1. KMeans简介
KMeans是一种简单的聚类方法,它使用每个样本到聚类中心的距离作为度量来决定簇。其中
2. KMeans模型
KMeans
KMeans算法较为简单,记K个簇中心为
对损失函数求偏导,可得
令导数等于0,解得
即令每个簇的均值作为质心。
KMeans代码如下:
def 其中的adjustCluster()函数,为确定了初始的质心后的调整过程,功能是最小化损失函数
def 2分KMeans
由于KMeans可能收敛于局部最小值,为了解决这一问题引入2分KMeans。2分KMeans原理是先将所有样本视为一个大簇,然后将其一分为二;然后选择其中一个继续划分,直到簇的个数达到了指定的
选择被划分的簇流程为:将
适合划分的簇为
然后,如此反复,直到质心个数等于指定的
代码如下:
def KMeans++
KMeans 方法由于初始的质心选择对于聚类算法具有很大的影响,因此引入KMeans++的算法。其原理为:假设现在有
则在选取第
然后计算每个样本被选为下一个聚类中心的概率
然后采用轮盘法选出下一个聚类中心。
def 3. 总结与分析
聚类算法收敛后可以使用一些方法来调整质心。对于
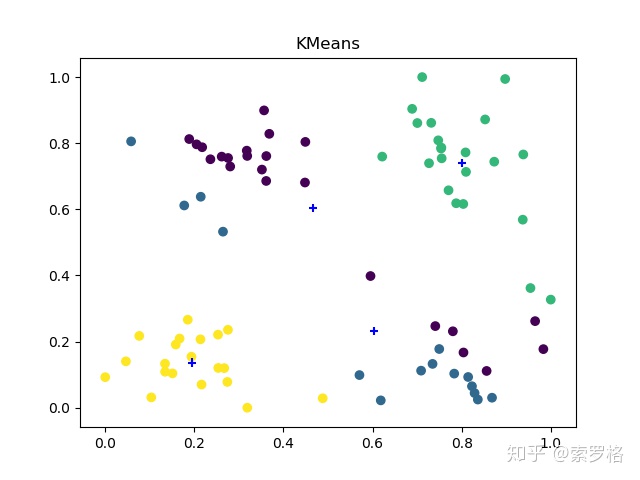
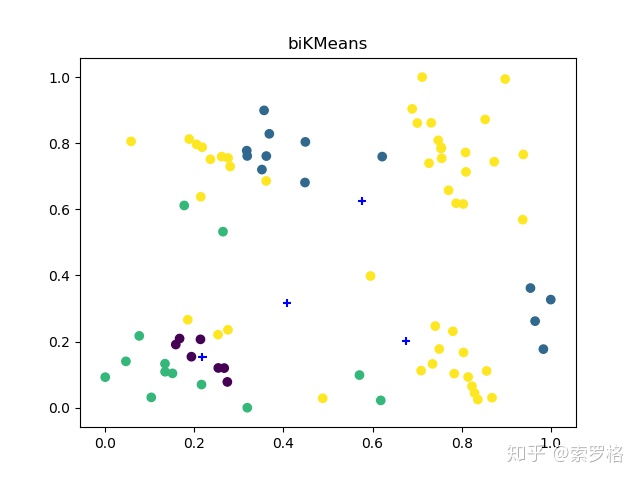
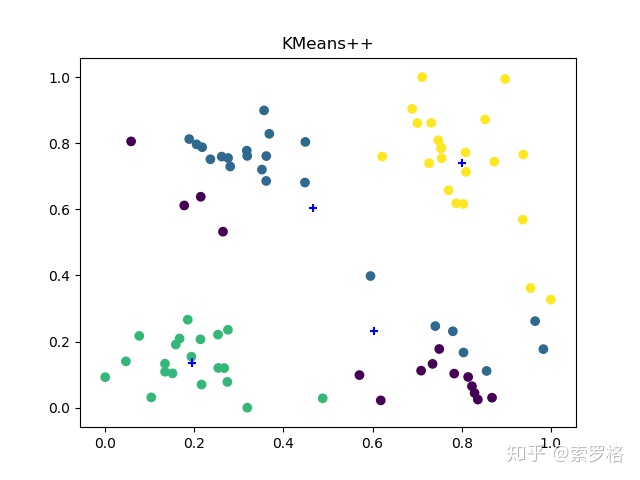

可以发现KMeans++的算法运行效果最好,这三种方法运行时间差不多。
本文相关代码和数据集:
Ryuk17/MachineLearninggithub.com
参考文献
[1] Peter Harrington, Machine Learning IN ACTION
[2] Andrew Ng, CS229 Lecture notes