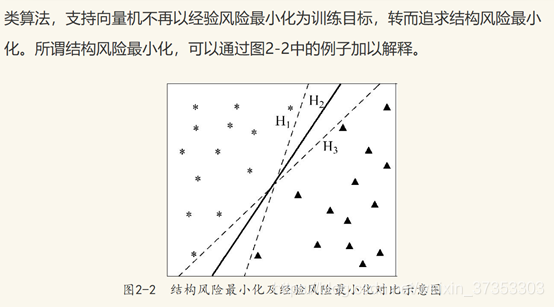
类别不平衡是指在分类任务中不同类别的训练样本数目差别很大的情况,导致分类结果会偏向于大类,影响分类效果。
- 类别不平衡对朴素贝叶斯分类器的影响





- 类别不平衡对SVM的影响

{kind=link}
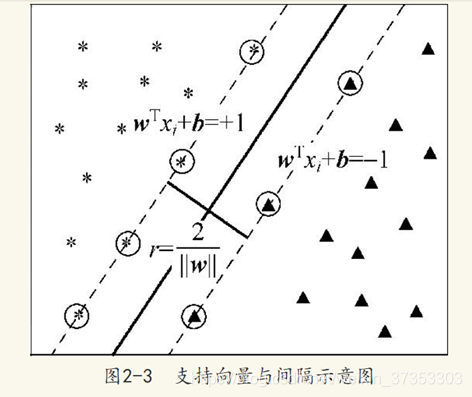





类别不平衡的影响因素:
(1)
类别不平衡比率IR表示为多数类样本数与少数类样本数。一般而言,IR越大,其对分类器的负面影响越大,越容易把少数类误分为多数类。实际上,在很多实际的类别不平衡学习任务中,其类别不平衡的比率均可达到100以上,甚至10000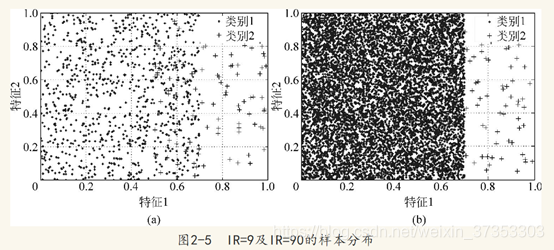
(2)重叠区域的大小
在有些情况下,类别不平衡比率高的也不会对传统分类器的性能产生较大的危害,还需要考虑样本的其他分布因素。其中,不同类样本的重叠区域大小也会对分类性能产生较大影响。所谓的重叠区域是指不同类样本在属性空间的交叠区域。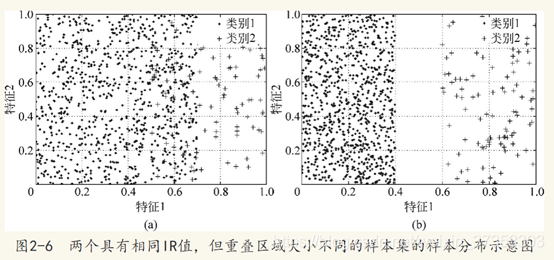
(3)训练样本的绝对数量
即使在类别平衡的任务中,若训练规模过小,也会大幅度降低分类器的训练精度。因为在小样本数据集上,难以通过统计学方法获取样本的真实分布,即使统计得到一个分布特征,距真实分布的偏差也会较大,从而造成最后学习的结果不准确,在类别不平衡样本中,这一因素又会被进一步偏大。在训练样本不足的情况下,少数类样本的分布将更加稀疏,从而只能体现出一定的随机性,而无法从中观察到其真实的分布情况。即在类别不平衡学习任务中,训练样本的绝对数量越少,其学习可能越不充分,所训练的分类面的偏差也可能越大。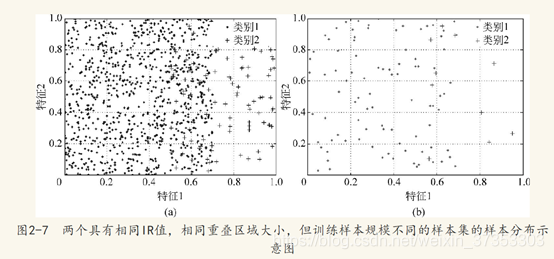
(4)类内子聚集现象的严重程度
类内子聚集,也被称作类内不平衡或小析取项,通常指代少数类样本中出现两个或者多个概念,且概念有主次之分,少数类样本本就受到类间不平衡因素的影响,若再存在类内不平衡现象,而需分类器同时学习多个概念,则必然会加剧分类算法的学习难度,而进一步降低少数类的分类精度。
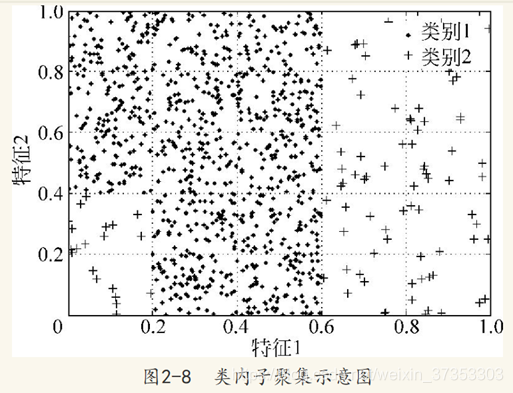
(5)噪声样本的比率
噪声样本主要是指那些不符合同类样本分布的样本,他们在属性空间中通常是以离群点的形式存在,若这些噪声样本恰好出现在了其他类样本的决策区域,则会对其他类样本的决策造成危害。对于不平衡分类而言,若多数类中含有较高比例的噪声样本,则可能会极大地降低对少数类样本判别正确地可能性,而若少数类噪声样本地比例偏高,则往往会湮没在多数类样本之中,不会对后者的性能产生多少负面影响。因此,较高噪声样本比率往往会加大类别不平衡学习的难度。
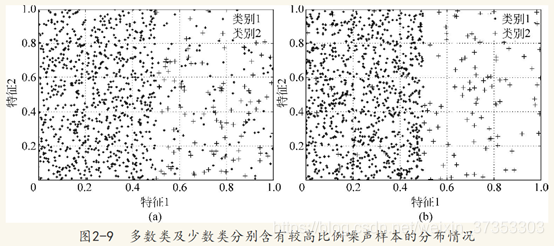
除上述影响因素外,样本的维度(属性个数)也会对类别不平衡学习的性能产生影响。
书目:类别不平衡学习理论与算法
在线阅读:https://wenku.baidu.com/view/f2283160a9956bec0975f46527d3240c8447a1a5.html