目标检测——评价指标
TP、FP、TN、FN、Recall、Precision
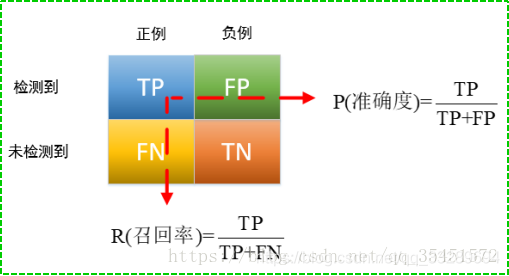
| 符号 | 意义 |
|---|---|
| TP(True positives ) | 真的正样本,正样本被预测为正样本 |
| FP (False positives) | 假的正样本,实际是负样本,但是预测为正样本 |
| TN (True negatives) | 真的负样本,负样本被预测为负样本 |
| FN(False negatives) | 假的负样本,实际是正样本,但是预测为负样本 |
召回率(Recall Rate):给出的是预测为正样本中的真正正样本的比例。如图所示。
准确率(Precision Rate)预测为正样本中真正正样本的比例。
从图中可以看到二者具体的区别
TPR、TFR、FPR、FNR
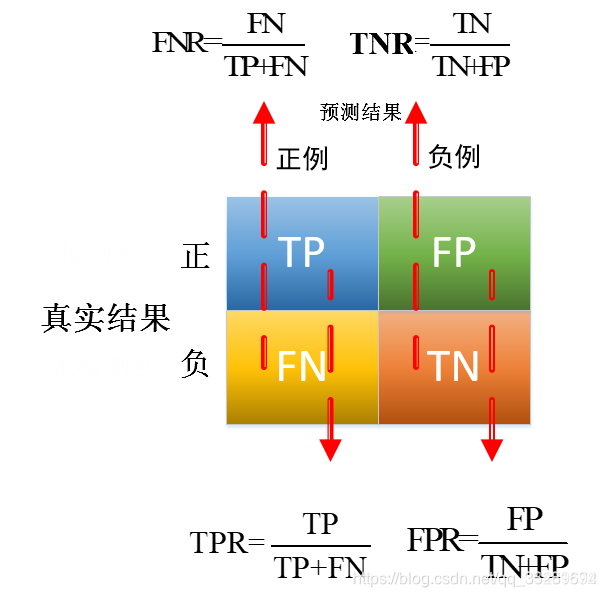
如图中所示的各个评价指标
AP、mAP、P-R曲线
准确率-召回率曲线(P-R曲线):以召回率为横坐标,精确率为纵坐标,用不同的阀值,统计出一组不同阀值下的精确率和召回率。
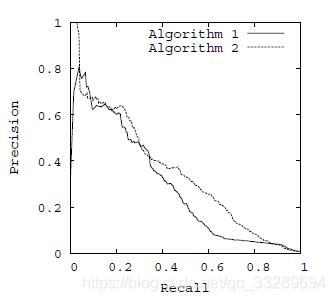
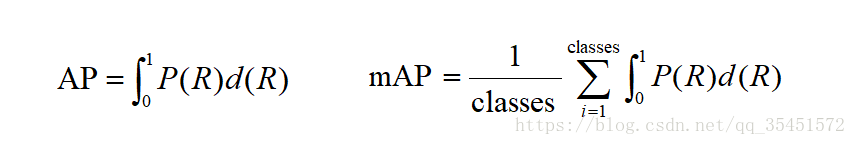
AP(average precision)——P-R曲线下的面积;
mAP(mean average precision)——多个类别AP的平均值。
ROC曲线、AUC
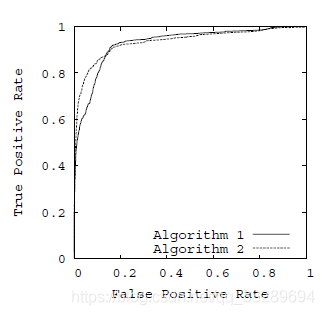
ROC(receiver operating characterstic)曲线:当阈值变化时假阳率和真阳率的变化情况。在理想情况下,最佳的分类器,应尽可能的处于左上角,这就意味着分类器在假阳率很低的同时,获得了很高的真阳率。例如在垃圾邮件的过滤中,这就相当于过滤了所有的垃圾邮件,但没有将任何合法邮件误识别为垃圾邮件而放入垃圾邮件的文件夹中。
AUC(Area Under Curve):ROC曲线下的面积。AUC给出的是分类器的平均性能值,一个完美的分类器的AUC是1.0。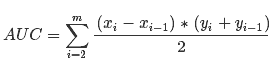
IOU:二者之间交集除以并集
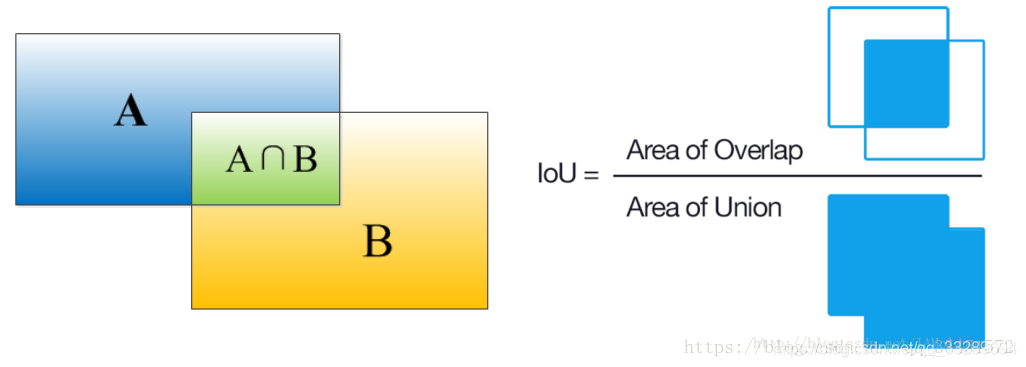
IOU(Intersection over Union):是一种测量在特定数据集中检测相应物体准确度的一个标准,一般来说,这个score > 0.5 就可以被认为一个不错的结果了。可以这样理解为系统预测出来的框与原来图片中标记的框的重合程度。
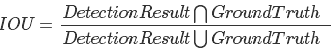
F1、FPS、FLOPS
F1: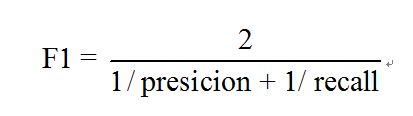
Fps (Frames Per Second):每秒处理图像的帧数
FLOPS:每秒浮点运算次数、每秒峰值速度
非极大值抑制(NMS)
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。对于有重叠在一起的预测框,只保留得分最高的那个。
(1)NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中首个要比较的对象;
(2)计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU得预测框;
(3)然后重复上面的过程,直至候选bounding box为空。
最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N次。
参考博客
https://blog.csdn.net/Gentleman_Qin/article/details/84519388
https://blog.csdn.net/qq_35451572/article/details/80272968