文章目录
zookeeper 是什么
https://zookeeper.apache.org/:
ZooKeeper is a centralized service(集群服务) for maintaining(维护) configuration information, naming, providing distributed synchronization(分布式一致性), and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented(实施) there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
虽然上面说了一大堆,但是就实际应用来说,zookeeper始终围绕着一条主线:在分布式系统中协作多个任务。当我们开发的时候,开发人员设计的那些应用往往可以看成一组连接到zookeeper服务器端的客户端,它们通过zookeeper的客户端API 连接到zookeeper的服务器进行相应的操作。
至于为什么用zookeeper,是因为zookeeper有以下功能:
- 保障强一致性、有序性和持久性
- 实现通用的同步原语和能力
- 提供简单的并发处理机制
zookeeper的数据组织
zookeeper的数据组织类似于Linux的文件,不过它在文件树的终点不是文件,而是一个数据节点,被称为znode。下图是zookeeper的数据组织: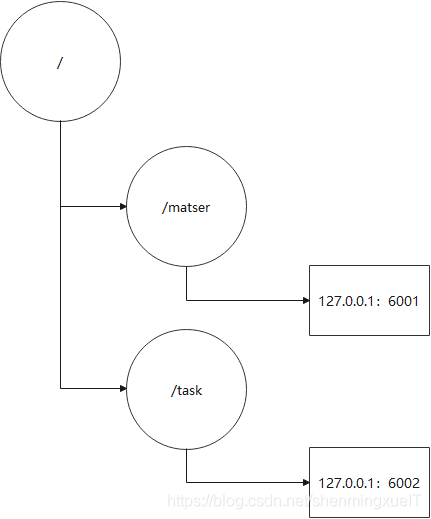
非常像Linux的文件结构。
zookeeper的数据节点类型
上图中的127.0.0.1:6001 和127.0.0.1:6002都是znode节点的数据,/master 和 /task 则是znode 节点,而znode主要分为以下几种:
- 持久节点:就是当这个节点下线时,这个节点也会存在zookeeper服务器中
- 临时节点:它的生命期会跟随它的创建者
- 有序节点:比如说我们创建一个节点server,加入说系统中有server1和server2两个节点,那么它的名字就会是server3
- 临时有序节点:就是上面的临时节点和有序节点的结合
zookeeper的简单 API
主要有以下几种API:
create /path data //创建一个名为/path的znode 节点,包含数据data
delete /path //删除名为/path的znode
exists /path //检查是否存在名为/path的节点
setData /path data //设置名为/path的节点数据为data
getData /path //返回名为/path节点的数据信息
getChildren /path //返回/path节点的所有子节点列表
注意:
zookeeper不允许局部写入或者读取znode节点的数据,也就是你读取数据不能读数据的一半
zookeeper的监视与通知机制
zookeeper提供了基于通知的机制:客户端向zookeeper注册需要接受通知的zonode,通过对znode设置监视点来接受通知。下面是通知机制的示意图: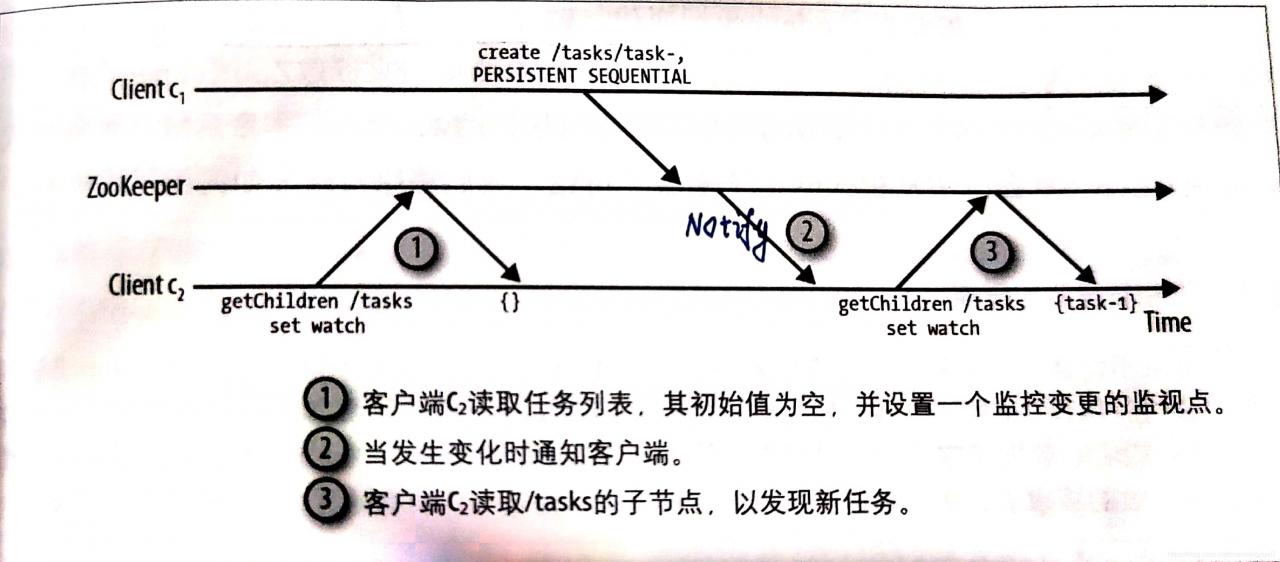
注意:
- 监视是一个一次性操作,即监视只会触发一次通知,之后如还需监视就需要重新设置监视
- 假如是我在通知的时候,如果有客户端c3也添加了一个task,然后我c2下次监视得到的通知就是c3添加的这次动作
zookeeper的版本
对于每个znode节点来说,它都有一个版本号,它随着每次数据变化而自增。假如是有两个API操作可以有条件的执行:setData和delete。这两个调用以版本号作为传入参数,只有当传入参数的版本号和服务器的版本号一致时调用才会成功。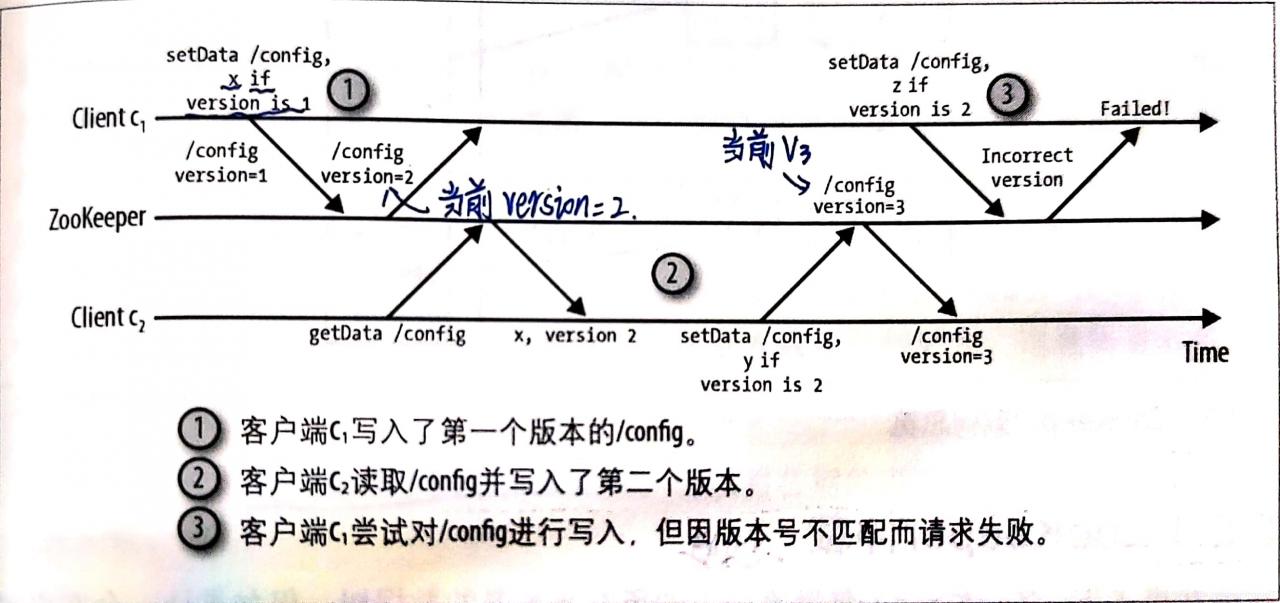
zookeeper的架构
应用一般是调用客户端库来对zookeeper实现调用,客户端库负责与zookeeper服务器端进行交互。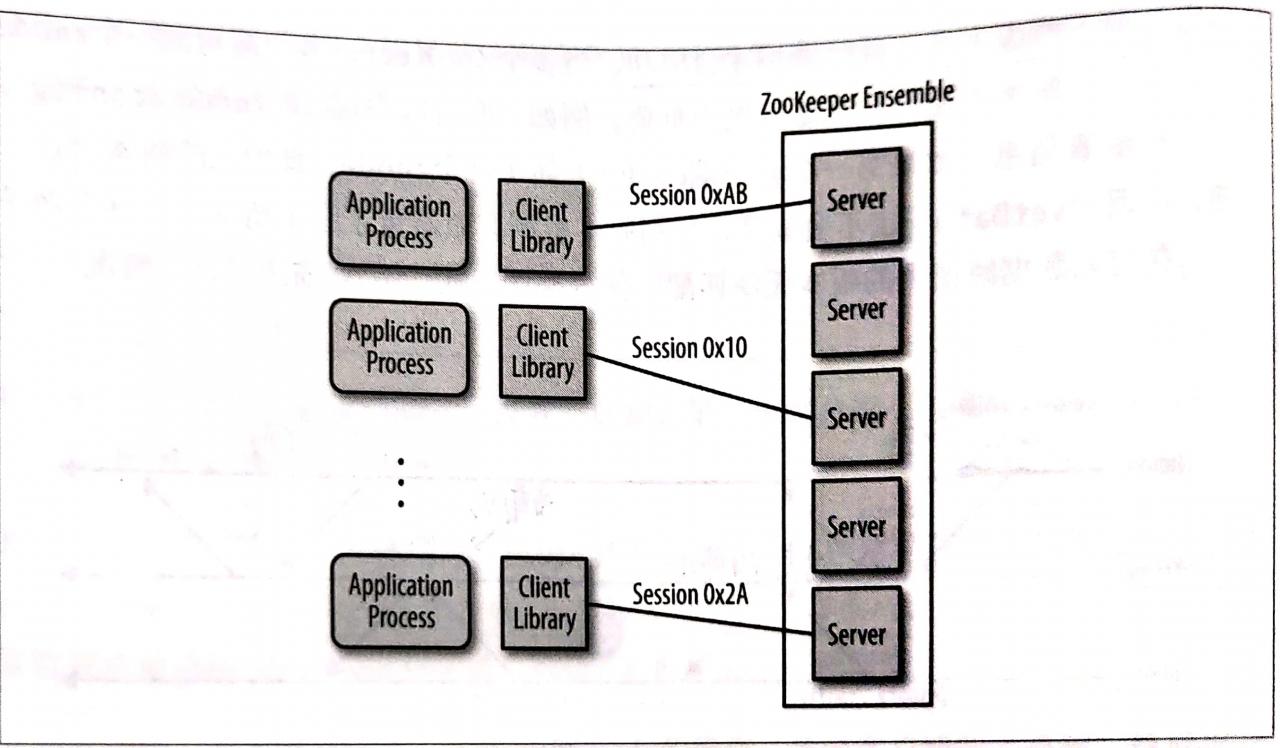
每个客户端导入客户端库,之后便可以与任何zookeeper节点进行通信。
zookeeper服务器模式
zookeeper 服务器运行于两种模式下:独立模式和仲裁模式。
独立模式呢,就是字面意思,有一个单独的服务器,zookeeper状态无法复制。
重载模式呢,就是有一组zookeeper服务器,被称为zookeeper集合(集群的概念),它们之间可以进行状态的复制,并同时为服务与客户端的请求。
仲裁模式
在仲裁模式下,为了保持一致性,zookeeper复制集群中的所有服务器的数据树。但是如果让一个客户端 等待每个服务器完成数据保存后再继续服务,这延迟。。。你能接受么?我接受不了。
zookeeper为了解决这个问题,引入了法定人数等概念。法定人数是指为了使zookeeper工作必须有效运行的服务器的最小数量。例如,假如我们有5个zookeeper服务器,但法定人数为3个,这样,只要有任意三个服务器保存了数据,客户端就可以继续操作。而其他两个服务器最终也将捕获到数据,并保存数据。
会话
在zookeeper集合执行任何请求前。一个客户端必须先与服务建立会话,客户端提交给zookeeper的所有操作均关联在一个会话上。当一个会话因某种原因而中止时,在这个会话期间创建的临时节点将会小时。
当客户端通过语言 API 创建一个zookeeper句柄时,它就会通过服务建立一个会话。如果说过了一段事件之后,这个服务器崩溃了,这个会话就会转移到另一个服务器上,这个对客户端来说都是透明的。
同时,会话提供了顺序保障,意味着同一个会话终端请求会以FIFO的顺序执行,但是如果客户端建立与服务器的多个并发会话的话,FIFO就无法保证了。
参考文献
[1] Flavio Junqueir,Benjamin Reed. Zookeeper分布式过程协同技术详解.机械工业出版社.2020.09