- 实际当中,做一个具体场景的计算机视觉任务时,为了避免浪费过多的计算时间,往往不是从头开始训练一个网络:而是利用数据、任务或模型之间的相似性,将在旧的领域学习过或训练好的模型,应用于新的领域这样的一个过程。这就是迁移学习。
- 前提:两个任务的输入属于同一性质:要么同是图像、要么同是语音或其他
迁移学习在什么情况下使用?
有两个方面需要我们考虑的
- 当我们有海量的数据资源时,可以不需要迁移学习,机器学习系统很容易从海量数据中学习到一个鲁棒性很强的模型。但通常情况下,我们需要研究的领域可获得的数据极为有限,在少量的训练样本上要求的精度极高,但是实际泛化效果极差,这时需要迁移学习。
- 训练成本,很少去从头开始训练一整个深度卷积网络,从头开始训练一个卷积网络通常需要较长时间且依赖于强大的 GPU 计算资源。
迁移学习的实现方法——微调网络
最常见的称呼叫做fine tuning(微调)。(已训练好的模型,称之为Pre-trained model)
通常我们需要加载已训练好的模型,这些可以是一些机构或者公司在ImageNet等类似比赛上进行训练过的模型。TensorFlow同样也提供了相关模型地址:https://github.com/tensorflow/models/tree/master/research/slim
下图是其中包含的一些模型: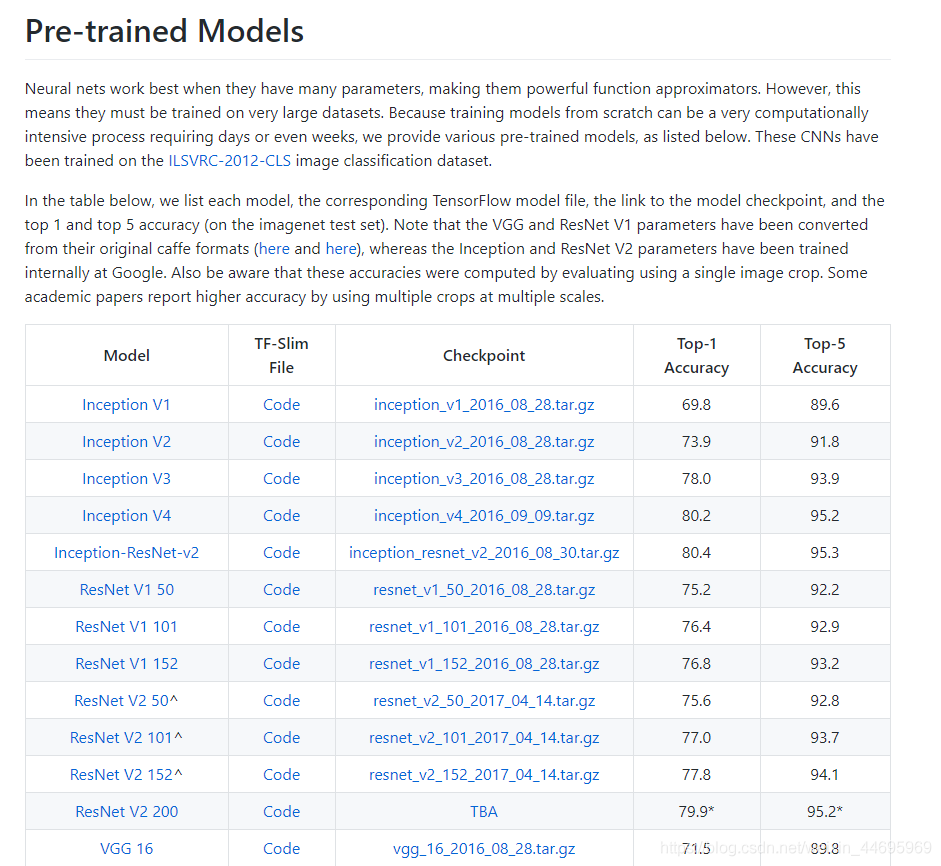
微调网络的过程
这里我们举一个例子,假设有两个任务A和B,任务 A 拥有海量的数据资源且已训练好,但并不是我们的目标任务,任务 B 是我们的目标任务。下面的网络模型假设是已训练好的1000个类别模型
而B任务假设是某个具体场景如250个类别的物体识别,那么该怎么去做:
- 建立自己的网络,在A的基础上,修改最后输出结构,并加载A的模型参数
- 根据数据大小调整
(1)如果B任务的数据量小,那么我们可以选择将A模型的所有的层进行freeze(可以通过Tensorflow的trainable=False参数实现),而剩下的输出层部分可以选择调整参数训练
(2)如果B任务的数据量大,那么我们可以将A中一半或者大部分的层进行freeze,而剩下部分的layer可以进行新任务数据基础上的微调
- 注意事项
(1)由于网络已在原始数据上收敛,因此应设置较小的学习率在新的目标数据上微调,如10-4数量级以下
(2)卷积神经网络浅层拥有更泛化的特征,如边缘、纹理;深层特征则更加抽象,对应高层语义。因此,在新的数据上微调时,泛化的特征更新的可能性或程度较小,高层语义更新的可能性或程度较大,故可根据层深对不同层设置不同学习率:网络的深层的学习率可稍大于浅层学习率
(3)根据目标任务数据与原始数据相似程度,采用不同的微调策略
(4)新的目标数据极少,同时还与原始数据有较大差异时,一种有效的方式:借助部分原始数据与目标数据协同训练。其中部分原始数据是目标数据的近邻,以下这种多目标学习任务的微调策略可大幅改善这种情况,有时可获得2~10个百分点的提升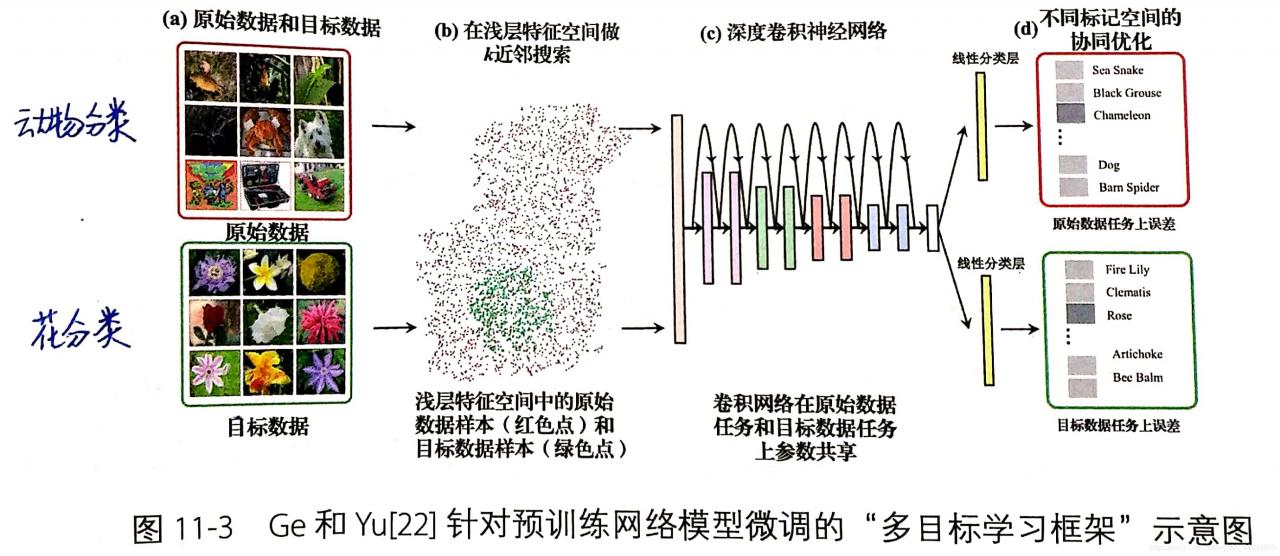
版权声明:本文为weixin_44695969原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。