2018年9月8日笔记
登录谷歌云控制台需要科学上网,连接云主机不需要科学上网。
阅读此文并进行操作的前提是已经成功申请谷歌云的使用资格,并获得300美元使用金额。
如何申请谷歌云的使用,请阅读另外一篇文章《申请谷歌云教程,可免费使用一年》。
文章链接:https://coderschool.cn/2598.html,获得300美元使用金额后即可转回本文阅读。
搭建深度学习平台主要包括下面10个步骤:
0.创建VM instance,又称云实例、云主机,即云上的虚拟机。
1.使用Xshell连接云虚拟机
2.在云虚拟机中安装Anaconda5.2
3.本地访问云虚拟机中的jupyter服务
4.在云虚拟机中安装Nvidia驱动
5.在云虚拟机中安装CUDA9.0
6.在云虚拟机中安装cuDNN7.1
7.在云虚拟机中安装TensorFlow、Keras
8.运行简单例子--基于TensorFlow+CNN的Mnist数据集手写数字分类
9.运行简单例子--基于Keras+resNet的Cifar10数据集图片10分类
0.创建云虚拟机实例
谷歌云控制台链接:https://console.cloud.google.com
进入谷歌云的控制台后,依次点击控制中心,即图中左上方红色方框标注的三根横线。
选择Compute Engine中的VM instance,就可以查看自己的云实例。
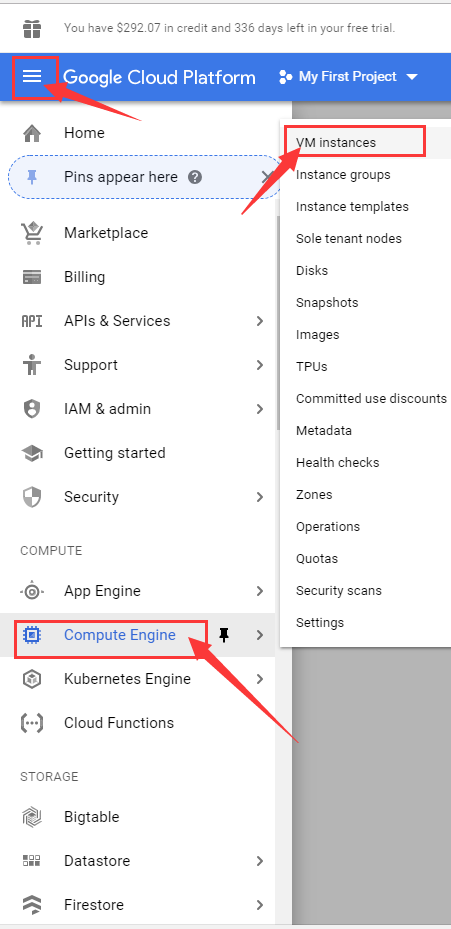
如果获得了300美元的使用资格,在图中红色方框标注处会显示 剩余使用金额和 剩余使用时间。
在 VM instance界面中,选择 CREATE INSTANCE。
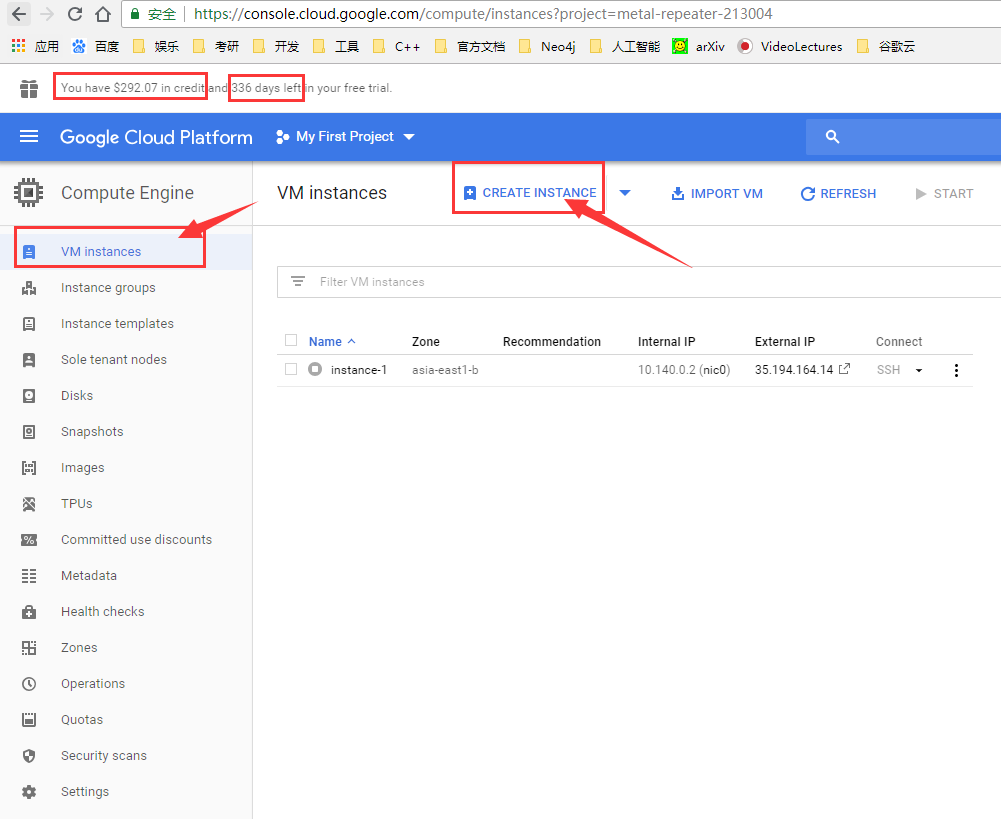
选择下图红色方框标注处的 Customize,即自定义虚拟机配置。
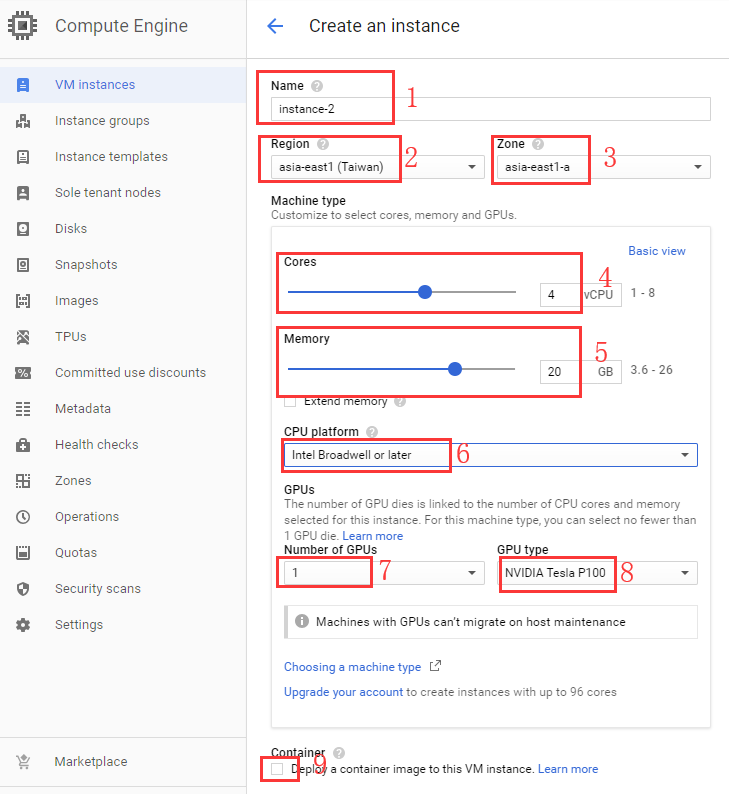
自定义设置如下图所示:
1.Name设置为 instance-2
2.Region设置为 asia-east1(Taiwan)
3.Zone设置为 asia-east1-a
4.Cores设置为 4
5.Memort设置为 20
6.CPU platform设置为 Intel Broadwell or later
7.Number of GPUs设置为 1
8.GPU type设置为 NVIDIA Tesla P100
9.Deploy a container image to this VM instance,中文叫做 将容器映像部署到此VM实例, 不勾选
改变磁盘大小和启动的操作系统,如下图红色方框标注所示:
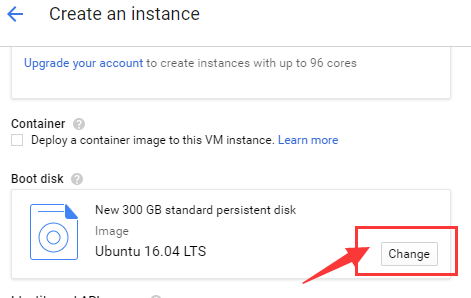
1.镜像选择 OS images
2.操作系统选择 Ubuntu 16.04 LTS
3.磁盘大小选择 300
4.最后点击 Select,完成虚拟机的自定义磁盘
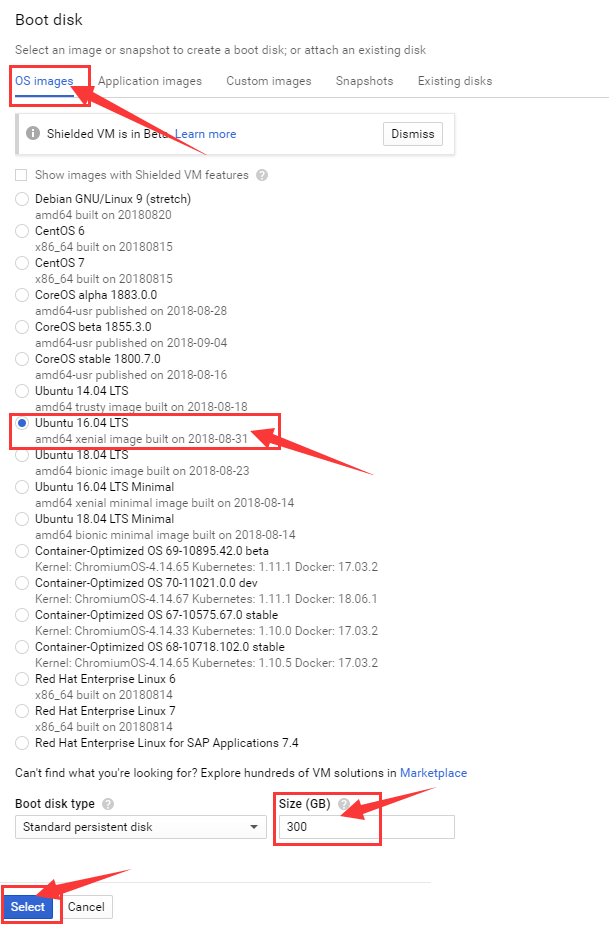
1.Boot disk,中文叫做 启动磁盘,查看磁盘大小和操作系统是否如下图所示
2.Service account,中文叫做 服务账户,选择 Compute Engine default service account
3.Access scopes,中文叫做 存取范围,选择 Allow default access
4.Firewall,中文叫做 防火墙,允许两种通信方式,即 都勾选
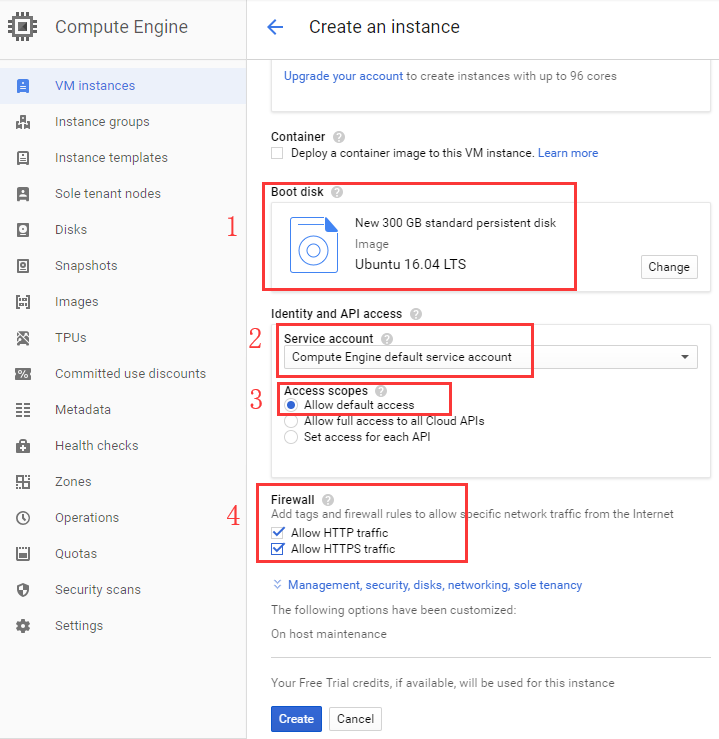
完成虚拟机的设置后,点击上图的 Create,则创建 虚拟机实例。
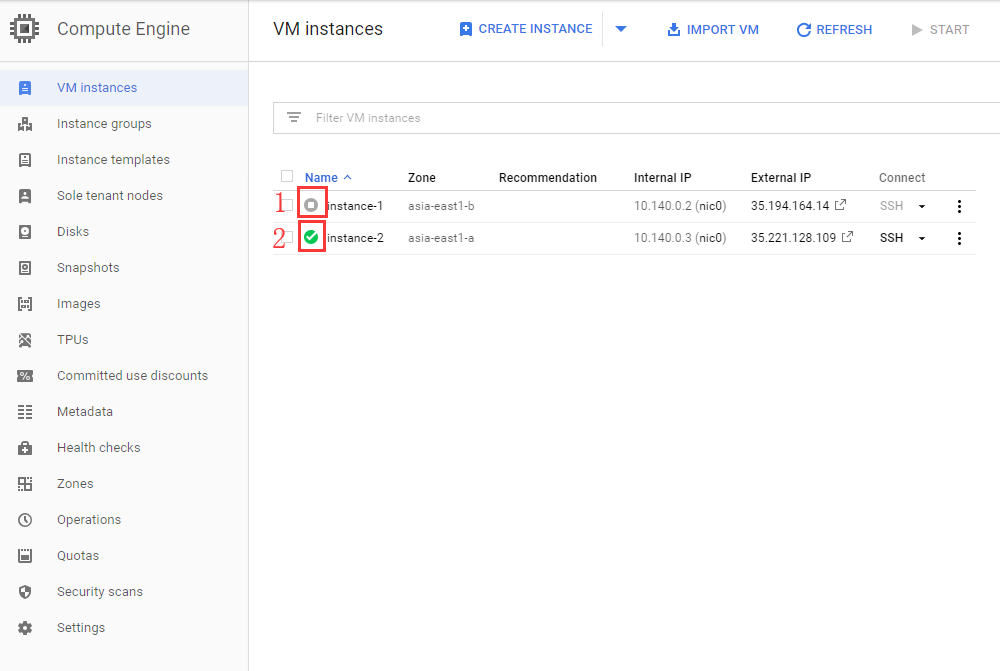
创建虚拟机实例后,会 自动开机,如下图 序号2所示。
本文作者的第1个虚拟机实例是关机状态,如下图 序号1所示。
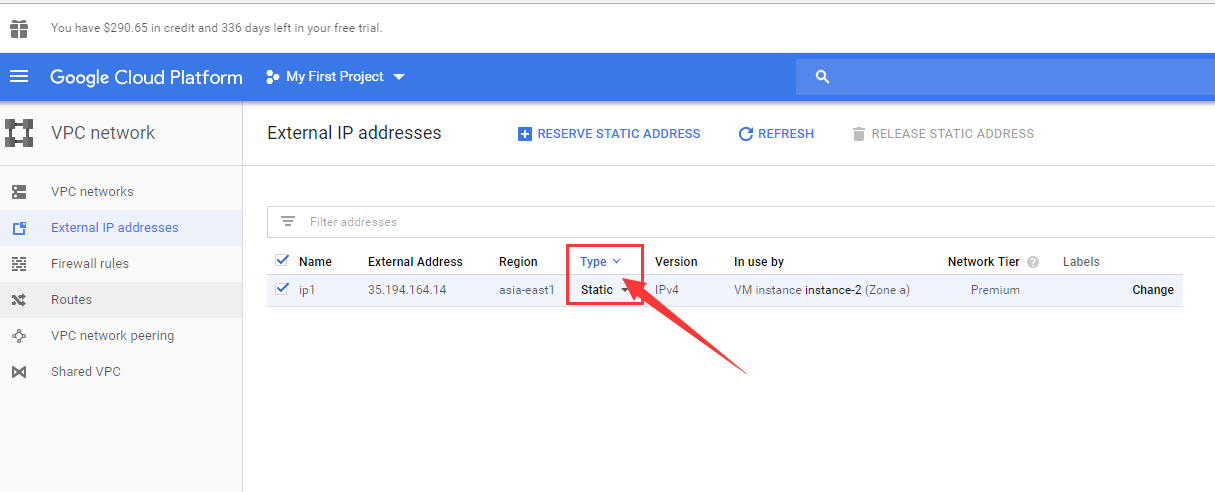
将虚拟机实例的IP设置为静态,这样 便于Xshell访问。
因为是试用账户,只有 1个静态IP配额
进入 控制中心中的 VPC network下的 External IP addresses
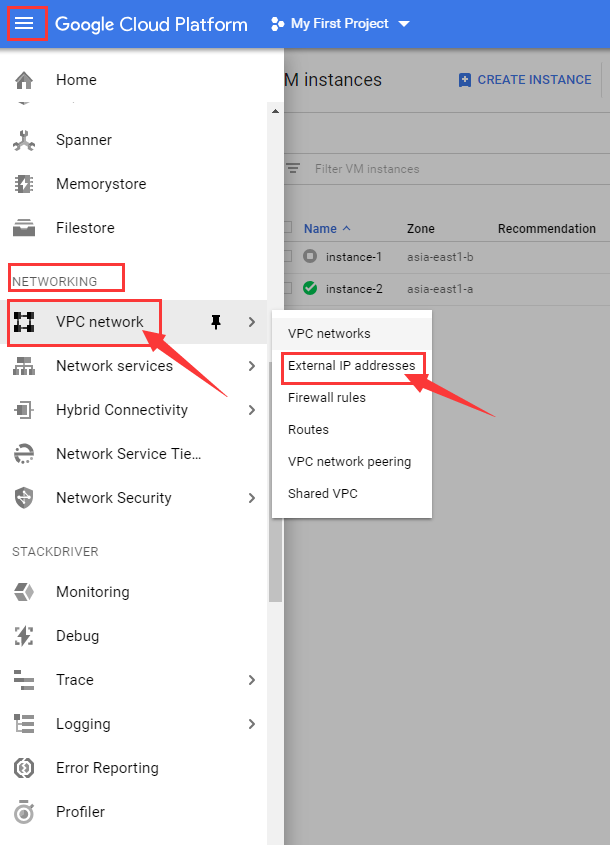
Ephemeral中文叫做 短暂的,将下图红色方框标注出修改为 static,即为虚拟机实例设置静态IP。
1.使用Xshell连接云虚拟机
1.1 安装Xshell
下载Xshell安装文件,下载链接: https://pan.baidu.com/s/1QgnleUEo4yoJDXXeveAJqQ 密码: 5h5d
下载后双击文件进行安装,弹出界面如下图所示,选择下一步。
如下图所示,选择 我接受许可证协议中的条款,点击 下一步。
如下图所示,设置 用户名和 公司名,点击 下一步。
目的地文件夹 不改变,点击 下一步。
点击 安装。
Xshell 6 Evaluation运行 勾选,点击 完成。
1.2 新建SSH公私钥
点击导航栏中的工具下的新建用户密钥生成向导。
在 生成向导界面保持下图红色方框所示,点击 下一步。
经过少量时间就可以如下图所示 成功生成公钥,点击 下一步。
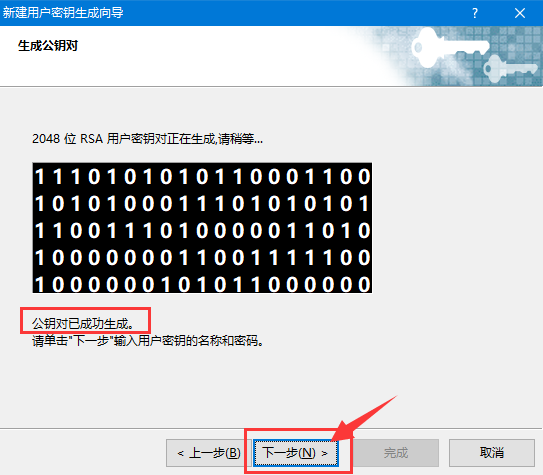
1.设置密钥名称为 xiaosakun;
2.设置密码为 google,两次输入密码要 相同;
3.点击 完成。
选中刚刚新建的密钥,点击 属性。
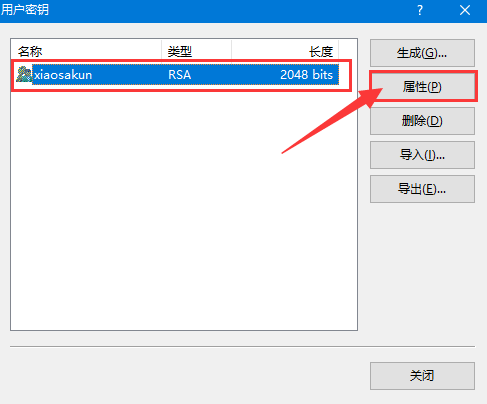
在打开的 属性窗口中,点击 公钥,复制下图红色箭头的内容,这个内容需要 添加到谷歌云控制台中。
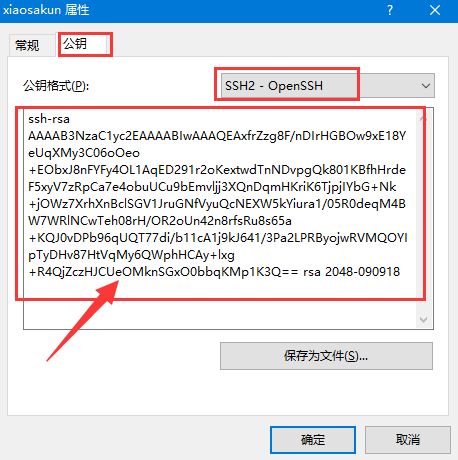
在谷歌云控制台中找到 添加SSH密钥的按钮。
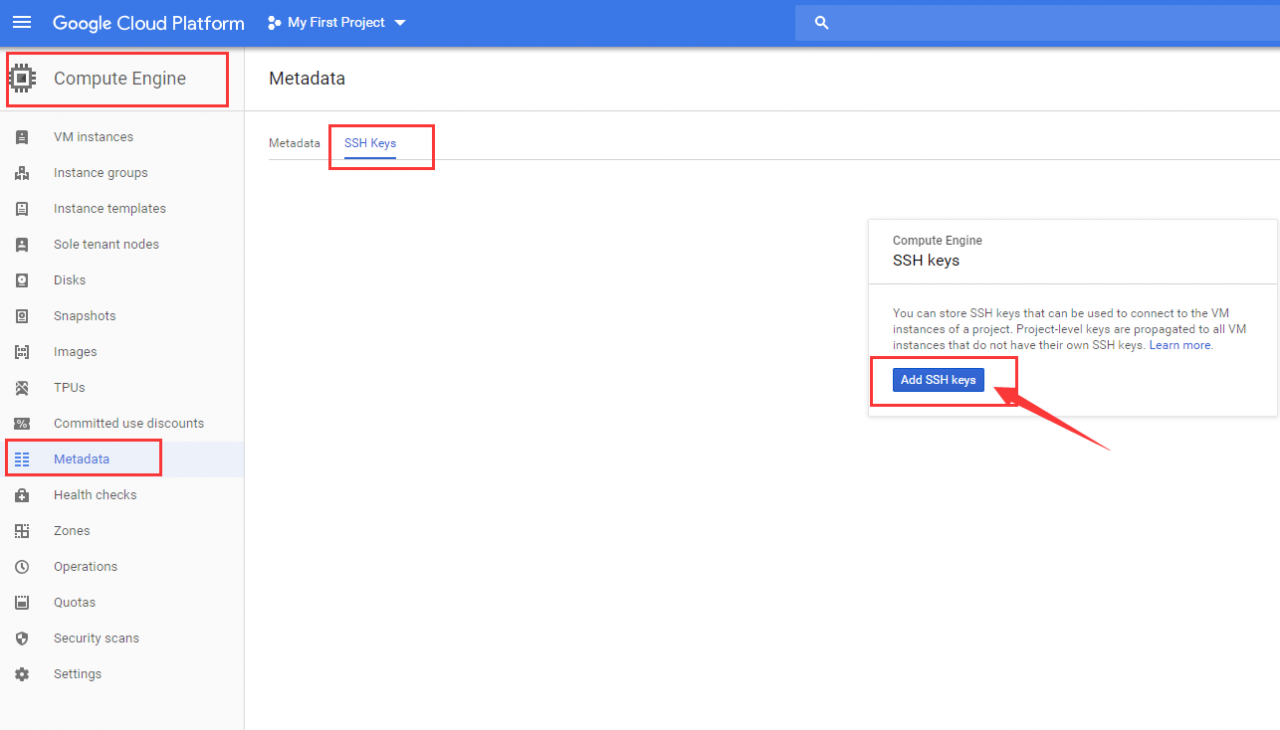
公钥的 ==后的内容替换为 空格+ xiaosakun,点击 Save。
点击 Save后公钥就保存在谷歌云控制台中,私钥被Xshell软件自动存在电脑中。
1.3 新建会话连接
在新打开的Xshell窗口中,点击下图红色方框标注处。
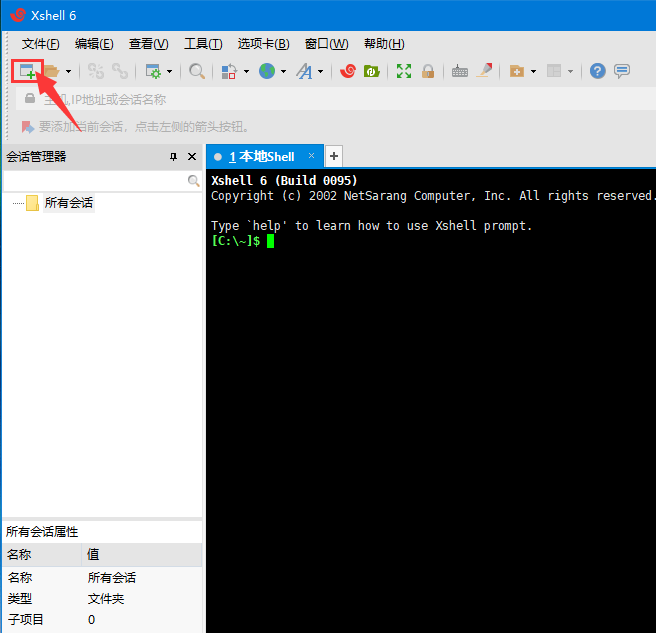
下图 1号红色方框和 2号红色方框中的IP相同。
设置 连接名称为 谷歌云;
设置 主机为虚拟机相同的 External IP;
最后点击 确定。
双击 所有会话下的 新建会话,即下图红色方框所示按钮。
选择 接受并保存。
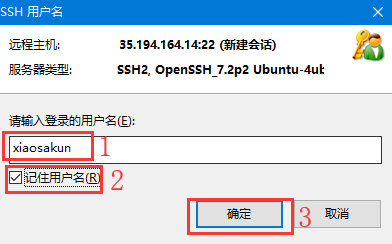
1.登录用户名设置为 xiaosakun;
2.记住用户名 勾选;
3.点击 确定。
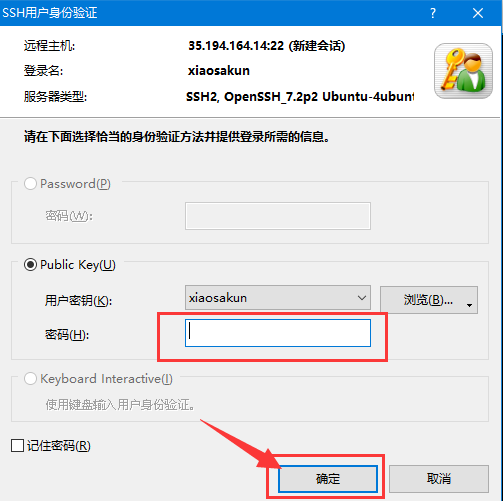
再次双击 新建会话,在下图所示密码处输入 google,点击 确定。
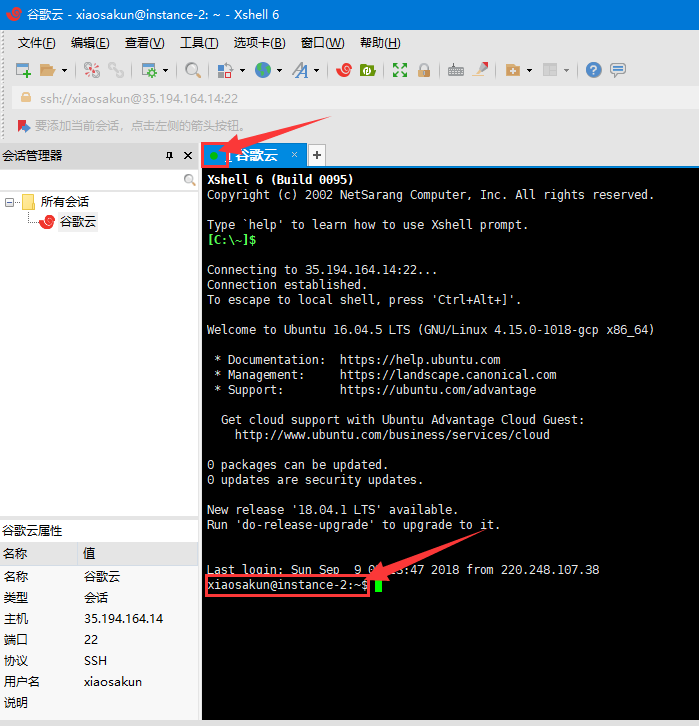
在下图中本文作者已经将 新建会话重命名为 谷歌云,读者也可以修改。
出现下图红色箭头所示的 绿色信号灯和 linux终端界面,则表明 Xshell连接虚拟机成功。
2.在云虚拟机中安装Anaconda5.2
用浏览器Chrome打开https://www.anaconda.com/download/#linux,如下图所示:
读者应该查看 是否现在处于linux的下载界面中。
把鼠标移动到 Download按钮上,鼠标 右击,点击下图所示 复制链接地址。
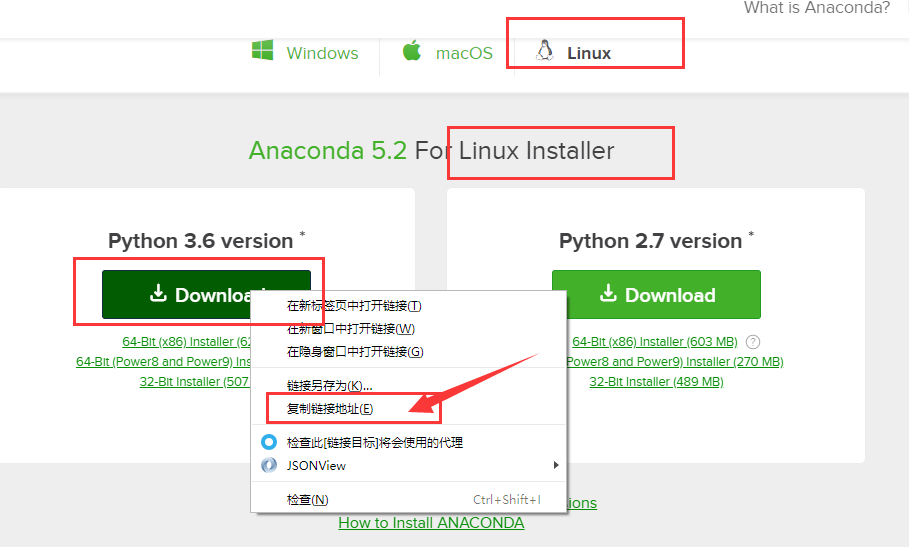
下载链接为: https://repo.anaconda.com/archive/Anaconda3-5.2.0-Linux-x86_64.sh
linux系统中下载命令为: wget {},大括号替换为下载链接。
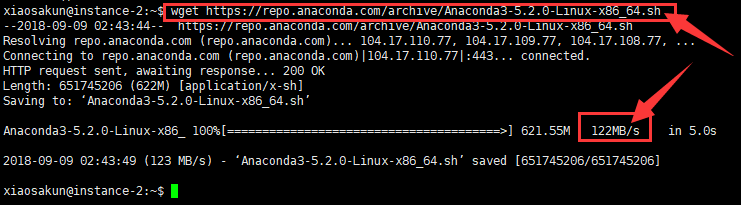
在Xshell的终端中输入命令并运行:
wget https://repo.anaconda.com/archive/Anaconda3-5.2.0-Linux-x86_64.sh 如下图所示,第1个箭头表示命令,第2个箭头表示获取资源的下载速度,可以看出虚拟机的下载速度有122M/S,很快。
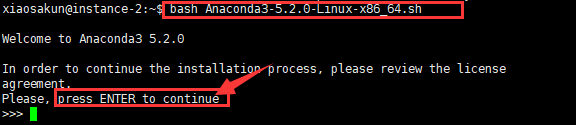
在Xshell的终端中输入命令并运行:
bash Anaconda3-5.2.0-Linux-x86_64.sh 如下图所示,要求我们阅读用户协议,一直点击 Enter即可。
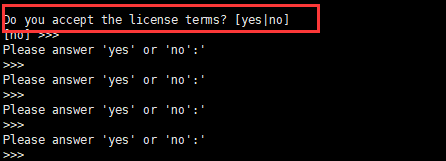
询问我们是否接受协议条款,如下图所示,回答 yes。
询问我们将软件安装在何处,如下图所示,选择默认安装,点击 Enter。
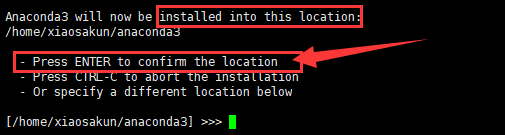
询问我们是否添加Anaconda的路径到环境变量PATH中,回答 yes。

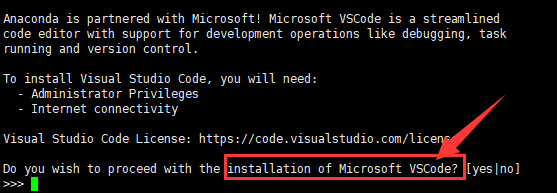
询问我们是否安装 Microsoft VSCode,回答 no。
更新环境变量PATH,输入命令并运行:
source ~/.bashrc 到这里为止,就已经完成安装Anaconda5.2。
查看是否成功安装Anaconda5.2的命令:
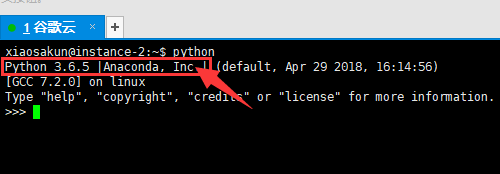
python 如果出现下图的 Python 3.6.5 |Anaconda, Inc,则表明 安装Anaconda5.2成功。
3.本地访问云虚拟机中的jupyter服务
3.1 设置控制台防火墙
进入谷歌云控制台,点击控制中心下的NETWORKING下的VPC network下的Firewall rules。
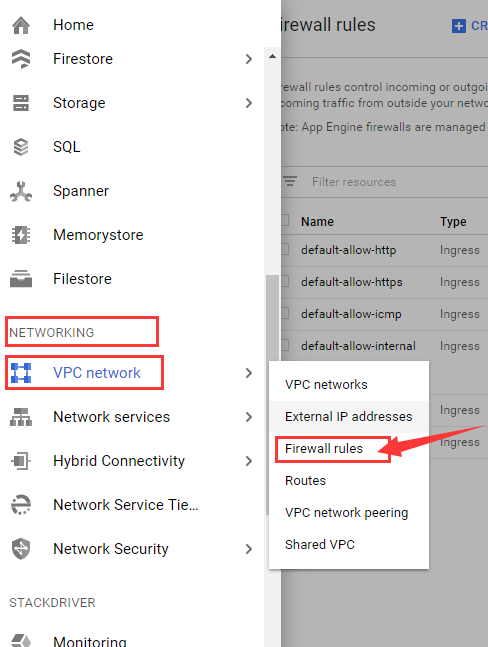
点击红色箭头标注处,设置http防火墙规则。
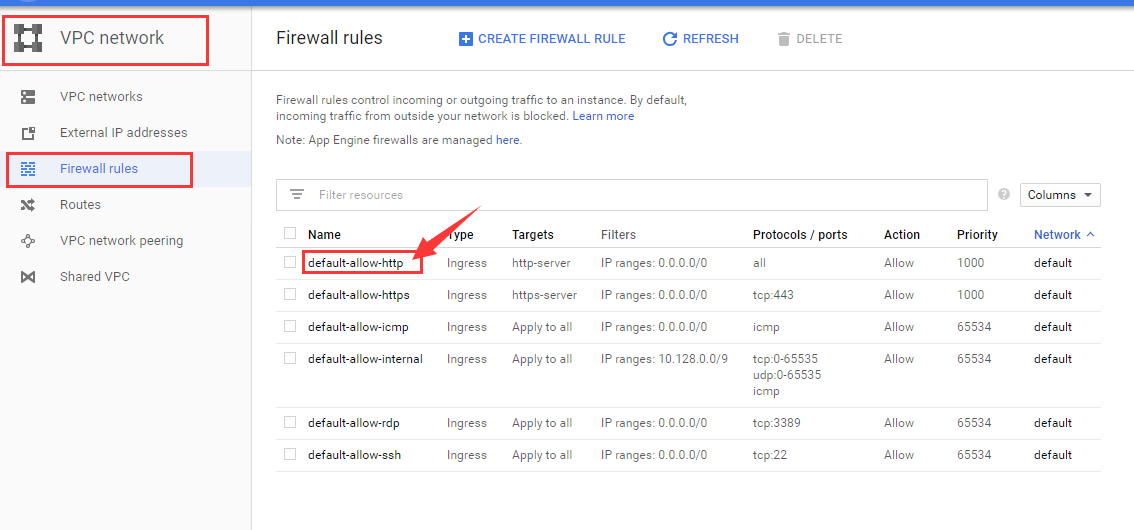
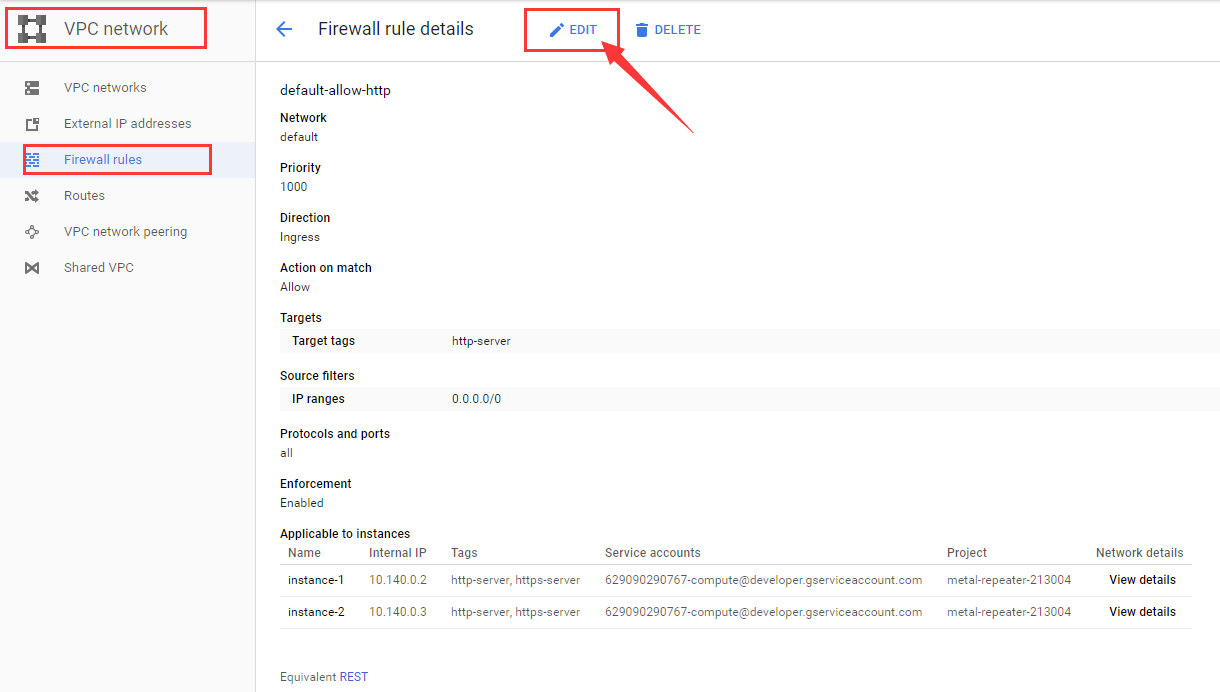
选择下图中的 EDIT按钮,进行编辑。
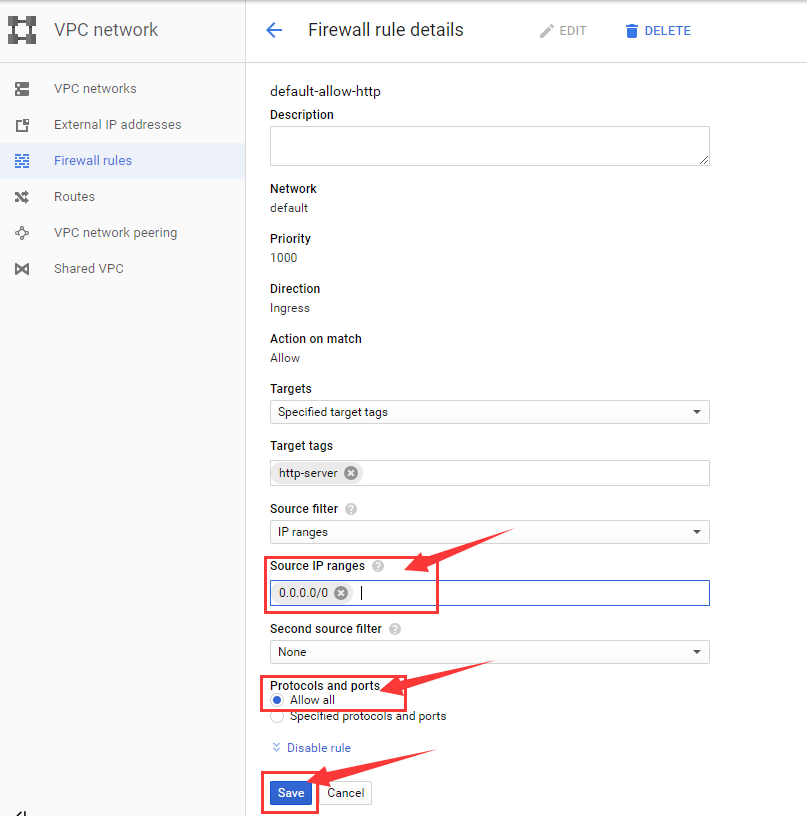
不限制访问的IP,即 Source IP ranges设置为 0.0.0.0
不限制访问的协议和端口, 勾选Allow all
最后保存设置,点击 Save
3.2 设置Xshell会话连接中的隧道
右击在所有会话下的谷歌云,点击属性。
选择 隧道,点击 添加。
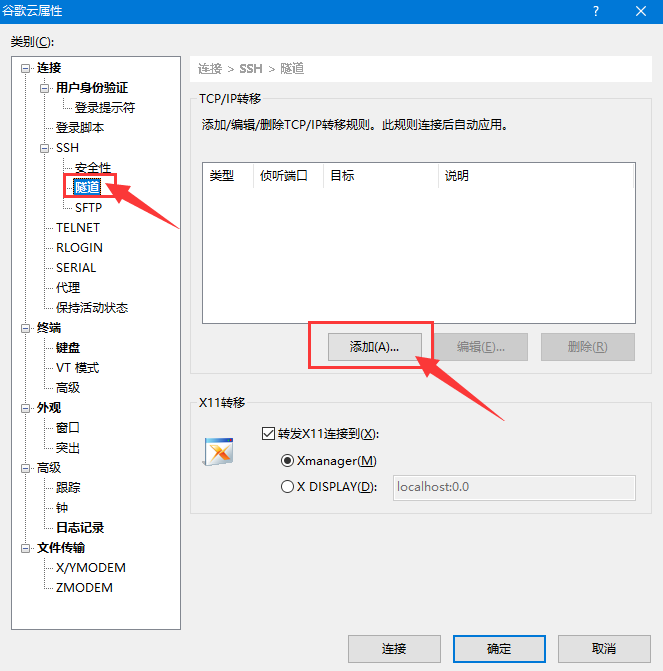
在 转移规则窗口,下图中的 1号方框和 2号方框中内容相同。
类型(方向)设置为 本地(拨出);
源主机设置为 localhost;
侦听端口设置为 18888;
目标主机设置为 1号方框中IP地址。
目标端口设置为 8888。
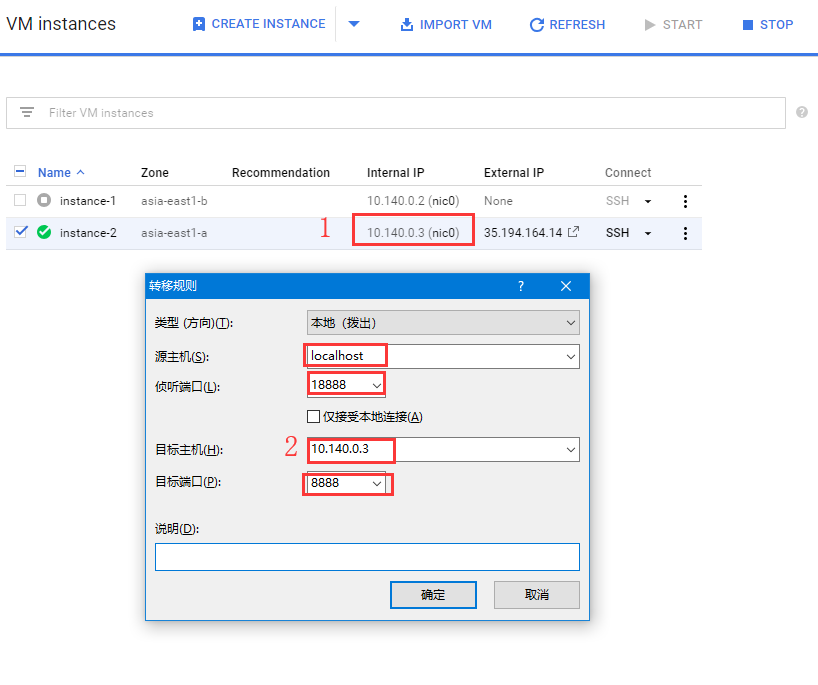
完成添加 TCP/IP转移规则后,如下图所示,点击 连接。
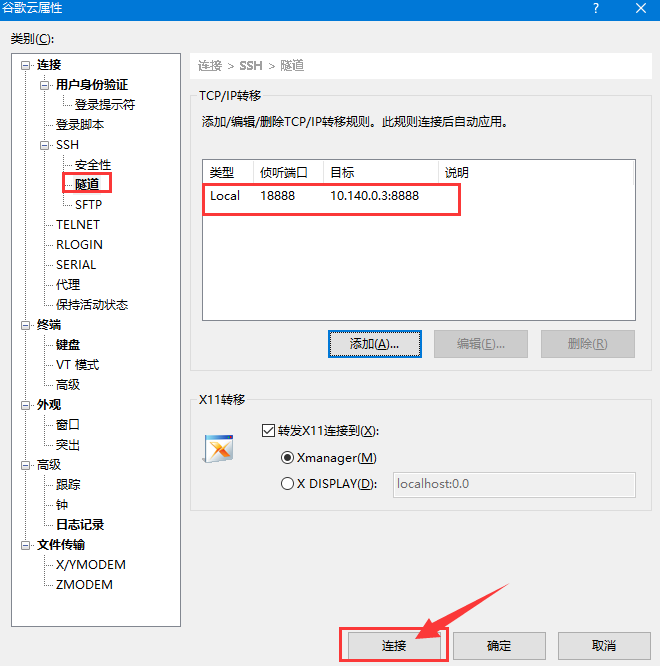
打开新的会话连接如下图所示,在密码中输入 google,点击 确定。
3.3 设置jupyter
在云虚拟机中运行命令:vim generateSha.py
按一下键盘上的A键进入vim编辑器的编辑模式,然后复制下面一段代码到vim编辑器中:
from notebook.auth import passwd
print(passwd('google'))
如下图所示:
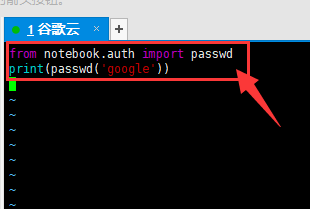
按一下键盘上的 Esc键进入vim编辑器的命令模式,输入
:wq并运行,表示保存并退出。 在云虚拟机中运行命令:
python generateSha.py 运行结果如下图所示:

即字符串google通过sha1算法加密的结果是
sha1:175857feb4bc:81edf72d2ad0f8f634dc8aa3ca8f195f2580219a 在云虚拟机中运行命令:
jupyter notebook --generate-config 
在云虚拟机中运行命令:
vim /home/xiaosakun/.jupyter/jupyter_notebook_config.py 按一下键盘上的A键进入vim编辑器的编辑模式,然后添加下面一段代码到vim编辑器中。
下面4行代码的最后1行,是设置jupyter notebook的登录密码。
将登录密码设置为 字符串google通过sha1算法加密后的结果。
c.NotebookApp.ip = '*'
c.NotebookApp.port = 8888
c.NotebookApp.open_browser = False
c.NotebookApp.password = u'sha1:175857feb4bc:81edf72d2ad0f8f634dc8aa3ca8f195f2580219a'
如下图所示:
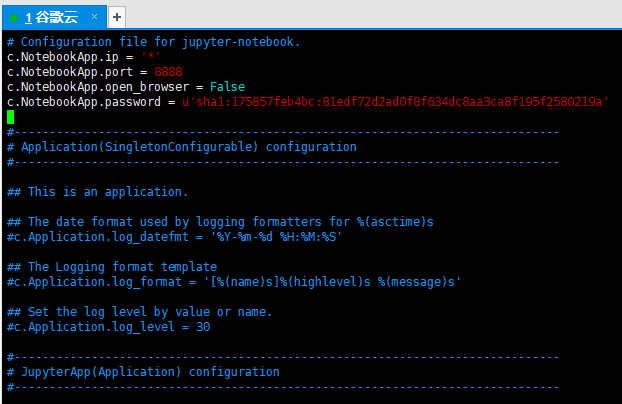
按一下键盘上的Esc键进入vim编辑器的命令模式,输入:wq并运行,表示保存并退出。
到这里为止已经,完成访问jupyter服务的所有设置,下一节在本地浏览器中测试是否能访问云虚拟机的jupyter服务。
3.4 本地访问jupyte服务
在云虚拟机中运行命令:jupyter notebook
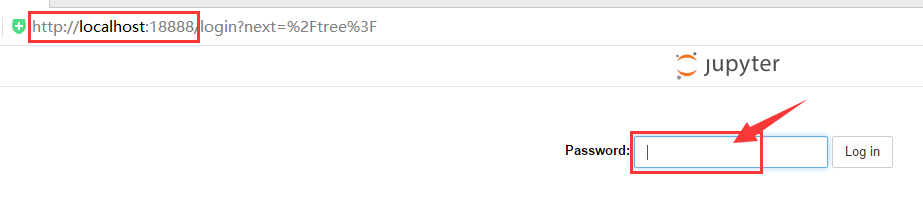
在本地浏览器中访问网址:localhost:18888,出现结果如下图所示。
可以从下图看出,网址确实是localhost:18888,密码输入google.
点击Log in,则可以成功登陆云虚拟机的jupyter服务。
进入jupyter界面后,如下图所示,新建代码文件
在单元格中输入下面一段代码并运行:
import matplotlib.pyplot as plt
plt.plot(range(1,5), range(1,9,2))
plt.show()
上面一段代码的运行结果如下图所示:
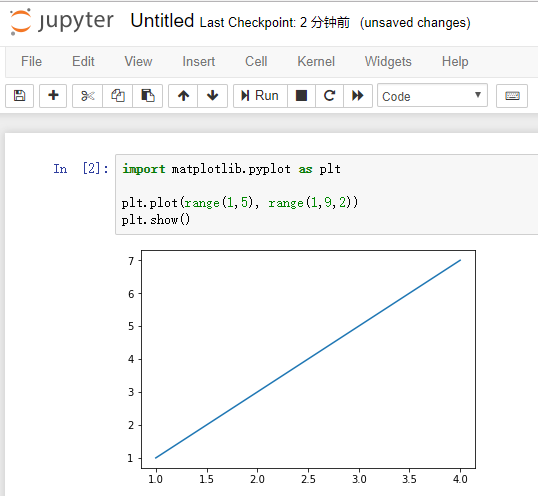
从上面的运行结果可以看出,我们的代码能够在云虚拟机上成功运行。
4.在云虚拟机中安装Nvidia驱动
按照正常的流程走,需要根据显卡型号安装对应的驱动。
查看显卡型号命令:lspci | grep -i nvidia
如下图所示:

因为linux系统的 apt-get update命令可以自动更新软件及其依赖关系,本文作者将安装Nvidia驱动和CUDA9.0的命令封装成一个批处理文件 installNvidia.sh,此文件内容在下一章中。
本文作者学习如何安装CUDA9.0+cuDNN7.1的博客链接: https://medium.com/@mingyulin_23146/install-cuda9-0-cudnn7-1-tensorflow-1-6-on-google-cloud-platform-ubuntu-16-04-4b01f5ac3741
5.在云虚拟机中安装CUDA9.0
在虚拟机中运行命令:vim installNvidia.sh
在vim编辑器中按a键进入编辑模式,将下面一段代码复制到文件中。
#!/bin/bash
echo "Checking for CUDA and installing."
# Check for CUDA and try to install.
if ! dpkg-query -W cuda; then
# The 16.04 installer works with 16.10.
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.0.176-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1604_9.0.176-1_amd64.deb
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda-9.0
fi
echo 'export CUDA_HOME=/usr/local/cuda-9.0' >> ~/.bashrc
echo 'export PATH=$PATH:$CUDA_HOME/bin' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$CUDA_HOME/lib64' >> ~/.bashrc
source ~/.bashrc
按Esc键进入vim编辑器的命令模式,输入:wq并运行,表示保存并退出。
在虚拟机中运行命令:bash installNvidia.sh
运行少量时间后,如下图所示,询问是否继续,回答y。

经过大概10分钟,可以安装成功。
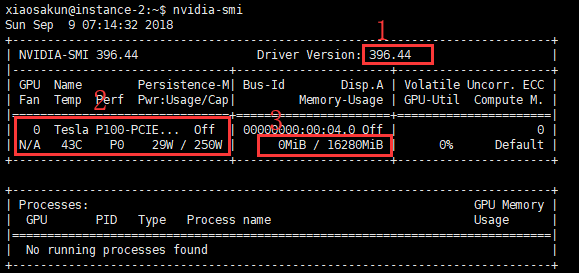
查看Nvidia显卡的使用情况,命令:
nvidia-smi 1号红色方框中 396.44表示驱动版本号;
2号红色方框中 Tesla P100-PCIE表示显卡型号, 29W/250表示显卡功率负载。
3号红色方框中 0MiB/16280MiB表示显卡的显存使用情况。
如果显示下图,则表示 安装Nvidia驱动成功。
查看CUDA版本号,命令:
cat /usr/local/cuda/version.txt 如果显示下图,则表示 安装CUDA9.0成功。
6.在云虚拟机中安装cuDNN7.1
此章可以用两种方法解决,读者如果不理解第1种方法,可以尝试简单的第2种方法。
6.1 官网下载并安装cuDNN7.1
从官网上下载cuDNN7.1必须注册Nvidia,读者自己解决注册Nvidia账号。
下面步骤必须要用能够获取下载链接的浏览器,本文作者使用的是360浏览器。
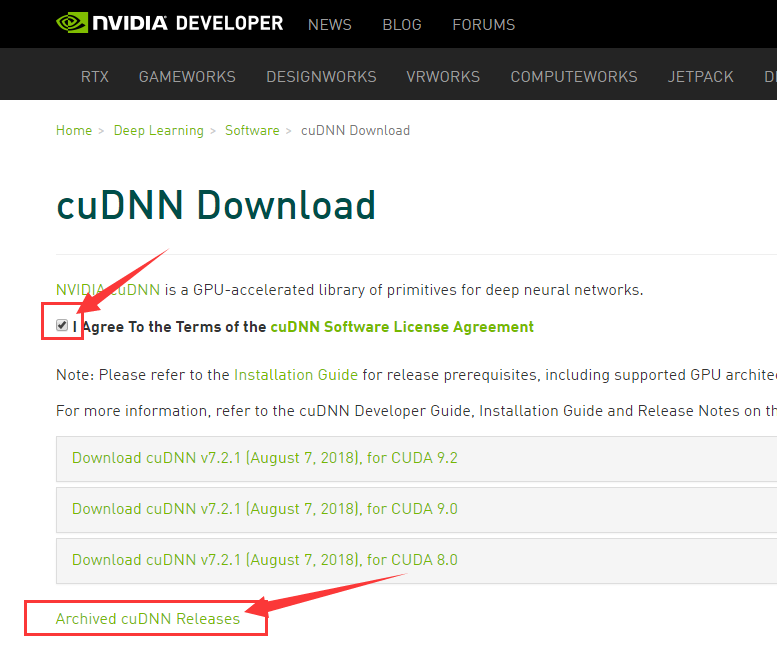
注册成功并登陆后,打开此链接:https://developer.nvidia.com/rdp/cudnn-download
如下图所示,I Agree To the Terms勾选,点击红色箭头所示的Archived cuDNN Releases
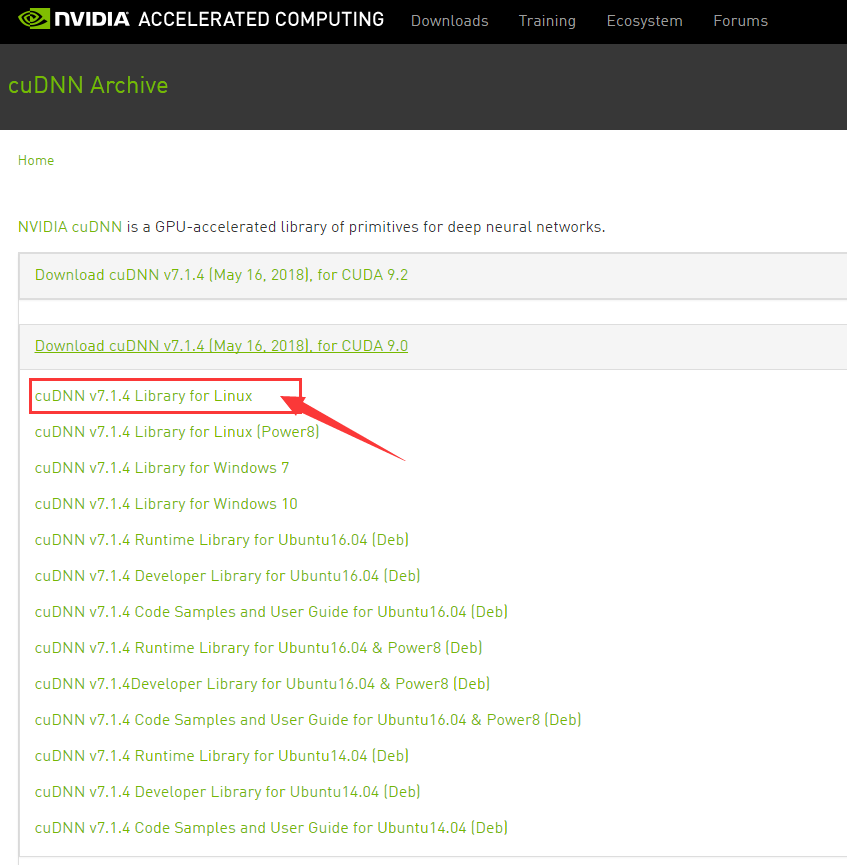
点击下面红色箭头标注处,下载cuDNN7.1。
在 下载窗口中,鼠标移动至下载任务,右击出现如下图所示,选择 复制下载地址。
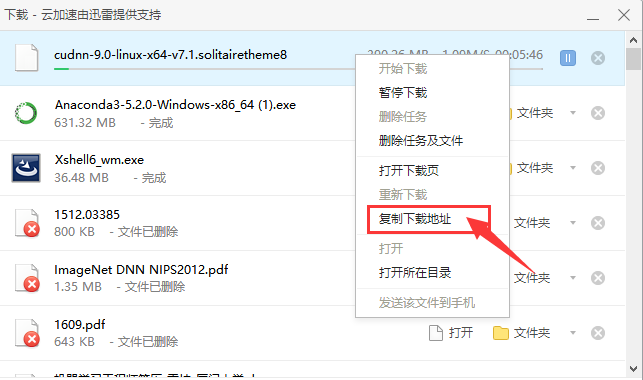
比如作者的下载地址如下,比较长,包括Nvidia的安全策略生成的内容。
https://developer.download.nvidia.com/compute/machine-learning/cudnn/secure/v7.1.4/prod/9.0_20180516/cudnn-9.0-linux-x64-v7.1.tgz?gI80qAjkXwfl6mi1yzIPNnvzbMltcsZcT4KTOsOfipqWZPqhm8SG70m0FpXY-KqiXv-o1xvCep-D3OQOlsjqcjwu9_egoMiawjYz1FFasCgyGaoNOsyy7sCuVBA-nJpzSrH6gotk0g_u6KW6uAceHSFEV6e5GSX-DzyS9BVzD1hppLHXsPBeso2Jkhf9BvMfGStEXDswqvU4sQ
linux系统中下载命令为:wget {},大括号替换为下载链接。
在Xshell的终端中输入命令并运行,读者要根据自己账号的下载链接进行修改。
复制下面命令运行的结果肯定会下载损坏的压缩文件,所以读者必须要注册Nvidia账号。
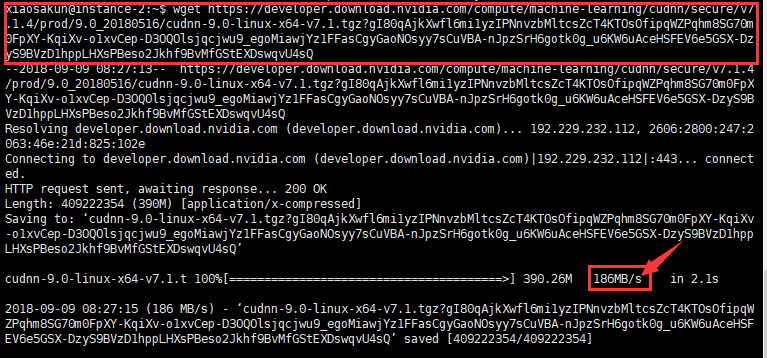
wget https://developer.download.nvidia.com/compute/machine-learning/cudnn/secure/v7.1.4/prod/9.0_20180516/cudnn-9.0-linux-x64-v7.1.tgz?gI80qAjkXwfl6mi1yzIPNnvzbMltcsZcT4KTOsOfipqWZPqhm8SG70m0FpXY-KqiXv-o1xvCep-D3OQOlsjqcjwu9_egoMiawjYz1FFasCgyGaoNOsyy7sCuVBA-nJpzSrH6gotk0g_u6KW6uAceHSFEV6e5GSX-DzyS9BVzD1hppLHXsPBeso2Jkhf9BvMfGStEXDswqvU4sQ
下图上方红色方框内是下载资源wget命令,下方红色箭头标注内容表示186MB/s的下载速度,很快。
linux系统中重命名文件命令为:
mv {} {},第1个大括号替换为原文件名,第2个大括号替换为新文件名。 在Xshell的终端中输入命令并运行,读者要根据自己下载文件名进行修改。
本文作者将下载文件重命名为 cudnn7.1.tgz
mv cudnn-9.0-linux-x64-v7.1.tgz?gI80qAjkXwfl6mi1yzIPNnvzbMltcsZcT4KTOsOfipqWZPqhm8SG70m0FpXY-KqiXv-o1xvCep-D3OQOlsjqcjwu9_egoMiawjYz1FFasCgyGaoNOsyy7sCuVBA-nJpzSrH6gotk0g_u6KW6uAceHSFEV6e5GSX-DzyS9BVzD1hppLHXsPBeso2Jkhf9BvMfGStEXDswqvU4sQ cudnn7.1.tgz
linux系统中解压tgz压缩文件命令为:tar -zxvf {},大括号替换为tgz压缩文件名。
在Xshell的终端中输入命令并运行:tar -zxvf cudnn7.1.tgz
解压文件后,路径下有一个cuda文件夹,运行ls命令,如下图所示:

将cuda文件夹中的文件复制到linux的cuda程序中,两行命令如下:
sudo cp cuda/include/cudnn.h /usr/local/cuda-9.0/include/ sudo cp cuda/lib64/* /usr/local/cuda-9.0/lib64/ 到这里为止,就已经安装cuDNN7.1成功。
6.2 利用网络资源下载并安装cuDNN7.1
本文作者学习如何安装CUDA9.0+cuDNN7.1的博客链接:https://github.com/williamFalcon/tensorflow-gpu-install-ubuntu-16.04
按照顺序执行下面5条命令,即可安装cuDNN7.1成功。wget https://s3.amazonaws.com/open-source-william-falcon/cudnn-9.0-linux-x64-v7.1.tgzsudo tar -xzvf cudnn-9.0-linux-x64-v7.1.tgzsudo cp cuda/include/cudnn.h /usr/local/cuda/includesudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
7.在云虚拟机中安装TensorFlow、Keras
7.1 安装TensorFlow的GPU版本
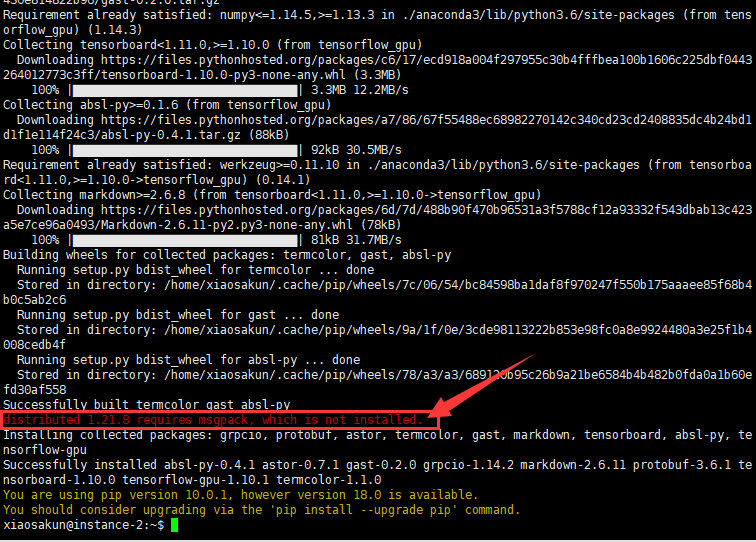
在虚拟机中运行命令:pip install tensorflow_gpu==1.10
运行结果如下图所示,红色方框标注处提示我们安装msgpack库。
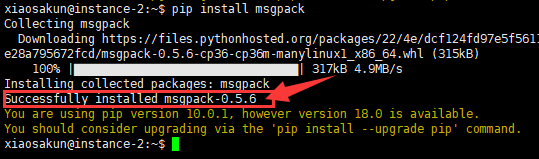
安装 msgpack 库,命令:
pip install msgpack 如下图所示,红色方框标注处提示 安装msgpack库成功。
在虚拟机中运行命令:
vim tensorflowTest.py 进入vim编辑器后按 a键进入编辑模式,复制下面代码到文件中:
import tensorflow as tf
hello = tf.constant(b'hello, tensorflow!')
session = tf.Session()
print(session.run(hello))
代码文件如下图所示:
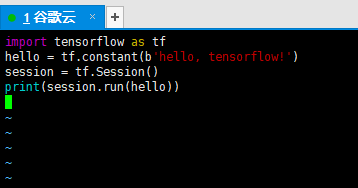
编辑完成后,按 Esc键进入命令模式,输入
:wq并运行,表示保存并退出。 在虚拟机中运行命令:
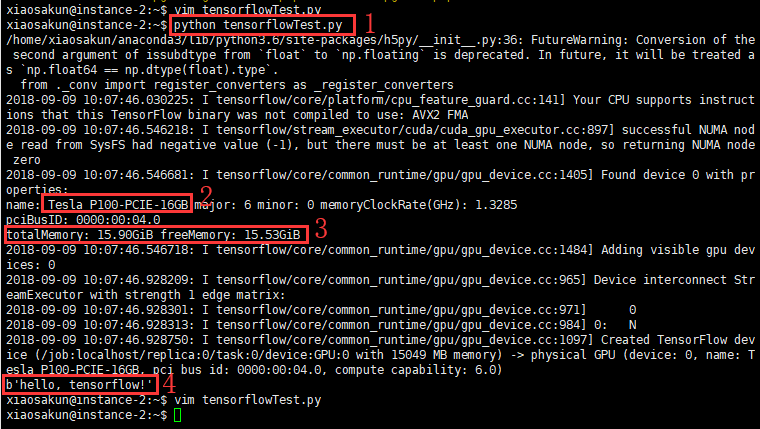
python tensorflowTest.py 如果出现下图所示结果,则表明安装TensorFlow成功。
1号红色方框是虚拟机中运行的命令;
2号红色方框是TensorFlow运行时使用的加速显卡;
3号红色方框是显卡的显存使用情况;
4号红色方框是py文件的执行结果
7.2 安装Keras
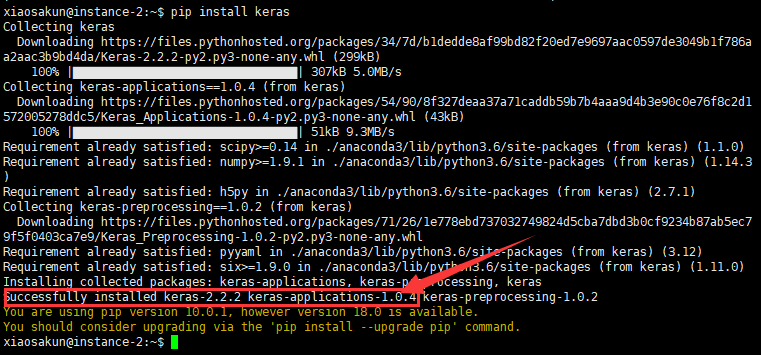
在虚拟机中运行命令:pip install keras
出现下图所示结果,则表明安装keras成功。
8.运行简单例子--基于TensorFlow+CNN的Mnist数据集手写数字分类
在云虚拟机中运行命令:jupyter notebook
开启jupyter服务后,在本机的浏览器中访问链接:localhost:18888
在下图红色方框内输入google,点击Log in。
在云虚拟机中运行命令:
mkdir code,创建文件夹code。 从下图可以看到,确实有文件夹code,点击红色方框标注处,在此文件夹中编辑代码。
进入文件夹code后,界面如下图所示,点击红色箭头标注处创建代码文件。
点击下图红色方框标注处,对文件重命名为 mnistTest
数据准备代码如下:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
sess = tf.InteractiveSession()
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
程序运行代码如下:
import time
startTime = time.time()
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.global_variables_initializer().run()
for i in range(2000):
batch = mnist.train.next_batch(500)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %.4f" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
batch = mnist.test.next_batch(2000)
print("test accuracy %g" % accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}))
print("use {} seconds".format(time.time()-startTime))
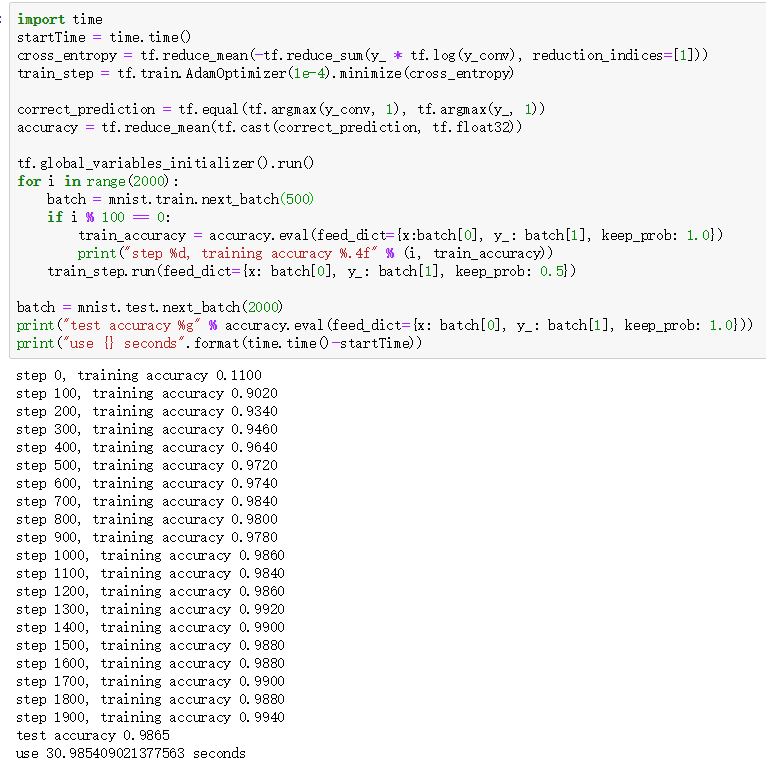
上面一段代码的运行结果如下图所示,按照本文作者的经验,Nvidia P100是Nvidia K80的2倍多计算速度。
9.运行简单例子--基于Keras+resNet的Cifar10数据集图片10分类
进入文件夹code后,界面如下图所示,点击红色箭头标注处创建代码文件。
点击下图红色方框标注处,对文件重命名为 cifar10Test
代码文件下载链接: https://pan.baidu.com/s/1tArwRNo4vUJFZTiwVkS0xA 密码: scub
源代码中epoch为200,本文作者修改为50减少程序运行时间。
epoch中文叫做新纪元,每进行一次epoch,即把所有图片文件给训练一遍。
每次epoch需要30s,源代码中200次epoch则需要6000s,即100分钟。
读者下载代码文件后,可以把文件中的代码复制到jupyter中,然后运行查看结果。
部分运行结果截图如下图所示:

10.总结
本文作者配置CUDA9.2环境、CUDA9.1环境、CUDA8.0环境,都难以实施。
配置CUDA9.0环境才成功,共花费12个小时,之后写作此文又花费10个小时。
直到2018年9月9日,引导新手在谷歌云服务器上搭建深度学习平台的其他指导文章部分已经过时。
所以作者写作此文希望对后来者能够有所帮助,喜欢的朋友就给我点赞吧!!!