HashMap和Hashtable是Map接口的两个实现类,它们对Map接口的方法没有进行扩充。
关于Map接口大家可以参考:
1. HashMap
HashMap是Map接口中出场率很高的一个实现类。
可以存放存放null的key,value值,null值的key存放在第一个桶中。key值不允许重复,如果key值重复,会将原本的key-value对象更新为重复的key-value。元素存放是无序的,而且顺序会不定时改变。
HashMap 是一个采用哈希表实现的键值对集合,继承自 AbstractMap,实现了 Map 接口 。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {HashMap 的特殊存储结构使得在获取指定元素前需要经过哈希运算,得到目标元素在哈希表中的位置,然后再进行少量比较即可得到元素,这使得 HashMap 的查找效率很高(hash表的存在本就是为了以O(n)的时间复杂度查找到元素)。
以元素个数8为边界,当Map中元素数量小于8,底层采用数组和链表组合的形式进行数据存储,如下图所示:

这和前面介绍过的Collection接口中的HashSet底层实现是一样的。将所有元素分成16个桶(JDK默认16个桶,可扩容),然后每个桶上连着一个链表,每次对象数据存入,先通过hashCode进行分桶,然后将它们头插到链表中,这一部分大家可以参考:
另外,由于HashMap扩容时的开销是很大的,需要创建数组,重新哈希,分配,所以要关注以下两个参数:
- 容量:数组的容量
- 加载因子:据定了HashMap中的元素占有多少比例时扩容。
HashMap 的默认加载因子为 0.75,这是在时间、空间两方面均衡考虑下的结果:
加载因子太大的话发生冲突的可能就会大,查找的效率反而变低太小的话频繁 rehash,导致性能降低当设置初始容量时,需要提前考虑 Map 中可能有多少对键值对,设计合理的加载因子,尽可能避免进行扩容。
如果存储的键值对很多,干脆设置个大点的容量,这样可以少扩容几次。
在JDK1.8之后,如果一个桶中存储的元素数量大于8,为了防止这时的单链表过长影响查找效率变为O(n),将会采用红黑树进行存储。这样做的目的是提高HashMap的效率以及防止元素过多时发生hash冲突。当然,这个阈值可以手动进行设置,8这个值是JDK的默认值。
HashMap采用异步处理,效率很高,但是在多线程访问的时候存在线程安全问题,我们可以在其外部进行同步操作,或者使用Collections.synchronizedMap(new HashMap())进行包装得到线程安全的HashMap。
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}通过下面的例子,了解HashMap的基本使用:
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "xucc");
// 添加重复key值元素,会将key所对应的value进行更行
map.put(1, null);
map.put(2, "lixx");
map.put(3, "sunn");
map.put(4, "sunn");
System.out.println(map);
// HashMap其他方法
// 取得map中所有key
Set<Integer> keySet = map.keySet();
Iterator<Integer> iterator = keySet.iterator();
System.out.println("所有的kye:");
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
// 取得map中所有value,values()方法返回一个Collection接口的对象
Collection<String> col = map.values();
Iterator<String> iterator2 = col.iterator();
System.out.println("所有的value:");
while(iterator2.hasNext()) {
System.out.println(iterator2.next());
}
}
}运行结果:

2. Hashtable
Hashtable子类是JDK1.0提供的,而HashMap是JDK1.2提供的,它们的使用方法是一样的。
值得注意的是,Hashtable底层是由数组实现的,而且不能存入null,否则会抛出NullPointerExceptio异常。
基本使用如下:
import java.util.Hashtable;
import java.util.Map;
public class Test {
public static void main(String[] args) {
// HashTable
Map<Integer, String> map = new Hashtable<>();
// Hashtable不能传入null
map.put(1, "xucc");
// 传入重复元素
map.put(1, "zhss");
map.put(2, "licc");
map.put(3, "sunn");
System.out.println(map);
}
}运行结果:

Hashtable底层的方法都是synchronized同步方法,线程安全,但是也就导致了效率特别低,而且在实现上没有HashMap高级,所以现在基本都被HashMap替代了。
Hashtable虽然出场很少,但是它有一个很重要的子类:Propertise系统文件属性类,在之后的会对这个类进行单独介绍。
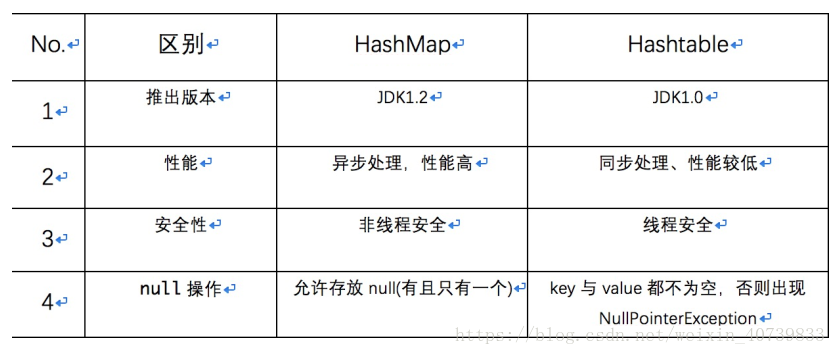
总结:HashMap与Hashtable的区别: