一、安装selenium和webdriver驱动器
1.安装selenium
selenium是python的一个第三方库,可以直接安装,下面介绍两种安装方法:
第一种方法使用pip命令安装,打开计算机运行窗口(win+r),输入以下指令即可安装:
pip install selenium
第二种方法在pycharmd的File>Settings菜单下安装,python interpret下是一些已经安装好的库
点击+号,搜索要安装的库,点击左下角install package就可以安装。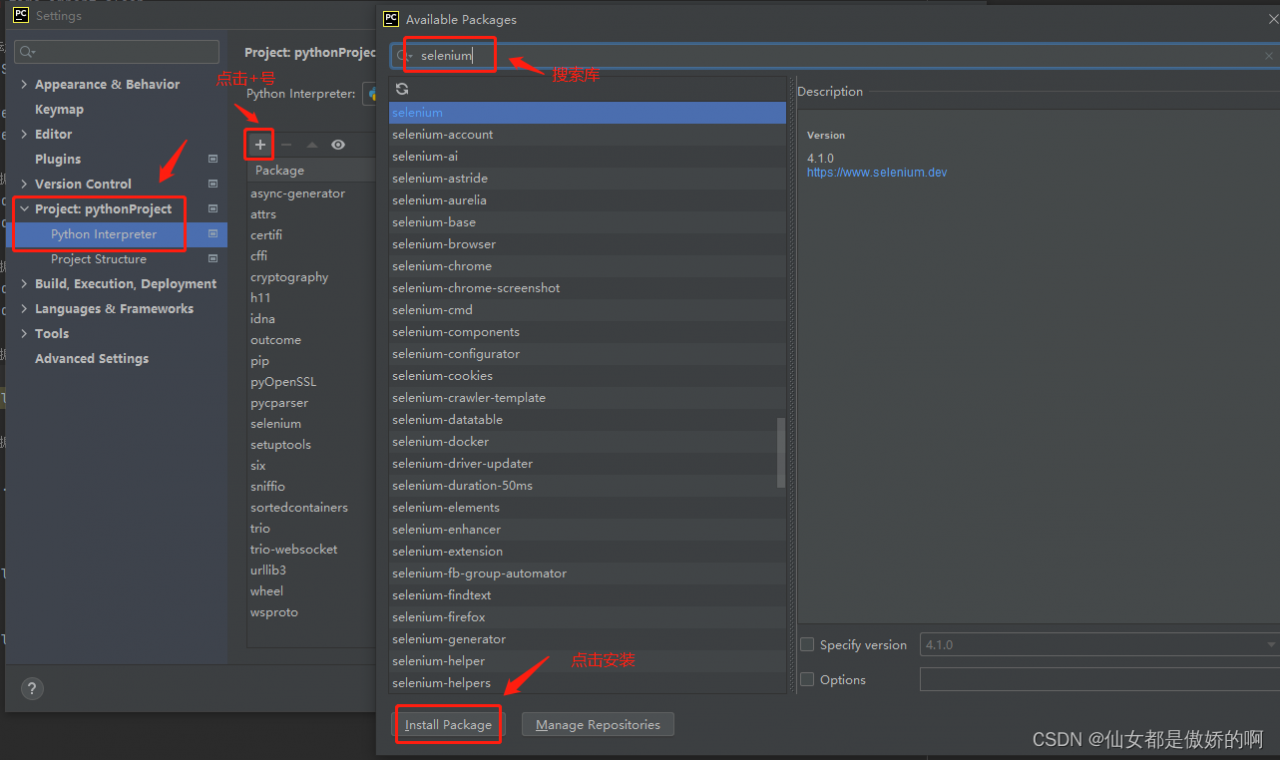
2.下载驱动webdriver
需要下载对应浏览器的驱动,可以自行百度搜索下载,如果用的是chrome浏览器,可以到这个网址下载对应版本:http://chromedriver.storage.googleapis.com/index.html,下载后解压到python安装目录scripts下即可。
二、 定位元素常见的8种方法
以下是几种常见的定位方法:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_class_name
find_element_by_tag_name
find_element_by_css_selector
下面以百度页面为例,介绍这几种方法具体怎么使用:
首先安装完selenium和webdriver后就可以通过驱动获取百度页面
代码如下,
# 导入相关模块
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 打开百度页面
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
1.根据id定位,find_element_by_id
在源码里id具有唯一性,因此通过id定位是比较简单且精准的一种定位方法,但缺点是有的元素没有id值,所以不是所有元素都能使用这种方法定位。
打开网页后,我们用F12键,可以查看网页源码,
如图,我们点击左边红框框出的这个小箭头后,鼠标放在哪便能定位到对应元素,我这里定位的是百度的搜索框
可以看到对应的源码里有一个id值,在python里,我们可以根据这个id来找到搜索框对其操作。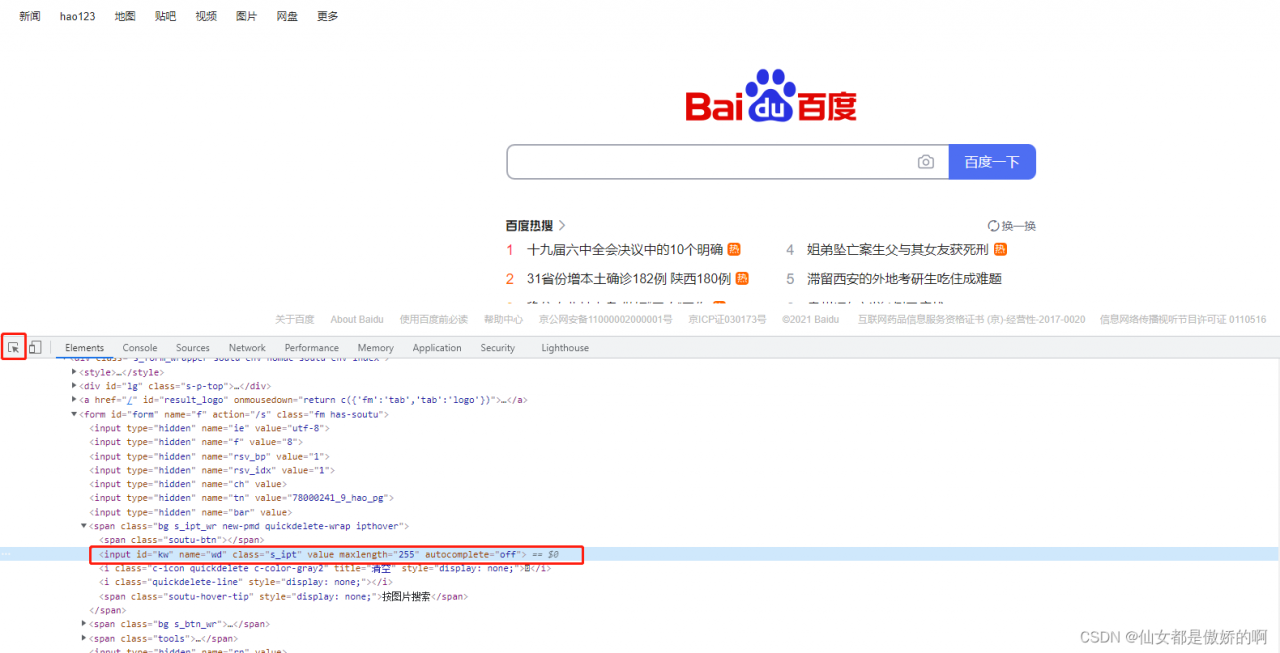
具体怎么使用呢?
这里需要注意一下,之前查找元素的语法是find_element_by_id这种,但现在新的版本不再支持这种写法了,改成了将查找方法以参数的形式传值,
比如用id查找,以前的写法是:driver.find_element_by_id(“kw”),括号里只用传id的值,现在改成了:driver.find_element(By.ID, “kw”),将查找方法和id值都以参数的形式传到括号里,其他的定位方法也一样的,使用新的写法。
下面是一个例子,为了验证成功定位到搜索框,我在定位搜索框之后还输入了内容进行搜索:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 打开百度页面
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 根据id定位
search = driver.find_element(By.ID, "kw")
# 在搜索框里输入值
search.send_keys("李易峰")
# 根据ID定位百度一下按钮
search.button = driver.find_element(By.ID, "su")
#点击百度一下按钮搜索
search.button.click()
2.根据name定位,find_element_by_name
根据name定位,指的是根据元素的名称定位
从上面截图可以看到,搜索框的name值为“wd”
因此,用name定位搜索框可以写成:
# 根据name定位
search = driver.find_element(By.NAME, "wd")
3.根据xpath定位,find_element_by_xpath
xpath是XML Path的简称,HTML文档本身就是一个标准的XML页面,因此可以根据标签名的层级关系来定位
xpath分为绝对路径和相对路径,绝对路径用/表示,相对路径用//表示
我们可以直接将鼠标置于元素上右键copy xpath复制xpath路径,Copy Xpath复制的是相对路径,Copy full Xpath复制的是绝对路径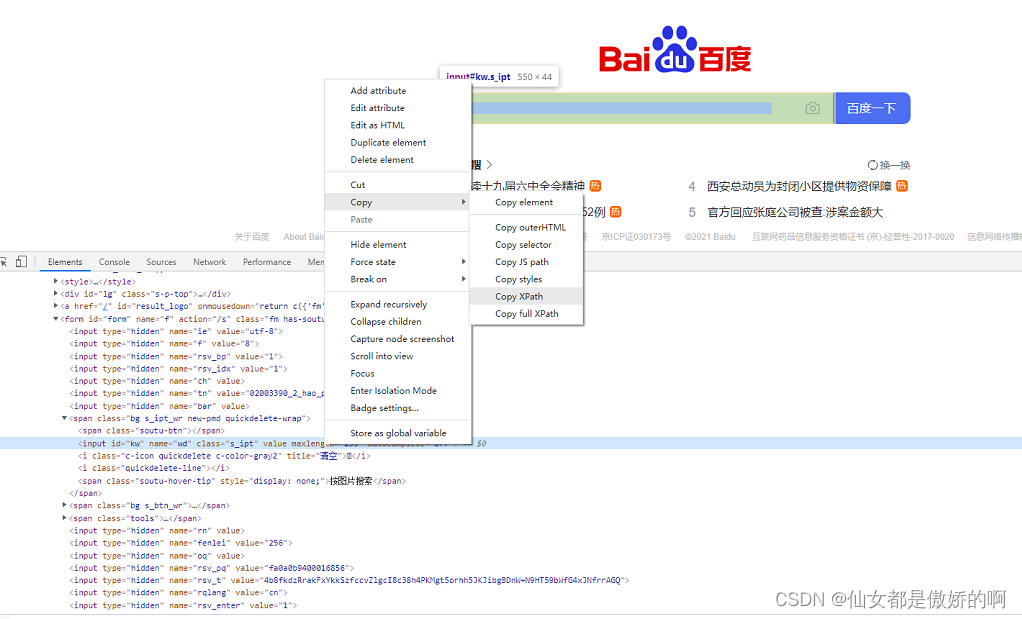
代码如下:
# 根据xpath定位 绝对路径
search = driver.find_element(By.XPATH, "/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input")
# 根据xpath定位 相对路径
search = driver.find_element(By.XPATH, "//*[@id='kw']")
4.根据link_text定位,find_element_by_link_text
link_text指网页中带有超链接的文本,比如百度首页导航栏里的【新闻】、【地图】、【视频】等均可使用此方法
使用时直接在参数直接传文本内容,代码如下:
# 根据link text定位
news = driver.find_element(By.LINK_TEXT, "新闻")
news.click()
5.根据partial_link_text定位,find_element_by_partial_link_text
partial_link_text和link_text差不多,是对于link_text的一种补充,使用link_text时,需要传全部文本,但对于一些文本很长的链接,传全部文本比较麻烦,因此有了partial_link_text,只需要取文本的一部分就可以定位
比如下面的代码,进入百度新闻的页面后,定位“百度首页”链接时,用partial_link_text方法我只需要输入“首页”两个字便可以定位到,在一些文本很长的时候这种方法相比link_text会方便很多
# 打开百度新闻页面
driver = webdriver.Chrome()
driver.get("http://news.baidu.com/")
# 根据partial_link_text定位
news = driver.find_element(By.PARTIAL_LINK_TEXT, "首页")
news.click()
6.根据class_name定位,find_element_by_class_name
class_name是值元素的类名,如百度首页的搜索框对应的class_name为s_ipt,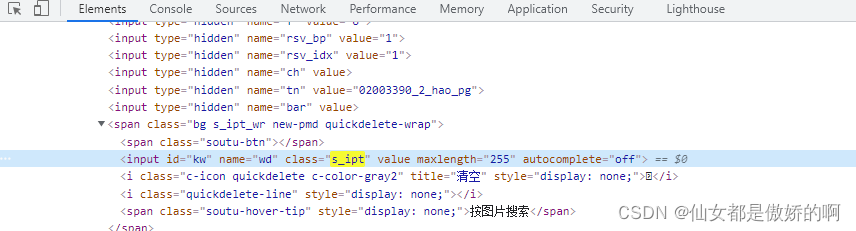
因此,用该方法定位搜索框的代码为:
# 根据class_name定位
search = driver.find_element(By.CLASS_NAME, "s_ipt")
7.根据tag_name定位,find_element_by_tag_name
tag_name指元素的标签,但在页面中标签的重复性很高,因此一般不建议使用这种方法
还是以百度的搜索框为例,搜索框是input标签,代码如下:
# 根据id定位
search = driver.find_element(By.TAG_NAME, "input")
运行代码后我们会发现没有定位到搜索框,因为百度页面有很多重复的input标签,当标签重复时,默认返回的是第一个标签的元素,而这个页面搜索框不是第一个input标签,因此无法正确定位
8.根据css_selector定位,find_element_by_css_selector
selector是css使用的选择器,使用时我们同样可以直接把css_selector的值复制过来使用: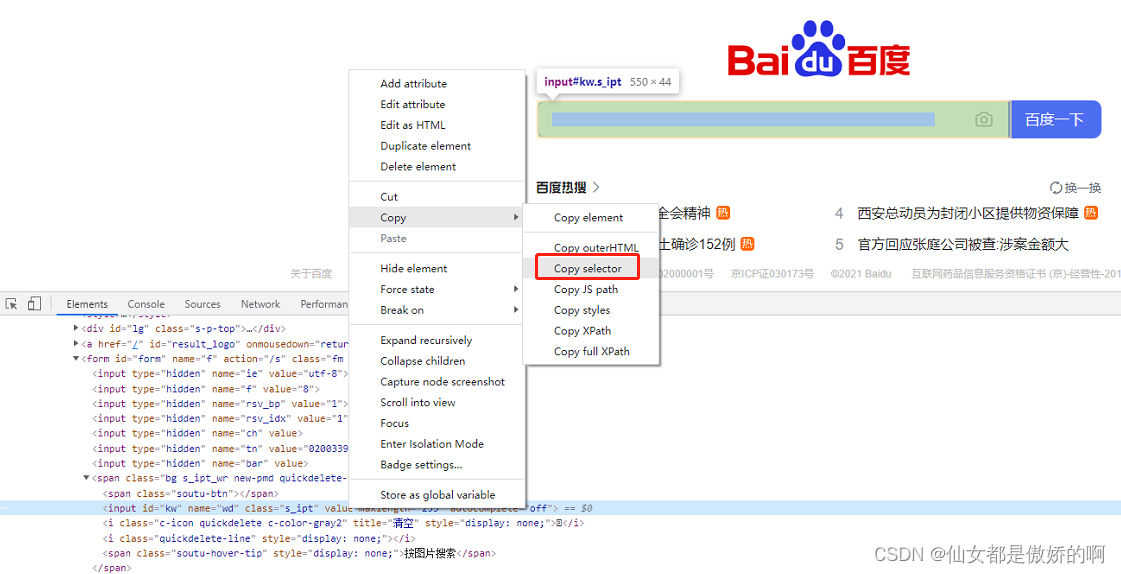
代码如下:
# 根据css_selector定位
search = driver.find_element(By.CSS_SELECTOR, "#kw")