目录
1.单链表基础知识
1.1线性表链式存储结构的特点
用一组任意的存储单元存储线性表的数据元素。
- 存储结点的地址可以连续或不连续
- 逻辑上相邻的数据元素在物理上不一定相邻
为此,对线性表中的每一个数据元素,都需用两部分来存储:
- 一部分用于存放数据元素本身的信息,称为数据域(Data Field);
- 另一部分用于存放直接前驱或直接后继的地址(指针),称为指针域(Link Field)。
1.2 与链式存储有关的术语
- 结点(Node):数据元素的存储映像,由数据域和指针域两部分组成

- 链表: n 个结点通过指针域链结而成的线性表
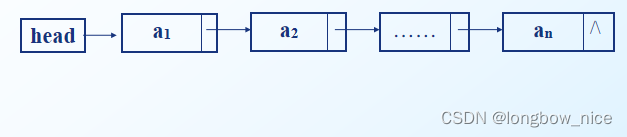
- 首元结点:是指链表中存储第一个数据元素a1的结点
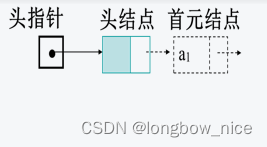
- 头结点:是在链表的首元结点之前附设的一个结点,其指针域指向首元结点,数据域可以不存储信息,不计入链表长度
- 头指针:指向链表中第一个结点(为头结点或首元结点)的指针
1.3链表的类型
- 单链表:结点只有一个指针域的链表,也称线性链表。
- 双链表:有两个指针域的链表
- 循环链表:首尾相接的链表
1.4表示空表
无头结点:头指针为NULL时
有头结点:当头结点的指针域为空时
1.5设置头结点的好处
- 便于首元结点的处理:增加了头结点后,首元结点的地址保存在头结点的指针域中,则对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理
- 便于空表和非空表的统一处理:增加头结点后,无论链表是否为空,头指针都是指向头结点的非空指针。 对于不带头结点的单链表,插入或删除操作需要区分操作的位置是第一个结点还是其他结点。两种情况的操作不同,第一种情况需要更改头指针。
2. 单链表代码实现(附源码)
上代码:
TODO:代码的258行比较有意思,以后看能不能知道为啥
/*
* 单链表表示和实现(都带头节点)
* 以图书管理项目为例
*
* @Author: longbow_nice
* @CreatedTime: 2022/7/9
*/
#include<iostream>
#include<string>
#include<iomanip>
#include<fstream>
using namespace std;
#define OK 1
#define ERROR 0
#define OVERFLOW -2 //含义为运算过程中出现了上溢,即运算结果超出了运算变量所能存储的范围。
#define MAXSIZE 100 //链表最大长度
typedef int Status; //函数名返回值类型
typedef int ElemType; //数据类型
struct Book {
string id; //IBSN
string name; //书名
double price; //价格
};
typedef struct LNode {
Book data; //数据域
struct LNode* next; //指针域
}LNode,*LinkList;
//初始化单链表L
Status InitList(LinkList& L) {
L = new LNode; //生成新结点作为头结点,用头指针L指向头结点
L->next = NULL; 头结点的指针域置空
return OK;
}
//销毁单链表L
Status DestroyList(LinkList& L) {
LNode* p;
while (L) { //从头指针开始一次释放内存空间
p = L;
L = L->next;//如果L已经指向了最后一个节点,此时这条语句能运行老结果是啥?L的值是啥?
delete p;
}
cout << "销毁成功!" << endl;
return OK;
}
//清空单链表L
Status ClearList(LinkList& L) {
LNode* p,*q;
p = L->next;
while (p) { //p没到末尾
q = p->next;
delete p;
p = q;
}
L->next = NULL;
cout << "清空成功!" << endl;
return OK;
}
//求单链表L的长度
int GetLength(LinkList L) {
int length=0;
LNode* p=L->next;
while (p) {
length++;
p = p->next;
}
return length;
}
//判断单链表L是否为空
bool ListEmpty(LinkList L) {
return L->next == NULL;
}
//Book e有影响吗?
//取值
//获取单链表L中的第i个元素内容
Status GetElem(LinkList L, int j, Book& e) {
if(j<1 || j>GetLength(L)) {
return ERROR;
}
int counter = 1;
LNode* p=L->next;
while (counter < j) { //顺链域向后扫描
p = p->next;
counter++;
}
e = p->data;
return OK;
}
//受到查找算法LocateElem的启示,重载一下本取值算法GetElem
LNode* GetElem(LinkList L, int j) {
if (j < 1) {
return NULL;
}
int counter = 1;
LNode* p = L->next;
while (counter < j && p) { //顺链域向后扫描,直到p指向第j个元素或p为空
p = p->next;
counter++;
}
return p;//获取成功返回所需的结点地址p,获取失败p为NULL
}
//检索(查找)
//查找价格为price的图书位置
LNode* LocateElem(LinkList L, double price) { //链表,所以返回一个LNode类型的一个指针,方便打印此节点数据
LNode* p=L->next;
while (p&&p->data.price != price) { 顺链域向后扫描,直到p为空或p所指结点的数据域等于e
p = p->next;
}
return p; //查找成功返回值为e的结点地址p,查找失败p为NULL
}
//插入
//在第j个位置之前插入新的元素e
Status ListInsert(LinkList& L, int j, Book e) {
if (j<1 || j>(GetLength(L) + 1)) {
return ERROR;
}
LNode* p = L;
LNode* q = new LNode;
q->data = e;
int counter = 0;
while (counter < j ) {
if (counter + 1 == j) {
q->next = p->next;
p->next = q;
break;
}
else {
counter++;
p = p->next;
}
}
return OK;
}
//如果不调用GetLength的话,算法这样写
Status ListInsert1(LinkList& L, int j, Book e) {
int counter = 0;
LNode* p, *q;
p = L;
while (p && counter < j-1) { //查找第j-1个结点,p指向该结点
p = p->next;
counter++;
}
if (!p || j < counter) { //j空表、j>(GetLength+1) || j<0
return ERROR;
}
q = new LNode;
q->data = e;
q->next = p->next;
p->next = q;
return OK;
}
//删除
//删除单链表L中第i个数据元素
Status ListDelete(LinkList& L, int j) {
if (j<1 || j>GetLength(L)) {
return ERROR;
}
LNode* p = L;
LNode* q=new LNode;
int location = 0;
while (location < j) {
if (location + 1 == j) {
q->next = p->next;
p->next = q->next;
break;
}
else {
location++;
p = p->next;
}
}
delete q;
return OK;
}
//如果不调用GetLength的话,算法这样写
Status ListDelete1(LinkList& L, int j) {
int counter = 0;
LNode* p, *q;
p = L;
while (p->next && counter < j - 1) { //查找第j个结点(被删除节点),p指向该结点
p = p->next;
counter++;
}
if (!p->next || j < counter) { //j空表、j>GetLength || j<0
return ERROR;
}
q = p->next;
p->next = q->next;
delete q;
return OK;
}
//后插法建立单链表
Status ListCreate(LinkList& L) {
int i = 0;
string head1, head2, head3;
fstream file;
file.open("book.txt");
if (!file) {
cout << "打开文件失败!" << endl;
exit(ERROR);
}
file >> head1 >> head2 >> head3;
LNode* p = L,*q;
while (!file.eof()) {
q = new LNode;
file >> q->data.id >> q->data.name >> q->data.price;
q->next = NULL;
p->next = q;
p = q;
}
cout << "输入 book.txt 信息完毕" << endl;
file.close();
return OK;
}
//输出单链表
void ListPrint(LinkList L) {
LNode* p = L->next;
while (p) {
cout << left << setw(15) << p->data.id << "\t";
cout << left << setw(20) << p->data.name << "\t";
cout << left << setw(10) << p->data.price << endl;
p = p->next;
}
}
int main() {
cout << "1. 初始化单链表" << endl;
cout << "2. 读取文件建立单链表" << endl;
cout << "3. 销毁单链表" << endl;
cout << "4. 清空单链表" << endl;
cout << "5. 单链表长度" << endl;
cout << "6. 判断单链表是否为空" << endl;
cout << "7. 获取元素" << endl;
cout << "8. 查找元素" << endl;
cout << "9. 插入一个元素" << endl;
cout << "10. 删除某一个元素 " << endl;
cout << "11. 输出单链表" << endl;
cout << "0. 退出" << endl;
LinkList L;
/*
* 这里的L = new LNode;
* vs中
* 这里还必须把L初始化一下
*否则289行使用GetLength(L),以及之后每个没有把参数L设为引用类型的函数 时运行不了
* 或者时不要这一句,把每个没有把参数L设为引用类型的函数中设置成引用类型(L前加上&)
*
*但是 在codeblocks中就可以运行,要不要这一句无所谓
*/
L = new LNode;
int temp, location = 0, choice = -1;
Book e;
while (choice != 0) {
cout << endl << "请选择: ";
cin >> choice;
switch (choice) {
case 1:;
if (InitList(L)) {
cout << "单链表初始化成功!" << endl;
}
else {
cout << "单链表初始化!" << endl;
}
break;
case 2:
ListCreate(L);
break;
case 3:
DestroyList(L);
break;
case 4:
ClearList(L);
break;
case 5:
cout << "单链表长度:" << GetLength(L) << endl;
break;
case 6:
if (ListEmpty(L)) {
cout << "单链表为空!" << endl;
}
else {
cout << "单链表不为空!" << endl;
}
break;
case 7:
cout << "请输入一个位置用来取值:";
cin >> location;
temp = GetElem(L, location, e);
if (temp != 0) {
cout << "获取成功,此图书信息:" << endl;
cout << left << setw(15) << e.id << "\t";
cout << left << setw(20) << e.name << "\t";
cout << left << setw(10) << e.price << endl;
}
else {
cout << "查找失败!位置超出范围" << endl;
}
break;
case 8: {
cout << "请输入所要查找价格:";
double price;
cin >> price;
LNode* p = LocateElem(L, price);
if (p) {
cout << "查找成功,此图书信息:" << endl;
cout << left << setw(15) << p->data.id << "\t";
cout << left << setw(20) << p->data.name << "\t";
cout << left << setw(10) << p->data.price << endl;
}
else {
cout << "查找失败!没有这个价格对应的书籍" << endl;
}
}
break;
case 9:
cout << "插入位置:";
cin >> location;
cout << "插入图书id、名字、价格: ";
cin >> e.id >> e.name >> e.price;
temp = ListInsert1(L, location, e);
if (temp != 0) {
cout << "插入成功!" << endl;
}
else {
cout << "插入位置超出范围!";
}
break;
case 10:
cout << "删除图书的位置:";
cin >> location;
temp = ListDelete1(L, location);
if (temp != 0) {
cout << "删除成功!" << endl;
}
else {
cout << "删除位置超出范围!";
}
break;
case 11:
ListPrint(L);
break;
}
}
return 0;
}
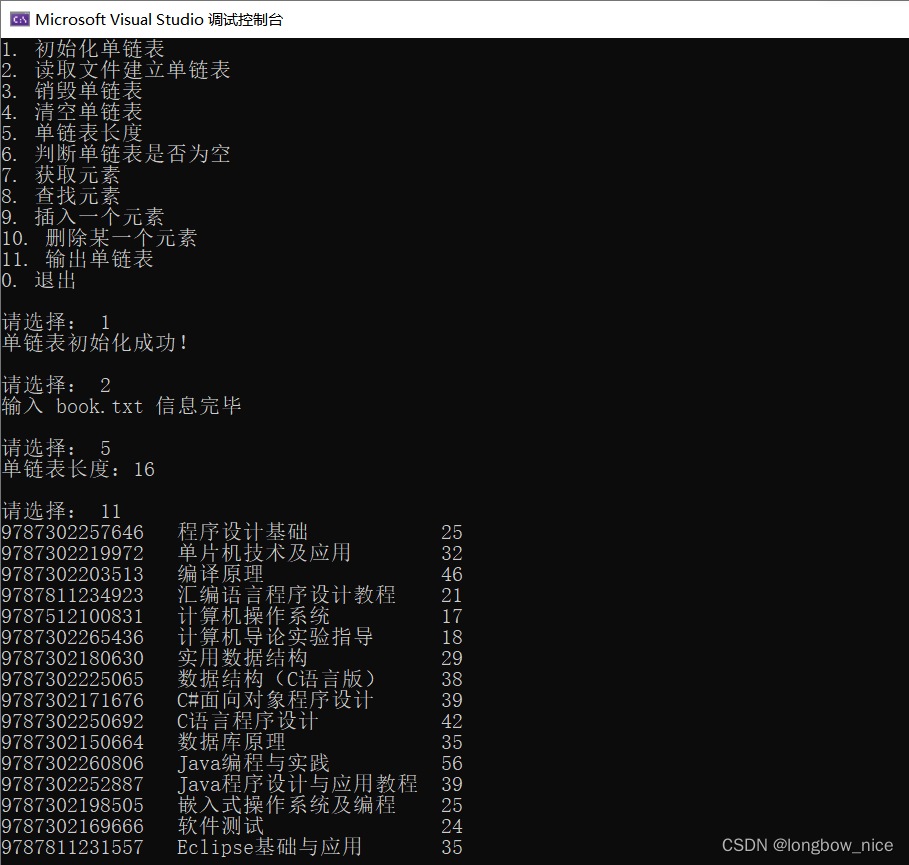
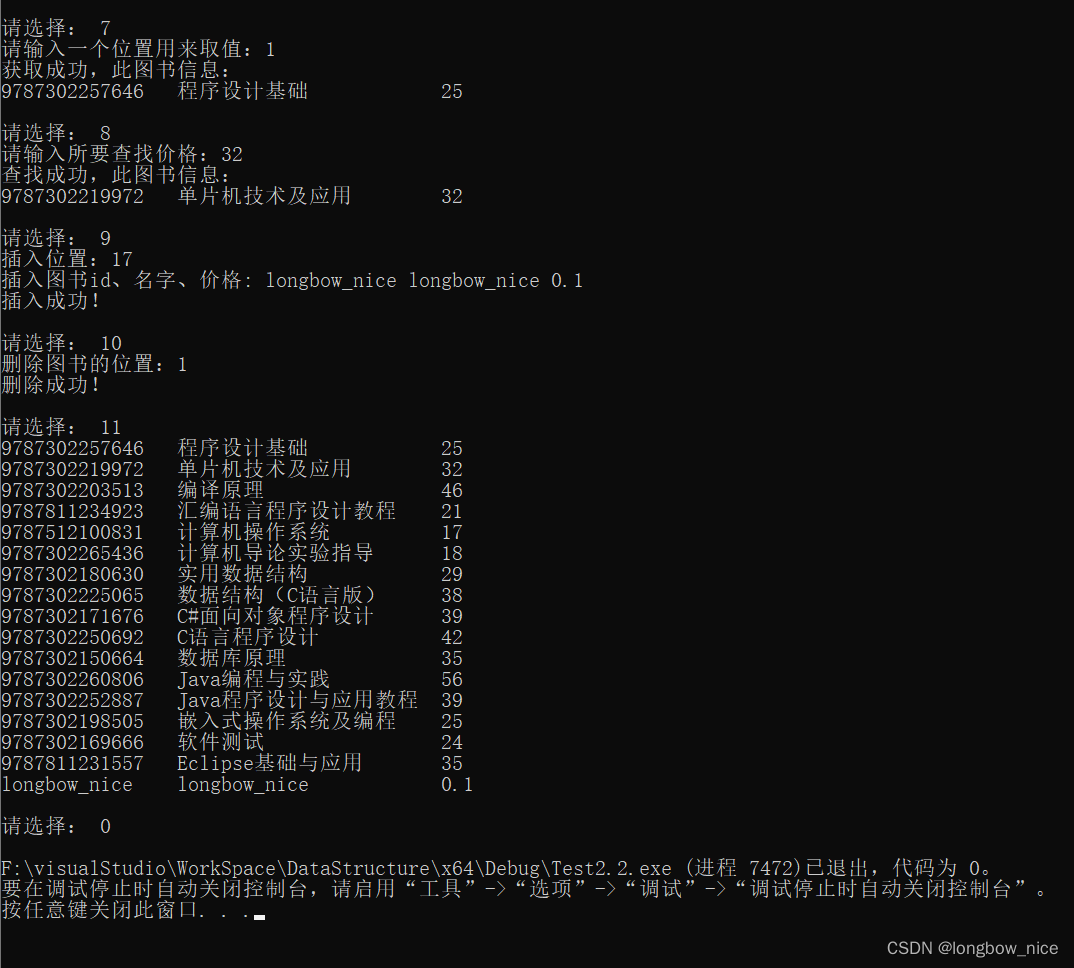
运行结果:
3. 实现单链表遇到问题
存储结构定义详细解释,struct LNode* next解释,为啥next定义成指针类型
4.链表和顺序表异同
存储结构 比较项目 | 顺序表 | 链表 | |
空间 | 存储空间 | 预先分配,会导致空间闲置或溢出现象 | 动态分配,不会出现存储空间闲置或溢出现象 |
存储密度 | 不用为表示结点间的逻辑关系而增加额外的存储开销,存储密度等于1 | 需要借助指针来体现元素间的逻辑关系,存储密度小于1 | |
时间 | 存取元素 | 随机存取,按位置访问元素的时间复杂度为O(1) | 顺序存取,按位置访问元素时间复杂度为O(n) |
插入、删除 | 平均移动约表中一半元素,时间复杂度为O(n) | 不需移动元素,确定插入、删除位置后,时间复杂度为O(1) | |
适用情况 | ① 表长变化不大,且能事先确定变化的范围 ② 很少进行插入或删除操作,经常按元素位置序号访问数据元素 | ① 长度变化较大 ② 频繁进行插入或删除操作 | |
版权声明:本文为longbow_nice原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。