看lucene主页(http://lucene.apache.org/)上目前lucene已经到4.9.0版本了, 参考学习的书是按照2.1版本讲解的,写的代码例子是用的3.0.2版本的,版本
的不同导致有些方法的使用差异,但是大体还是相同的。
参考资料:
1、公司内部培训资料
2、《Lucene搜索引擎开发权威经典》于天恩著.
Lucene使用挺简单的,耐心看完都能学会,还有源代码。
索引的创建一文中介绍了创建Lucene索引的基本方法。索引建好以后,就可以执行搜索了。执行搜索的过程就是:将用户输入的关键字进行处理,从而得到搜索结果。
使用Lucene执行搜索,首先要创建IndexSearcher对象,然后通过Term和Query对象来封装用户输入的搜索条件,最后将结果封装在Hits对象中,返回给用户。
本文主要要介绍Query对象的几个子类给我们提供的不同的搜索方法。
indexSearcher.search(Query q):这个方法是对索引进行检索,是整个检索系统的核心。 其中q是Query对象的子类
首先为下面几个实例提前创建一个索引:
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
/**
* 创建一个索引
*
* @author Administrator
*
*/
public class CreateLuceneIndex {
private static String Brazil = "唯一参加过此前全部19届世界杯决赛圈的球队,世界足坛真正的王者,"
+ "5次夺得世界杯桂冠。上次夺魁是2002年的韩日世界杯,由3R(罗纳尔多、罗纳尔迪尼奥、里瓦尔多)"
+ "领衔的桑巴舞者倾倒东亚乃至整个世界,以7战全胜的战绩轻松登顶。上届世界杯,前队长邓加执教"
+ "的巴西八强战1-2不敌荷兰。本届世界杯作为东道主的他们自动晋级决赛圈。该队主帅恰好是率队夺"
+ "得韩日世界杯桂冠的斯科拉里,去年年底他临危受命,代替梅内塞斯,再度执教桑巴军团。球队头牌"
+ "是今夏刚刚登陆巴萨的内马尔,蒂亚戈-席尔瓦、阿尔维斯、奥斯卡、胡尔克等名将在阵。世界杯最好战绩"
+ ":冠军(1958、1962、1970、1994、2002)";
private static String Argentina = "此前15次参赛,4次进入决赛,在1978年及1986年两次夺冠。上届南非世界杯,"
+ "他们在八强战耻辱性地被德国4球横扫。本次世预赛,阿根廷取得9胜5平2负的战绩,以32分拿到南美区头名。"
+ "该队主帅是2011年接过教鞭的萨维利亚,曾经常年担任帕萨雷拉助教的他2009年才开启主帅生涯,率大学生夺"
+ "得解放者杯是其巅峰。探戈军团的王牌无疑是梅西,完成过金球奖四连庄的他要想成为真正意义上的球王,必须"
+ "率队拿下世界杯桂冠,阿奎罗、伊瓜因、马斯切拉诺等名将将是梅西最可倚重的助手。"
+ "世界杯最好战绩:冠军(1978、1986)";
private static String Holland = "此前9次参赛,3次杀进决赛圈,但均屈居亚军。上届南非世界杯,他们只是加时赛惜"
+ "败西班牙。此次世预赛,橙军与罗马尼亚、匈牙利、土耳其、爱沙尼亚以及安道尔同组,取得9胜1平的战绩,是"
+ "欧洲区首支晋级决赛阶段的球队。该队主帅是二进宫的前巴萨及拜仁名帅范加尔,他也是让橙军迅速走出去年欧洲"
+ "杯惨败低谷的关键人物。队内拥有范佩西、罗本、斯内德、范德法特等中前场名将,若能做好防守,橙军有望在巴"
+ "西再创佳绩。世界杯最好战绩:亚军(1974、1978、2010)";
private static String Spain = "此前13次出战世界杯,1950年获得殿军,上届淘汰赛连克葡萄牙、巴拉圭、德国以及荷兰,"
+ "最终捧得世界杯桂冠,也成为首支在非欧洲大陆夺冠的欧洲球队。巴西世界杯预选赛,西班牙与法国、芬兰、格鲁"
+ "吉亚及白俄罗斯同组,取得6胜2平的不败战绩,以小组头名晋级。该队由冠军教头博斯克坐镇,后场拥有卡西利亚"
+ "斯、皮克、拉莫斯等强将,中场有哈维、伊涅斯塔、布斯克茨、阿隆索等世界级球员,前场也有席尔瓦、马塔、迭"
+ "戈.科斯塔、托雷斯、略伦特等大牌。今年的联合会杯,他们决赛0-3不敌东道主巴西。世界杯最好战绩:冠军(2010)";
private static String France = "此前13次参赛,最好成绩是1998年在本土举办的世界杯上折桂,其中决赛3-0轻取巴西。此次"
+ "世预赛,他们与西班牙、格鲁吉亚、芬兰以及白俄罗斯同组,取得5胜2平1负的战绩,以小组第二身份出战附加赛,总"
+ "比分3-2惊险逆转乌克兰晋级。该队主帅是率队捧得世界杯的前队长德尚。阵中头牌无疑是今年的欧洲最佳球员及金球奖"
+ "大热里贝里,科斯切尔尼、吉鲁、本泽马等球员也声名赫赫。世界杯最好战绩:冠军(1998)";
private static String Italy = "此前19届世界杯仅两次缺席决赛阶段,4次夺冠的成绩仅次于巴西,2006年在现任恒大主帅里皮的"
+ "率领下登顶,但上届却折戟小组赛。此次世预赛,意大利与保加利亚、马耳他、亚美尼亚、丹麦以及捷克同组,以6胜4平"
+ "的不败战绩拿到小组头名。该队主帅是前佛罗伦萨名帅普兰德利,2010年世界杯后接过教鞭。布冯、德罗西以及皮尔洛仍"
+ "是队中砥柱,锋线的巴洛特利同样值得期待。世界杯最好战绩:冠军(1934、1938、1982、2006)";
private static String Germany = "此前17次出战世界杯3次夺魁,但1990年后的5届比赛仅1次杀进决赛(日韩世界杯夺得亚军),本"
+ "届世预赛他们与法罗群岛、奥地利、爱尔兰、瑞典以及哈萨克斯坦同组,取得9胜1平的骄人战绩,以小组头名晋级。该队主帅"
+ "勒夫2006年开始执教,连续3届大赛率队杀进前四,拥有拉姆、施魏因斯泰格、罗伊斯、厄齐尔等大牌球星的德意志战车目标"
+ "只有冠军。";
private static String China = "2002年韩日世界杯首次参加世界杯,曾打出'进一球,平一场,得一分'的口号。结果一球未进,一分未得,"
+ "世界杯最好战绩:第31名";
public static void main(String[] args) {
File file = new File("E:\\Football");
try {
Directory dir = new SimpleFSDirectory(file);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
IndexWriter indexWriter = new IndexWriter(dir, analyzer, true,
IndexWriter.MaxFieldLength.LIMITED);
Document doc1 = new Document();
Document doc2 = new Document();
Document doc3 = new Document();
Document doc4 = new Document();
Document doc5 = new Document();
Document doc6 = new Document();
Document doc7 = new Document();
Document doc8 = new Document();
Field field10 = new Field("TeamNum", "00001", Field.Store.YES,
Field.Index.ANALYZED);
Field field11 = new Field("TeamName", "巴西", Field.Store.YES,
Field.Index.ANALYZED);
Field field12 = new Field("TeamBoss", "内马尔", Field.Store.YES,
Field.Index.ANALYZED);
Field field13 = new Field("TeamCoach", "斯科拉里", Field.Store.YES,
Field.Index.ANALYZED);
Field field14 = new Field("TeamInfo", Brazil, Field.Store.NO,
Field.Index.ANALYZED);
doc1.add(field10);
doc1.add(field11);
doc1.add(field12);
doc1.add(field13);
doc1.add(field14);
Field field20 = new Field("TeamNum", "00002", Field.Store.YES,
Field.Index.ANALYZED);
Field field21 = new Field("TeamName", "阿根廷", Field.Store.YES,
Field.Index.ANALYZED);
Field field22 = new Field("TeamBoss", "梅西", Field.Store.YES,
Field.Index.ANALYZED);
Field field23 = new Field("TeamCoach", "萨维利亚", Field.Store.YES,
Field.Index.ANALYZED);
Field field24 = new Field("TeamInfo", Argentina, Field.Store.NO,
Field.Index.ANALYZED);
doc2.add(field20);
doc2.add(field21);
doc2.add(field22);
doc2.add(field23);
doc2.add(field24);
Field field30 = new Field("TeamNum", "00003", Field.Store.YES,
Field.Index.ANALYZED);
Field field31 = new Field("TeamName", "荷兰", Field.Store.YES,
Field.Index.ANALYZED);
Field field32 = new Field("TeamBoss", "范佩西", Field.Store.YES,
Field.Index.ANALYZED);
Field field33 = new Field("TeamCoach", "范加尔", Field.Store.YES,
Field.Index.ANALYZED);
Field field34 = new Field("TeamInfo", Holland, Field.Store.NO,
Field.Index.ANALYZED);
doc3.add(field30);
doc3.add(field31);
doc3.add(field32);
doc3.add(field33);
doc3.add(field34);
Field field40 = new Field("TeamNum", "00004", Field.Store.YES,
Field.Index.ANALYZED);
Field field41 = new Field("TeamName", "西班牙", Field.Store.YES,
Field.Index.ANALYZED);
Field field42 = new Field("TeamBoss", "伊涅斯塔", Field.Store.YES,
Field.Index.ANALYZED);
Field field43 = new Field("TeamCoach", "博斯克", Field.Store.YES,
Field.Index.ANALYZED);
Field field44 = new Field("TeamInfo", Spain, Field.Store.NO,
Field.Index.ANALYZED);
doc4.add(field40);
doc4.add(field41);
doc4.add(field42);
doc4.add(field43);
doc4.add(field44);
Field field50 = new Field("TeamNum", "00005", Field.Store.YES,
Field.Index.ANALYZED);
Field field51 = new Field("TeamName", "法国", Field.Store.YES,
Field.Index.ANALYZED);
Field field52 = new Field("TeamBoss", "本泽马", Field.Store.YES,
Field.Index.ANALYZED);
Field field53 = new Field("TeamCoach", "德尚", Field.Store.YES,
Field.Index.ANALYZED);
Field field54 = new Field("TeamInfo", France, Field.Store.NO,
Field.Index.ANALYZED);
doc5.add(field50);
doc5.add(field51);
doc5.add(field52);
doc5.add(field53);
doc5.add(field54);
Field field60 = new Field("TeamNum", "00006", Field.Store.YES,
Field.Index.ANALYZED);
Field field61 = new Field("TeamName", "意大利", Field.Store.YES,
Field.Index.ANALYZED);
Field field62 = new Field("TeamBoss", "巴洛特利", Field.Store.YES,
Field.Index.ANALYZED);
Field field63 = new Field("TeamCoach", "普兰德利", Field.Store.YES,
Field.Index.ANALYZED);
Field field64 = new Field("TeamInfo", Italy, Field.Store.NO,
Field.Index.ANALYZED);
doc6.add(field60);
doc6.add(field61);
doc6.add(field62);
doc6.add(field63);
doc6.add(field64);
Field field70 = new Field("TeamNum", "00002000", Field.Store.YES,
Field.Index.ANALYZED);
Field field71 = new Field("TeamName", "德国", Field.Store.YES,
Field.Index.ANALYZED);
Field field72 = new Field("TeamBoss", "托马斯.穆勒", Field.Store.YES,
Field.Index.ANALYZED);
Field field73 = new Field("TeamCoach", "勒夫", Field.Store.YES,
Field.Index.ANALYZED);
Field field74 = new Field("TeamInfo", Germany, Field.Store.NO,
Field.Index.ANALYZED);
doc7.add(field70);
doc7.add(field71);
doc7.add(field72);
doc7.add(field73);
doc7.add(field74);
Field field80 = new Field("TeamNum", "00001000", Field.Store.YES,
Field.Index.ANALYZED);
Field field81 = new Field("TeamName", "中国", Field.Store.YES,
Field.Index.ANALYZED);
Field field82 = new Field("TeamBoss", "郜林", Field.Store.YES,
Field.Index.ANALYZED);
Field field83 = new Field("TeamCoach", "阿兰.佩林", Field.Store.YES,
Field.Index.ANALYZED);
Field field84 = new Field("TeamInfo", China, Field.Store.NO,
Field.Index.ANALYZED);
doc8.add(field80);
doc8.add(field81);
doc8.add(field82);
doc8.add(field83);
doc8.add(field84);
indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2);
indexWriter.addDocument(doc3);
indexWriter.addDocument(doc4);
indexWriter.addDocument(doc5);
indexWriter.addDocument(doc6);
indexWriter.addDocument(doc7);
indexWriter.addDocument(doc8);
indexWriter.optimize();
indexWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
一、TermQuery 词条搜索
Lucene内最为简单也最为原始的一种搜索方式
<span style="font-family:SimSun;font-size:12px;">import java.io.File;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
public class LuceneTermQuery {
public static void main(String[] args) {
try {
// 检索
Directory dir = SimpleFSDirectory.open(new File("E:\\Football"));
IndexSearcher indexSearcher = new IndexSearcher(dir);
Term term = new Term("TeamInfo", "冠");// 在字段TermName包含“冠”字的文档
Query query = new TermQuery(term);
TopDocs topDocs = indexSearcher.search(query, 10);// 10
// 代表取搜索结果评分最高的前10个,至于怎么评分的,我没搞清楚
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
int totalLength = topDocs.totalHits;
int scoreLength = scoreDocs.length;
System.out.println("Total Hit:" + totalLength);// 满足条件个数
System.out.println("Score Hit:" + scoreLength);// 实际返回个数
System.out.println("******************************");
for (int i = 0; i < scoreLength; i++) {
System.out.println(indexSearcher.doc(scoreDocs[i].doc));
System.out.println(scoreDocs[i].score);
System.out.println("==============================");
}
} catch (Exception e) {
e.printStackTrace();
}
}
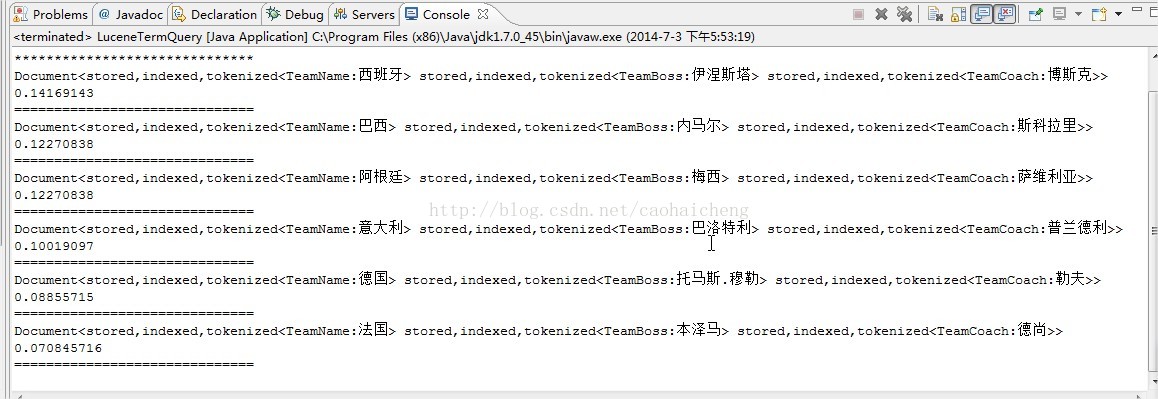
}</span>执行结果控制台截图:
二、BooleanQuery 布尔搜索
Lucene的各种复杂查询最终都可以转换成boolean型的查询
1)、MUST表示搜索结果必须满足该Term
2) 、SHOULD表示搜索结果可以满足该Term
3) 、MUST_NOT表示搜索结果不许满足该Term(单独使用无意义)
关于这三个相互间连用会产生结果不写了,因为我感觉描述起来很容易让人产生误解,最好还是自己运行例子一次一次的试验结果,然后将自己理解的记住就行了
<span style="font-family:SimSun;font-size:12px;"><span style="font-family:SimSun;font-size:12px;">import java.io.File;
import java.io.IOException;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
public class LuceneBooleanQuery1 {
public static void main(String[] args) {
try {
Directory dir= SimpleFSDirectory.open(new File("E:\\FootBall"));
IndexSearcher indexSearcher =new IndexSearcher(dir);
Term t1=new Term("TeamInfo","冠");
Term t2=new Term("TeamName","国");
Term t3=new Term("TeamBoss","西");
Term t4=new Term("TeamBoss","林");
Query tq1=new TermQuery(t1);
Query tq2=new TermQuery(t2);
Query tq3=new TermQuery(t3);
Query tq4=new TermQuery(t4);
BooleanQuery booleanQuery =new BooleanQuery();
//条件满足 : TeamBoss中含有'西'的满足 TeamName中不含有'国'的满足 取二者交集
/* booleanQuery.add(tq3,BooleanClause.Occur.SHOULD);
booleanQuery.add(tq2,BooleanClause.Occur.MUST_NOT);*/
//条件满足 :TeamBoss中含有'西'的满足 TeamName中含有'林'的满足 取二者并集
booleanQuery.add(tq3,BooleanClause.Occur.SHOULD);
booleanQuery.add(tq4,BooleanClause.Occur.SHOULD);
TopDocs topDocs = indexSearcher.search(booleanQuery, 10);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
int totalLength = topDocs.totalHits;
int scoreLength = scoreDocs.length;
System.out.println("Total Hit:" + totalLength);
System.out.println("Score Hit:" + scoreLength);
System.out.println("******************************");
for (int i = 0; i < scoreLength; i++) {
System.out.println(indexSearcher.doc(scoreDocs[i].doc));
System.out.println(scoreDocs[i].score);
System.out.println("==============================");
}
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
}
}
}
</span></span>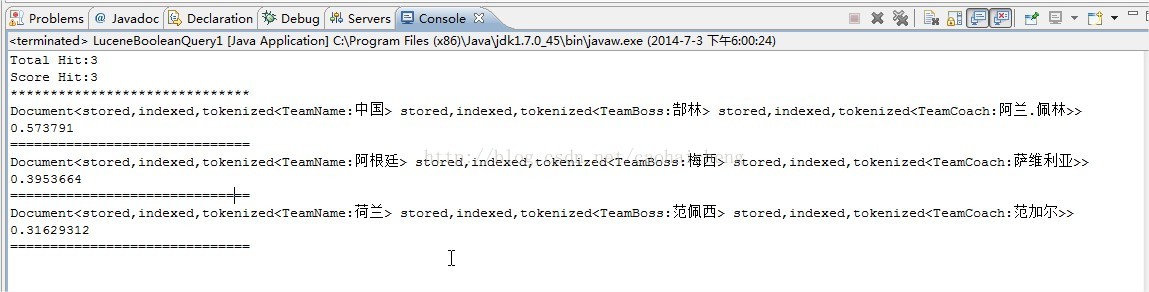
三、范围搜索 TermRangeQuery
注意:TermRangeQuery针对的是字符串的范围搜索,而不是数字型的,举个例子 “000020000” 是在“00001”和“00004”之间的
import java.io.File;
import java.io.IOException;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
public class LuceneRangeQuery {
public static void main(String[] args) {
try {
Directory dir= SimpleFSDirectory.open(new File("E:\\FootBall"));
IndexSearcher indexSearcher=new IndexSearcher(dir);
//参数:1、要索引的字段 2、起始值 3、终点值 4、是否包含起始值(是否闭区间) 5、是否包含重点值
TermRangeQuery q=new TermRangeQuery("TeamNum", "00001", "00005", true, true);
TopDocs topDocs = indexSearcher.search(q, 10);// 10
// 代表取搜索结果评分最高的前10个,至于怎么评分的,我没搞清楚
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
int totalLength = topDocs.totalHits;
int scoreLength = scoreDocs.length;
System.out.println("Total Hit:" + totalLength);// 满足条件个数
System.out.println("Score Hit:" + scoreLength);// 实际返回个数
System.out.println("******************************");
for (int i = 0; i < scoreLength; i++) {
System.out.println(indexSearcher.doc(scoreDocs[i].doc));
System.out.println(scoreDocs[i].score);
System.out.println("==============================");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
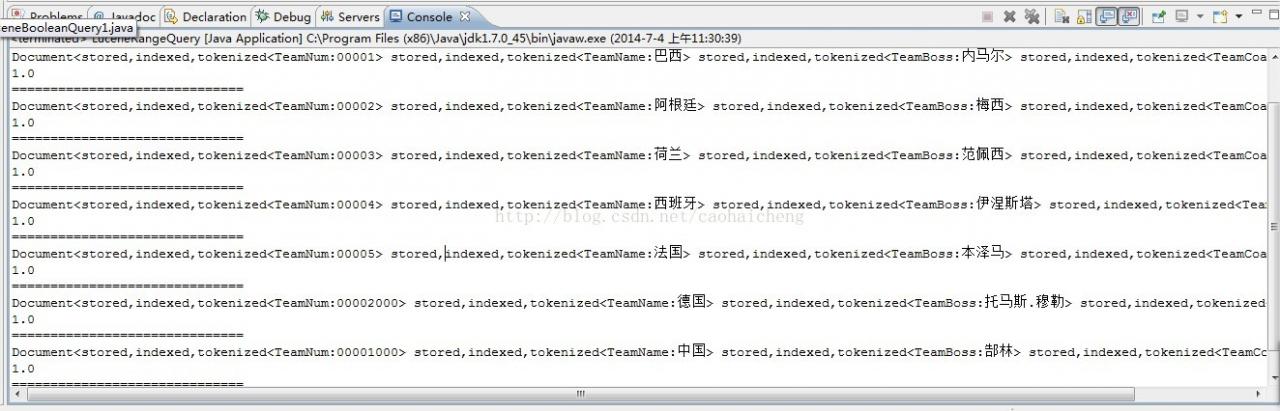
可以看到,中国(00001000)和德国(00002000)也被检索出来了
(在较早版本的Lucene,对一定范围内的查询所对应的查询对象是RangeQuery,然而其仅支持字符串形式的范围查询,因为Lucene 3.0提供了数字形式的范围查询NumericRangeQuery,所以原来的RangeQuery变为TermRangeQuery。)
关于NumericRangeQuery不说了,用的时候再去查,直到有这个就行了。
四、前缀搜索 PrefixQuery
例如查找一本书,只记得书前面的几个字,就可以用前缀搜索的形式去查找
<span style="font-family:SimSun;font-size:12px;">import java.io.File;
import java.io.IOException;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
public class LucenePrefixQuery {
public static void main(String[] args) {
try {
Directory dir = SimpleFSDirectory.open(new File("E:\\FootBall"));
IndexSearcher indexSearcher=new IndexSearcher(dir);
Term t=new Term("TeamName","阿");
PrefixQuery q=new PrefixQuery(t);
TopDocs topDocs = indexSearcher.search(q, 10);// 10
// 代表取搜索结果评分最高的前10个,至于怎么评分的,我没搞清楚
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
int totalLength = topDocs.totalHits;
int scoreLength = scoreDocs.length;
System.out.println("Total Hit:" + totalLength);// 满足条件个数
System.out.println("Score Hit:" + scoreLength);// 实际返回个数
System.out.println("******************************");
for (int i = 0; i < scoreLength; i++) {
System.out.println(indexSearcher.doc(scoreDocs[i].doc));
System.out.println(scoreDocs[i].score);
System.out.println("==============================");
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
</span>
其余的什么模糊搜索、短语搜索等等就不介绍了,用法大同小异。
PS:今天所有代码例子在用中文词条进行检索的时候都是用的单个字,那是因为选择的分词器就是一个标准的分词器,不支持中文分词。
有专门的中文分词器,也许下一次就会写到。