决策树原理与代码
本文整理自《统计学习方法》第二版
1. 决策树模型与学习
定义5.1(决策树):分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点,内部结点表示一个特征或属性,叶结点表示一个类。
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点:这时,每个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
决策树与条件概率分布: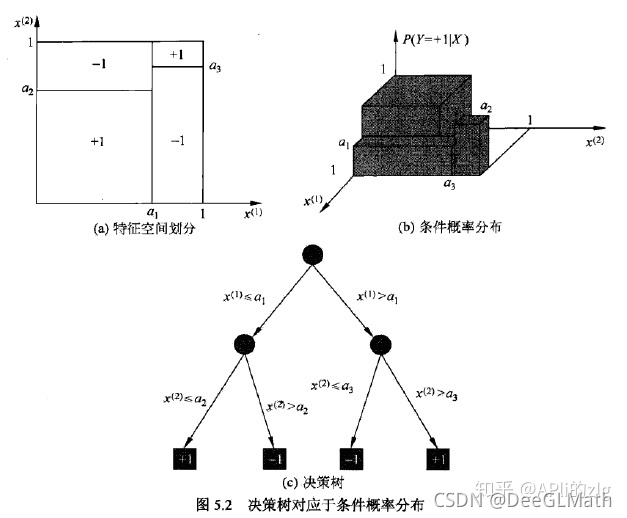
决策树学习:
假设给定训练数据集:
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } (1) D=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} \tag 1D={(x1,y1),(x2,y2),...,(xN,yN)}(1)
其中,x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( n ) ) T x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(n)})^Txi=(xi(1),xi(2),...,xi(n))T为输入实例(特征向量),n nn为特征个数,y i ∈ { 1 , 2 , . . . , K } y_i \in \{1,2,...,K\}yi∈{1,2,...,K}为类标记,i = 1 , 2 , . . . , N i=1,2,...,Ni=1,2,...,N,N NN为样本容量。决策树学习的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树的本质上是从训练样本数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有很多个,也可能一个都没有。我们需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。我们选择的条件概率模型应该不仅对训练数据由很好的拟合,而且对未知数据有很好的预测。
2. 特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。
通常,特征选择的准则是信息增益或信息增益比。
给出一个示例:(贷款申请训练数据表)
+----+--------+-----------+-------------+--------------+----------+
| ID | Age | job_state | house_state | credit_state | category |
+----+--------+-----------+-------------+--------------+----------+
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
+----+--------+-----------+-------------+--------------+----------+
希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
2.1 信息增益
熵的含义:表示随机变量不确定性的度量。
设X XX是一个取有限个值得离散随机变量,其概率分布为:
P ( X = x i ) = p i , i = 1 , 2 , . . . , n (2) P(X=x_i)=p_i,i=1,2,...,n \tag 2P(X=xi)=pi,i=1,2,...,n(2)
则随机变量X XX的熵定义为:
H ( X ) = − ∑ i = 1 n p i log ( p i ) (3) H(X)=-\sum_{i=1}^{n} p_i \log(p_i) \tag 3H(X)=−i=1∑npilog(pi)(3)
对于上式,有如下特殊的规定:
若p i = 0 p_i=0pi=0,则定义0 log 0 = 0 0\log 0=00log0=0。通常情况下,式( 3 ) (3)(3)中的对数以2为底数或以e ee为底(自然对数),这时熵的单位分别为比特(bit)或纳特(nat)。由定义知,熵只依赖于X XX的分布,而与X XX的取值无关,所以也可将X XX的熵记作H ( p ) H(p)H(p),即:
H ( p ) = − ∑ i = 1 n p i log ( p i ) (4) H(p)=-\sum_{i=1}^{n} p_i \log(p_i) \tag 4H(p)=−i=1∑npilog(pi)(4)
熵越大,随机变量的不确定性就越大。从定义可验证:
0 ≤ H ( p ) ≤ log ( n ) (5) 0 \leq H(p) \leq \log(n) \tag 50≤H(p)≤log(n)(5)
设有随机变量( X , Y ) (X,Y)(X,Y),其联合概率分布为:
P ( X = x i , Y = y j ) = p i j , i = 1 , 2 , . . . , n ; j = 1 , 2 , . . . , m (6) P(X=x_i,Y=y_j)=p_{ij},i=1,2,...,n;j=1,2,...,m \tag 6P(X=xi,Y=yj)=pij,i=1,2,...,n;j=1,2,...,m(6)
条件熵H ( Y ∣ X ) H(Y|X)H(Y∣X)表示在已知随机变量X XX的条件下随机变量Y YY的不确定性。随机变量X XX给定的条件下随机变量Y YY的条件熵H ( Y ∣ X ) H(Y|X)H(Y∣X),定义为X XX给定条件下Y YY的条件概率分布的熵对X XX的数学期望:
H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) (7) H(Y|X)=\sum_{i=1}^{n} p_iH(Y|X=x_i) \tag 7H(Y∣X)=i=1∑npiH(Y∣X=xi)(7)
这里,p i = P ( X = x i ) , i = 1 , 2 , . . . , n p_i=P(X=x_i),i=1,2,...,npi=P(X=xi),i=1,2,...,n。
(信息增益)特征A AA对训练数据集D DD的信息增益g ( D , A ) g(D,A)g(D,A),定义为集合D DD的经验熵H ( D ) H(D)H(D)与特征A AA给定条件下D DD的经验条件熵H ( D ∣ A ) H(D|A)H(D∣A)之差,即:
g ( D , A ) = H ( D ) − H ( D ∣ A ) (8) g(D,A)=H(D)-H(D|A) \tag 8g(D,A)=H(D)−H(D∣A)(8)
差值越大,代表选择该特征值更好
设训练数据集为D DD,∣ D ∣ |D|∣D∣表示其样本容量,即样本个数。设有K KK个类C k C_kCk,k = 1 , 2 , . . . , K k=1,2,...,Kk=1,2,...,K,∣ C k ∣ |C_k|∣Ck∣表示属于类C k C_kCk的样本个数,∑ i = 1 K ∣ C k ∣ = ∣ D ∣ \sum_{i=1}^{K}|C_k|=|D|∑i=1K∣Ck∣=∣D∣。设特征A AA有n nn个不同的取值{ a 1 , a 2 , . . . , a n } \{a_1,a_2,...,a_n\}{a1,a2,...,an},根据特征A AA的取值将D DD划分为n nn个子集D 1 , D 2 , . . . , D n D_1,D_2,...,D_nD1,D2,...,Dn,∣ D i ∣ |D_i|∣Di∣为D i D_iDi的样本个数,∑ i = 1 n ∣ D i ∣ = ∣ D ∣ \sum_{i=1}^{n}|D_i|=|D|∑i=1n∣Di∣=∣D∣。记子集D i D_iDi中属于类C k C_kCk的样本的集合为D i k D_{ik}Dik,即D i k = D i ∩ C k D_{ik}=D_i \cap C_kDik=Di∩Ck,∣ D i k ∣ |D_{ik}|∣Dik∣为D i k D_{ik}Dik的样本个数。信息增益的算法如下:
输入:训练数据集D DD和特征A AA;
输出:特征A AA对训练数据集D DD的信息增益g ( D , A ) g(D,A)g(D,A)。
- 计算数据集D DD的经验熵H ( D ) H(D)H(D):
H ( D ) = − ∑ i = 1 n ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ (9) H(D)=-\sum_{i=1}^{n} \frac{|C_k|}{|D|} \log_2\frac{|C_k|}{|D|} \tag 9H(D)=−i=1∑n∣D∣∣Ck∣log2∣D∣∣Ck∣(9) - 计算特征A AA对数据集D DD的经验条件熵H ( D ∣ A ) H(D|A)H(D∣A):
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ i = 1 K ∣ D i k ∣ ∣ D i ∣ log 2 ∣ D i k ∣ ∣ D i ∣ (10) H(D|A)=\sum_{i=1}^{n} \frac{|D_i|}{|D|}H(D_i)=-\sum_{i=1}^{n} \frac{|D_i|}{|D|}\sum_{i=1}^{K} \frac{|D_{ik}|}{|D_i|} \log_2 \frac{|D_{ik}|}{|D_i|} \tag {10}H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣i=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣(10) - 计算信息增益:
g ( D , A ) = H ( D ) − H ( D ∣ A ) (11) g(D,A)=H(D)-H(D|A) \tag {11}g(D,A)=H(D)−H(D∣A)(11)
2.2 信息增益比
特征A AA对训练数据集D DD的信息增益比g R ( D , A ) g_R(D,A)gR(D,A)定义为其信息增益g ( D , A ) g(D,A)g(D,A)与训练数据集D DD关于特征A AA的值的熵H A ( D ) H_A(D)HA(D)之比,即:
g R ( D , A ) = g ( D , A ) H A ( D ) (12) g_R(D,A)=\frac{g(D,A)}{H_A(D)} \tag {12}gR(D,A)=HA(D)g(D,A)(12)
其中,H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ log 2 ∣ D i ∣ ∣ D ∣ H_A(D)=-\sum_{i=1}^{n} \frac{|D_i|}{|D|} \log_2 \frac{|D_i|}{|D|}HA(D)=−∑i=1n∣D∣∣Di∣log2∣D∣∣Di∣,n nn是特征A AA取值的个数。
代码:(采用贷款申请训练数据表)
# 定义信息熵函数
def empirical_entropy(data):
p_i = pd.value_counts(data) / len(data)
return sum(np.log2(p_i) * p_i * (-1))
# 定义条件熵函数
def empirical_conditional_entropy(data,strA,strD):
a = data.groupby(strA).apply(lambda x: empirical_entropy(x[strD]))
b = pd.value_counts(data[strA]) / len(data[strD])
c = sum(a*b)
return c
# 定义信息增益函数
def information_gain(data,strA,strD):
return empirical_entropy(data[strD]) - empirical_conditional_entropy(data,strA,strD)
# 定义信息增益比函数
def information_gain_ratio(data,strA,strD):
return information_gain(data,strA,strD) / empirical_entropy(data[strA])
# 选择最优特征
K = 'category'
Ai = list(df.columns[1:5])
for i in Ai:
print('g(D,',i,'): ',information_gain(df,i,K)) # 偏向于选择取值较多的特征的问题
# print('gR(D,',i,'): ',information_gain_ratio(df,i,K))