结合阅读书籍和实际工作经验,整理一篇笔记性质的博客,供参考。能帮助到需要的人就是我的满足,更欢迎大神指导不足,谢谢!
一、流程概述
下图概况了典型的评分卡开发流程,该流程的各个步骤的顺序根据具体情况的不同调整,也可以根据需要重复某些步骤。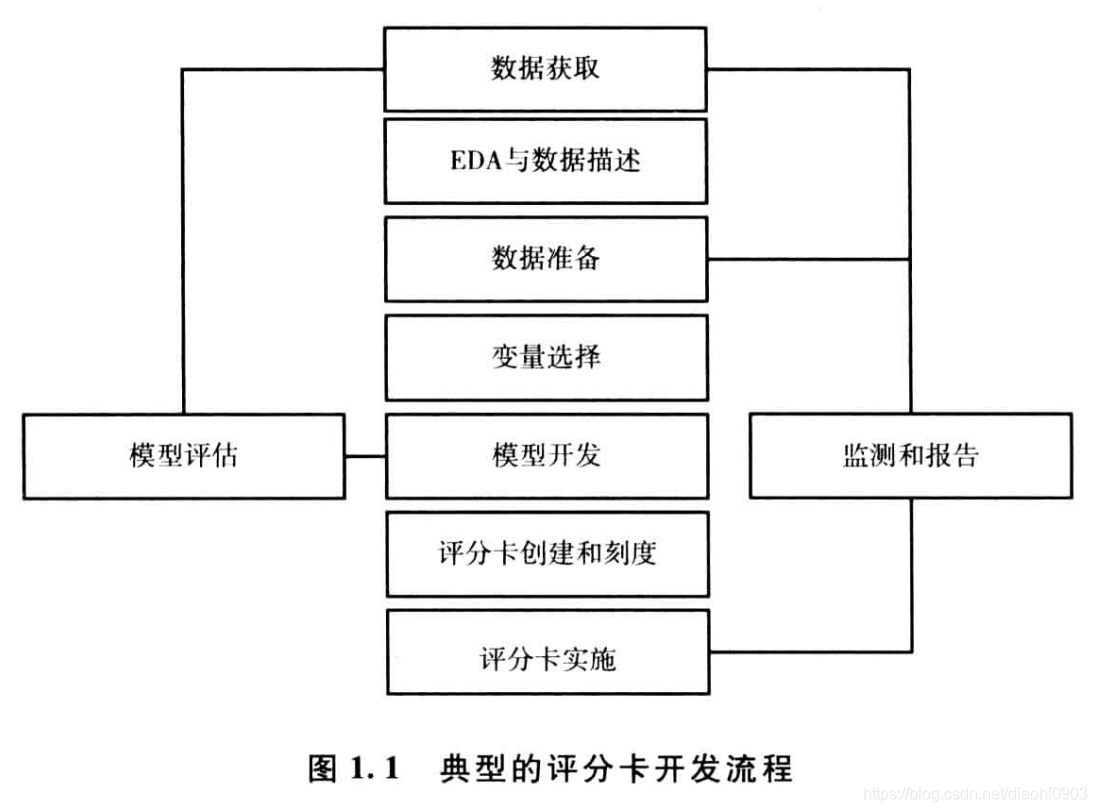
具体的步骤内容
- 问题准备
- 数据获取与整合
- EDA(探索性数据分析)与数据描述
- 数据准备(特征工程)
- 变量选择
- 模型开发
- 模型检验和评价
- 评分卡创建和刻度
- 评分卡实施
- 监测和报告
引用自:《信用风险评分卡研究_基于SAS的开发与实施》
二、问题准备
建模项目的规划期,必须确认清楚以下事项,否则一旦出现问题就得从头返工了,慎重再慎重!
1、模型的应用范围
主要考虑首贷/续贷,产品种类,销售渠道等可以明显区分客群的因素
2、违约/正常样本定义
即Y变量定义,也就是好人/坏人的定义,逾期多少天的人标记成坏人。可以是DPD15+,M1+,M3+等,一般当坏账率 / 某个时点的逾期率 在80%左右,则可以用这个时点逾期作为违约的定义(此为单期产品的定义,多期产品的定义较为复杂,需要结合业务确认)
3、数据时间窗口
分为建模数据窗口和验证数据窗口,建模数据是模型训练数据,验证数据是out of time验证以避免模型过拟合的数据,一般选取建模数据窗口后的一段时间。
数据时间窗口选取的原则
1)表现期成熟:也就观察期,表现期=借款期限+违约定义期限,比如借款30天的产品,以M1作为违约定义,那么放款后60天才能算表现期成熟。
2)保证数据新鲜度:模型是为了预测未来的数据,所以要保证建模的数据最接近未来,所以选取最近的数据。
3)保证数据周期性:很多贷款产品特别是pay day loan,逾期率具有时间周期性,发薪日逾期率明显低于其他时间,这种情况,数据窗口最好以月为单位选取。
4)保证样本量大小:根据经验,违约样本的数量需要至少1500个。
4、数据源确定
刚才确定了数据有哪些行,现在来确定有哪些列,也就是说,确定我们的特征/变量/属性。
数据源可以分为内部数据、外部数据,具体来说,就是确定此次建模能用到的所有数据表。
数据源选取的原则
1)数据覆盖率:数据覆盖率不能过低(不同模型算法要求不同,逻辑回归要求覆盖率较高,xgboost等数模型要求低些)。
2)数据稳定性:数据的计算逻辑是维持稳定的,不会发生数据定义的改变
3)未来有效性:在模型实施期,可能无法获取的数据,不能用于建模
5、项目周期
建模项目的人员、资源、时间等,主要是明确各阶段的时间计划表,保证整体工作节奏可控。
三、数据获取与整合
1、数据获取
从各处数据源提取需要的数据(Mysql、MongoDB、Hive、离线数据等等),先按表分开提取即可。
注意点:生产环境的数据计算规则可能已经发生变化,为保证建模的数据跟当前保持一致,需要对一些数据重新计算,可以称为刷新数据、刷件
2、数据整合
也叫合并宽表,通过主键将所有数据合并成一张表,M行*N列。
M行表示建模样本一共有多少件;
N列表示建模初始有多少变量(这里包含了id、Y变量、时间变量等);
未完待续ING