1.datax简介
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS(Hadoop分布式文件系统)、Hive(hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 )、ODPS(ODPS是分布式的海量数据处理平台)、HBase(HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。)、FTP等各种异构数据源之间稳定高效的数据同步功能。
2.datax的架构设计
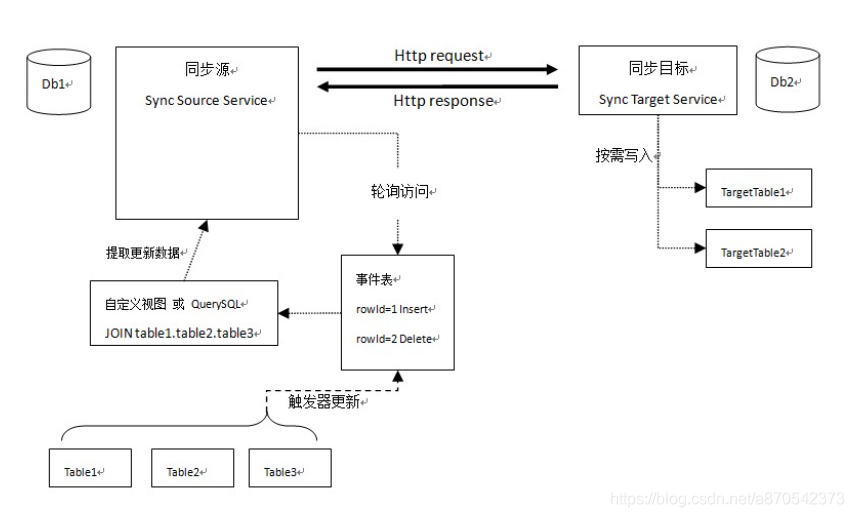
3.datax的特点
- 支持sql-server / oracle / mysql 等jdbc支持的数据库之间互导
- 支持数据库与solr(Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。)搜索引擎之间互导
- 采用http协议传送数据,在网络环境复杂和连接不稳定的情况下能正常工作,也可以扩展成集群、转发、负载均衡等
- 网络不稳定、数据库连接不稳定的情况下,有重连、重试机制
- 复杂的数据处理和异构,自定义Query-SQL和Insert/Delete/Update-SQL
- 分布式事务、数据一致性保护。导入错误的情况下,两边数据都不会发生更改
- 在工作异常的情况下,可以发送短信或邮件通知
- 可以通过http网页形式随时查看工作状态和cpu 内存使用情况,方便监控
- 在异构的数据库/文件系统之间高速交换数据
- 采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问
- 运行模式:stand-alone
- 数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC
- 开放式的框架,开发者可以在极短的时间开发一个新插件以快速支持新的数据库/文件系统。
4.datax结构模式(框架+插件)
- Job: 一道数据同步作业
- Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
- Sub-job: 数据同步作业切分后的小任务
- Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
- Storage: Reader和Writer通过Storage交换数据
- Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
Reader插件
- hdfsreader : 支持从hdfs文件系统获取数据。
- mysqlreader: 支持从mysql数据库获取数据。
- sqlserverreader: 支持从sqlserver数据库获取数据。
- oraclereader : 支持从oracle数据库获取数据。
- streamreader: 支持从stream流获取数据(常用于测试)
- httpreader : 支持从http URL获取数据。
Writer插件
- hdfswriter:支持向hdbf写入数据。
- mysqlwriter:支持向mysql写入数据。
- oraclewriter:支持向oracle写入数据。
- streamwriter:支持向stream流写入数据。(常用于测试)
5.相关链接
datax的github地址:https://github.com/alibaba/DataX
MysqlReader插件文档:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
MysqlWriter插件文档:https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
OracleReader插件文档:https://github.com/alibaba/DataX/blob/master/oraclereader/doc/oraclereader.md
OracleWriter插件文档:https://github.com/alibaba/DataX/blob/master/oraclewriter/doc/oraclewriter.md