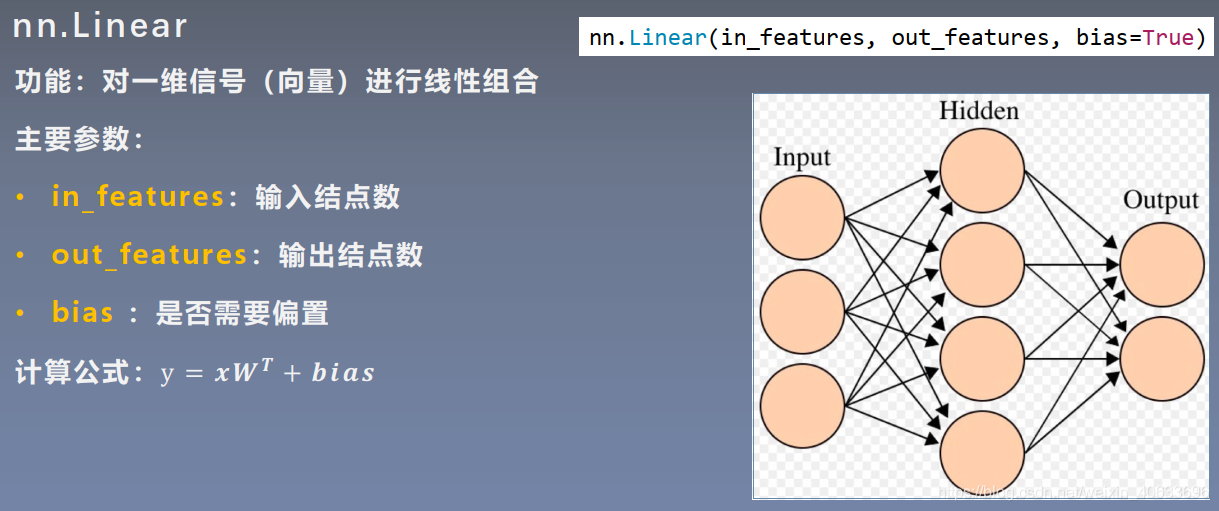 代码:
代码:
偏置设为0.5
# ================ linear
flag = 1
# flag = 0
if flag:
inputs = torch.tensor([[1., 2, 3]])
linear_layer = nn.Linear(3, 4)
linear_layer.weight.data = torch.tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]])
linear_layer.bias.data.fill_(0.5)
output = linear_layer(inputs)
print(inputs, inputs.shape)
print(linear_layer.weight.data, linear_layer.weight.data.shape)
print(output, output.shape)输出:
tensor([[1., 2., 3.]]) torch.Size([1, 3])
tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]]) torch.Size([4, 3])
tensor([[ 6.5000, 12.5000, 18.5000, 24.5000]], grad_fn=<AddmmBackward>) torch.Size([1, 4])三、激活函数层——Activation Layer
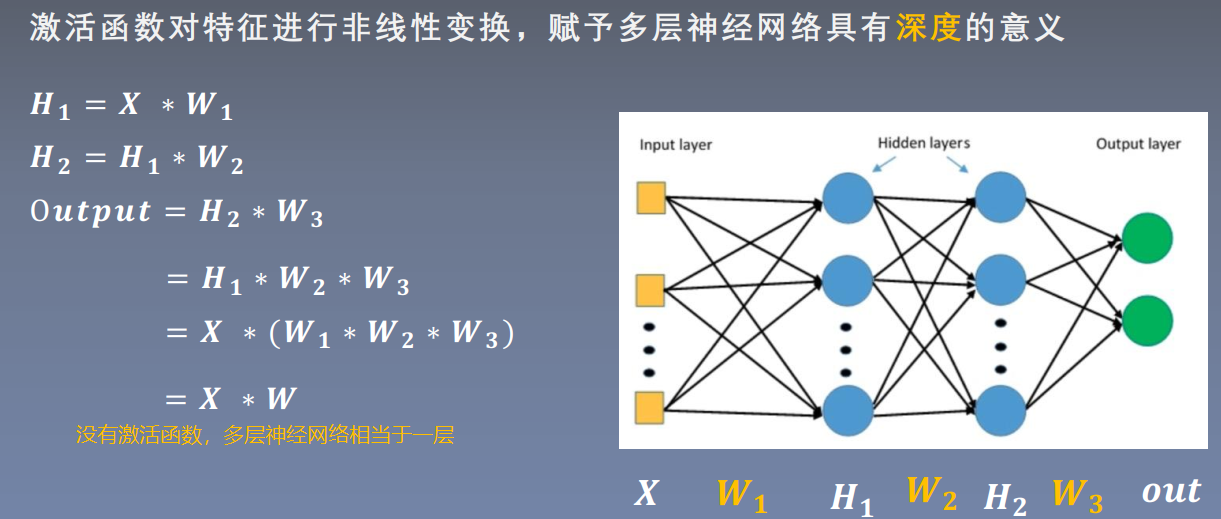
1.Sigmoid
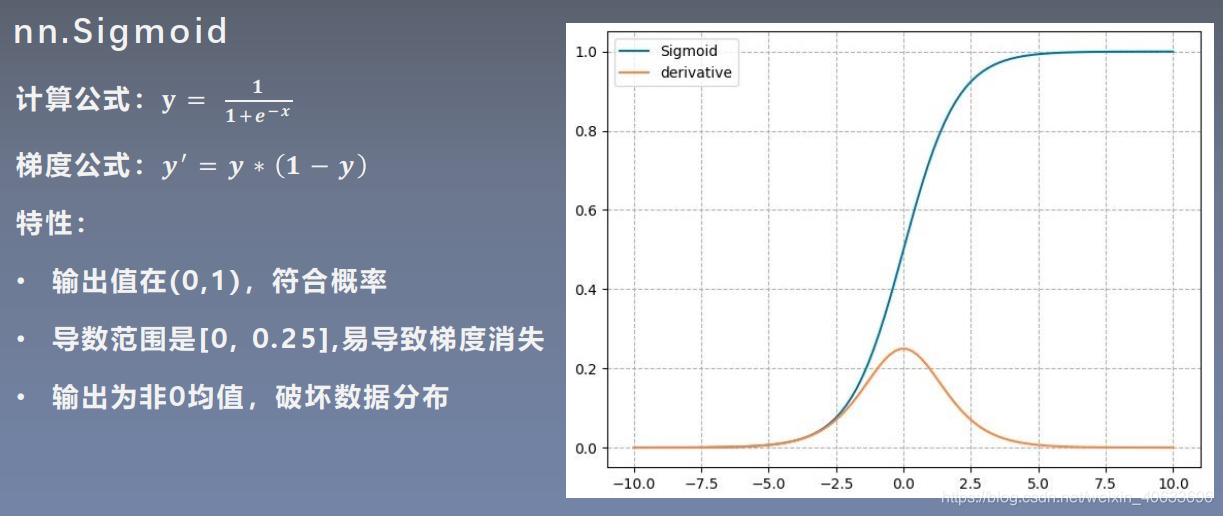
2.tanh
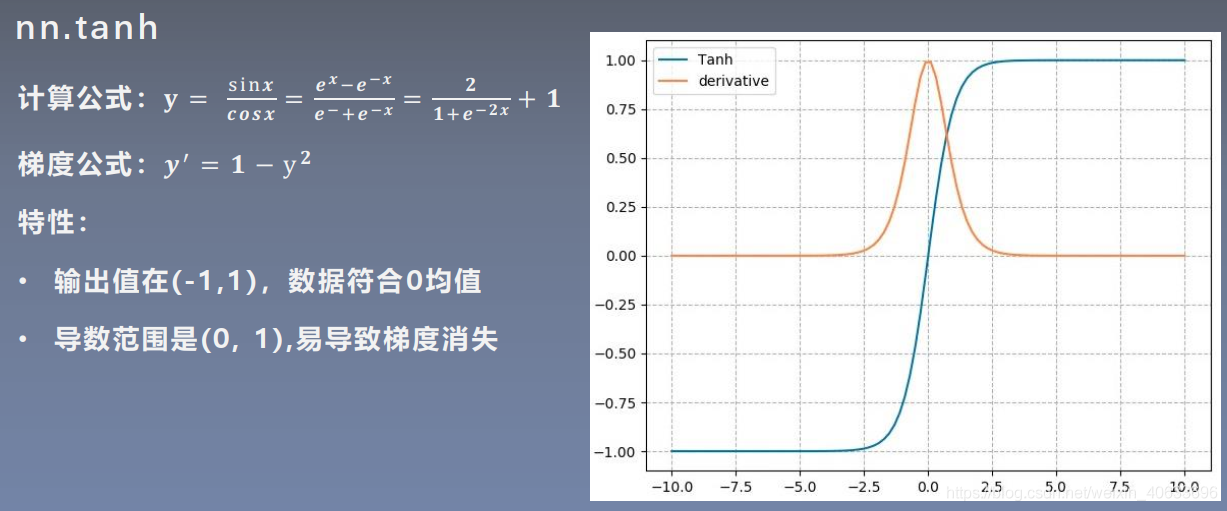 3.ReLU
3.ReLU
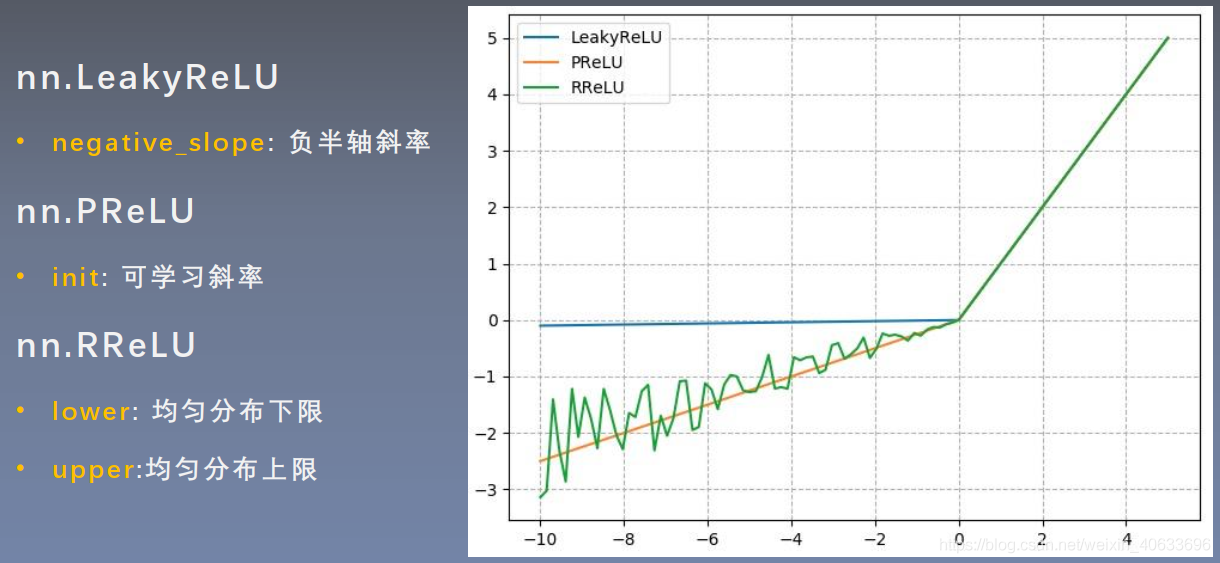
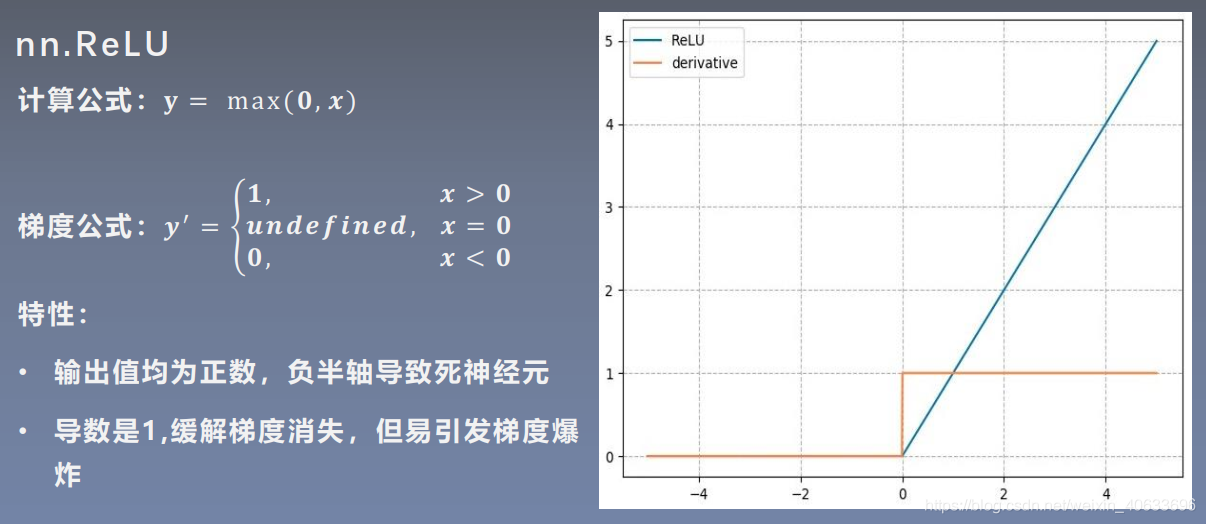 4.ReLu的几种变形
4.ReLu的几种变形
版权声明:本文为weixin_40633696原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。