Java 版本:至少1.7
java中识别文字比较简单,使用的软件是tesseractocr(使用的版本是3.02,3以后的版本才支持中文),这个软件需要安装在本地电脑中,安装的过程中全部都按照默认进行安装(以便于Java直接调用),建议使用winRAR解压。
winRAR下载地址: http://download.csdn.net/download/wsk1103/10150343
tess4J下载地址
分流1:http://download.csdn.net/download/wsk1103/9731338
分流2:http://download.csdn.net/download/wsk1103/10268441
中文训练库下载地址
分流1: http://download.csdn.net/download/wsk1103/9731335
分流2: http://download.csdn.net/download/wsk1103/10268436
该软件默认的识别的是英文,如果相要能识别中文,需要将中文的训练文本chi_sim.traineddata存放到C:\Program Files (x86)\Tesseract-OCR\tessdata中,其中该中文训练文本解压后39M左右,遗憾的是如果想要识别中英文的话,还得继续谷歌搜索一下,在这里就不列出来了。
如果想要识别中英文混合的话,参考---基于百度API图片文字识别:
http://blog.csdn.net/wsk1103/article/details/79316220
Java中识别的话很简单,只需要下面这几行代码就可以了
File imageFile=new File(path);
if(!imageFile.exists()){
return"图片不存在";
}
Tesseractinstance=Tesseract.getInstance();
instance.setDatapath("C:\\ProgramFiles(x86)\\Tesseract-OCR\\tessdata");//设置训练库的位置
instance.setLanguage("chi_sim");//中文识别
String result=instance.doOCR(imageFile);
复制代码
我自己封装了一个工具类
package com.wsk.tool;
import net.sourceforge.tess4j.Tesseract;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
/**
* Created by WSK on 2017/1/6.
*/
public class OCR {
/**
*
* @param srImage 图片路径
* @param ZH_CN 是否使用中文训练库,true-是
* @return 识别结果
*/
public static String FindOCR(String srImage, boolean ZH_CN) {
try {
System.out.println("start");
double start=System.currentTimeMillis();
File imageFile = new File(srImage);
if (!imageFile.exists()) {
return "图片不存在";
}
BufferedImage textImage = ImageIO.read(imageFile);
Tesseract instance=Tesseract.getInstance();
instance.setDatapath("C:\\Program Files (x86)\\Tesseract-OCR\\tessdata");//设置训练库
if (ZH_CN)
instance.setLanguage("chi_sim");//中文识别
String result = null;
result = instance.doOCR(textImage);
double end=System.currentTimeMillis();
System.out.println("耗时"+(end-start)/1000+" s");
return result;
} catch (Exception e) {
e.printStackTrace();
return "发生未知错误";
}
}
public static void main(String[] args) throws Exception {
String result=FindOCR("D:\\test2.png",true);
System.out.println(result);
}
}
复制代码
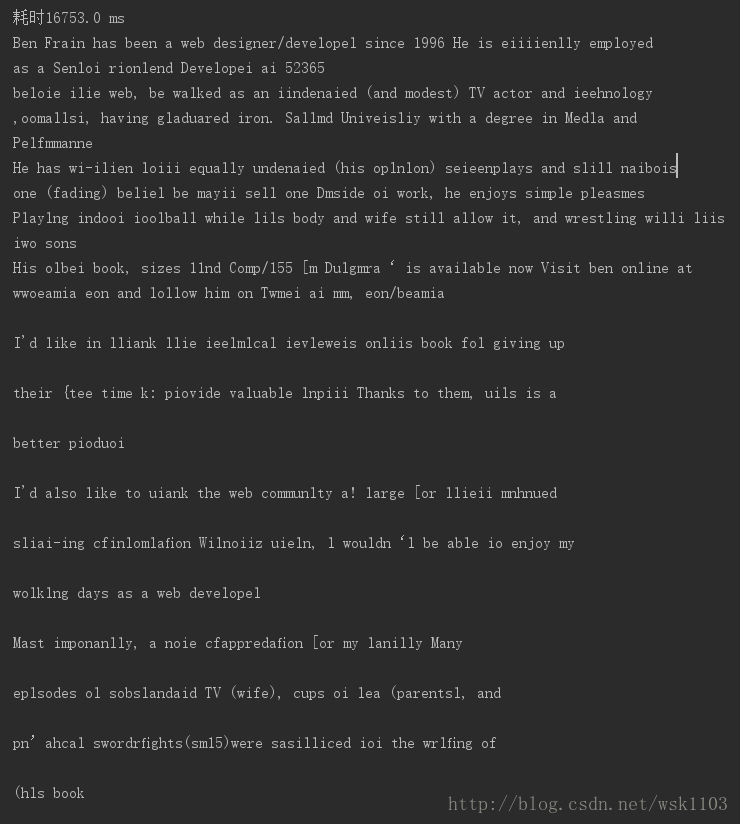
英文识别效果还是杠杠的
###英文识别图
结果
中文识别图

中文识别结果

关于异常
1. Exception in thread "main" java.lang.Error: Invalid memory access
这个异常表示没有设置训练库的位置
2. 不是有效的win32程序
尝试重新安装一下tesseractocr
安装的路径默认就可以了。
3. Exception in thread "main" java.lang.UnsupportedClassVersionError: net/sourceforge/tess4j/Tesseract :
发生该异常的原因是JDK版本低于1.7,使用1.7以上即可解决问题。
复制代码