目录
前言
略
简介
用途
略
横向对比
| 特点 | rabbitmq | rocketmq | kafka |
|---|---|---|---|
| 开发语言 | erlang | java | java |
| 单机吞吐量 | 万级 | 十万级 | 十万级 |
| topic | - | 千级影响吞吐 | 百级影响吞吐 |
| 功能丰富度 | 高 | 高 | 低 |
部分概念说明
- topic 订阅主题,是消息订阅的基本单位
- tag 消息的标签 用于区分在同一个topic的不同类型的消息
- queue 存储消息的物理实体(kafka里面叫分区partition),一个topic对应多个queue
- 分片 (非官方) 通常指存放同一个topic的broker
- 消息标识(MessageId/key)
- key是业务标识
- 生产者send消息的时候生成一个MessageId (msgId) 其生成规则如下:
producerId + 进程pid + 客户端hashcode + 当前时间 + 自增计数 - broker 接受到消息的时候也会生成一个消息id(offsetMsgId)其规则如下: brokerId+消息在物理分区(queue)的偏移量offset
系统架构
首先看一下来自官网的架构图
主要分为四个部分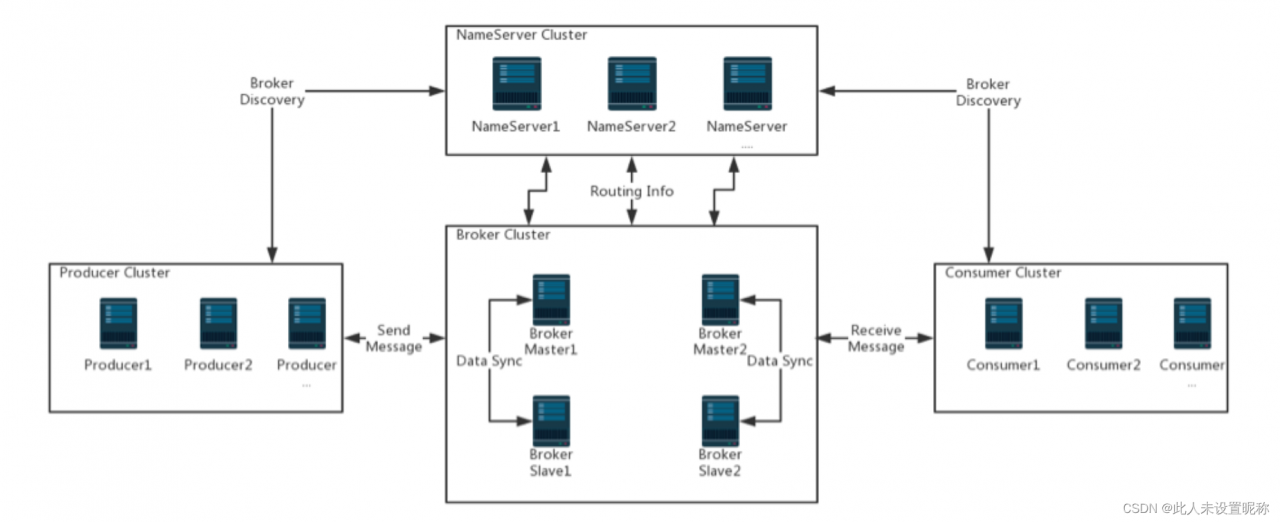
producer
消息生产者,producer通过mq的负载均衡模块选择响应的broker集群进行消息投递,投递的过程支持快速失败和低延时。
rockermq中的生产者都是以生产者组(producer group)的方式出现。生产者组是同一类生产者的集合。这类producer发送相同topic类型的消息。
consumer
消息消费者
消费者也是以组(consumer group)的形式出现,消息在消费者组中消费时是负载均衡的。注意:负载均衡的是queuer而不是真正的消息。
一个queue的消息只能被同一个消费者组的一个消费者消费(注意,可以被不同组的消费者消费)。所以同一个组消费者的数量应该小于一个topic的queue的数量,否则会有消费者得不到消息。
NameServer
NameServer是broker与topic的路由与注册中心,支持broker的动态注册于发现。主要功能有两点:
- broker管理 接受broker集群的注册消息并保存下来作为路由信息的基本数据;提供路由的心跳检测机制,检测broker的存活情况。
- 路由信息管理 每个nameserver都保存着整个broker集群的整个路由信息和用于客户端查询的队列信息,producer 和 consumer 可以通过它获取broker的集群的路由信息,从而进行消息的投递和消费。
路由注册
nameserver通常也是以无状态集群方式部署的,各个节点间不相互通讯。在broker节点启动的时候,轮询nameserver列表,与每个nameserver建立长链接,并发起注册请求。在nameserver内部维护着存储broker信息的列表。
broker节点会每隔30s向nameserver同步心跳。心跳包包含,brokerid broker地址,broker名称,broker所属集群名称等等。nameserver接收到信息后,更新broker信息。
路由剔除
nameserver节点,每10s扫描一次broker信息列表,如果有broker最新心跳时间与当前时间差值超过120s,则认为该broker失效,并将信息从列表中删除。
路由发现
rocketmq采用的pull机制(push方法实际上也是pull),让客户端每隔30s从nameserver中拉取最新的路由信息。
选择策略
客户端首先需要配置nameserver的集群地址。
先设置一个随机连接数,然后与nameserver节点数量取模,得到需要连接的节点,如果连接失败,则会采用round-robin策略,逐个尝试连接其他节点。
broker
负责消息存储转发,同时存储着消息的相关的元信息,如offset,主题,队列。
broker集群是一个主备集群,分为master,slave两种。master节点服务读写操作,slave节点负责备份数据,在master挂掉后,slave节点成为master。master slave的对应关系是通过指定相同的brokername 不同的brokerId 确定的。brokerId为0则表示未master,非0则为slave。
topic创建模式
- 集群模式:该模式下创建topic在该集群中,所有的broker中的queue数量相同
- broker模式:该模式下创建topic在该集群中,每个broker的queue数量可以不同。
自动创建topic时,默认采用的broker模式,会为每个broker创建四个queue
读/写队列
创建topic时可以指定读写的队列数,从物理逻辑上讲,读写队列都是相同的。举例如下:
一,创建4个读队列,8个写队列0到8,则编号4,5,6,7的队列中的消息不会被消费。
二,创建4个写队列,8个读队列0到8,则编号4,5,6,7的队列中不会有任何消息可以被消费。
该设计的目的是为了方便queue的变容,如:queue由16个降了8,通过这种机制,可以保证消息不会丢失。
集群
主备复制
异步复制: 消息写入master后,立即向producer返回ack
同步复制: 消息写入master后,master同步消息给slave,收到slave的返回后向producer返回ack
刷盘策略
同步刷盘: 消息写入到master才算写入成功
异步刷盘: 消息写入到master的内存就算成功
RAID10
一种安全性非常高的存储设备(磁盘阵列)
原理
queue选择算法
- 轮询算法: 默认的选择算法
- 最小投递延时算法:计算每次投递的时间,选择延时最小的queue投递,如果时间相同,则采用轮询方法。
commitlog
commitlog目录是存储消息的文件目录,一个broker仅包含一个commitlog目录
里面是存储具体消息的mappedfile文件。文件的名字以第一条消息的偏移量(20位十进制数)命名,大小1G。broker将接收到的消息顺序的写入到mappedfile文件中。消息存储的格式如下: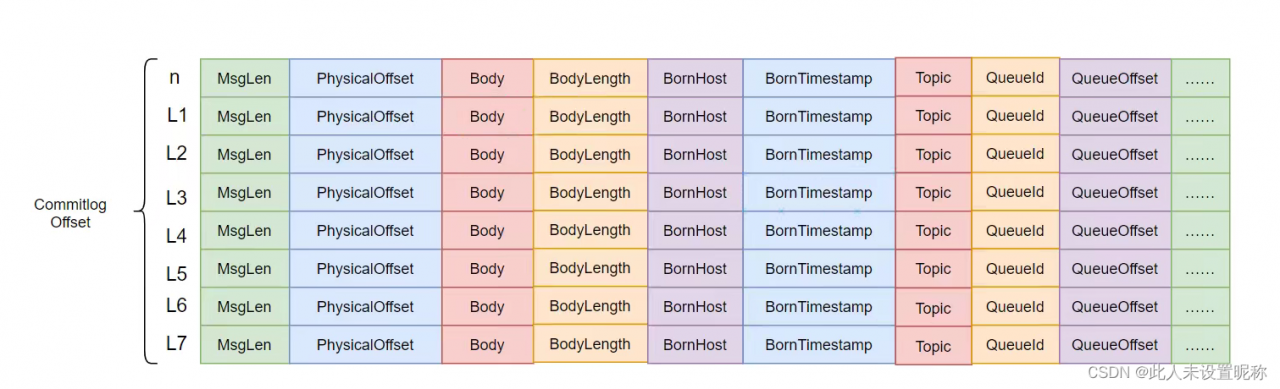
consumequeue
consumequeue目录下存放的是topic的queue文件,目录如下:
consumequeue/[topic name]/[queue id 即 consumequeue文件]
consumequeue文件也是由20位数字构成的,表示当前文件第一个索引的偏移量,后续consumequeue文件名是一样的,因为索引的大小是固定的。
一个消息被生产者发送过来时,其首先存储到commitlog中,然后将消息在commitlog中的索引存储到consumequeue目录下的对应主题的对应的consumequeue文件中,其索引共20个字节,每个文件可以包含30w个索引条目,文件大小为30w*20字节,索引格式如下:
|—8—|—4—|----8—|
|—commitlog offset—|—size—|—message tag hashcode—|
消息写入过程
- broker根据queueId,获取该消息对应的consumequeue文件的偏移量queueoffset。
- 将queueId queueoffset等数据封装成一个消息单元
- 将消息写入到commitlog文件中,并得到索引
- 将索引写入到consumequeue文件中
消息消费过程
- consomer首先获取自己消费的queue的
消费偏移量,然后计算出要消费消息的消息offset- 消费偏移量:消费进度,即消费到该queue的第几条消息。broker会将这个偏移量的信息存储到config目录下的consumerconfig文件中。并按照
"[topic name]@[consumer group]":{[queue id]:[consom msg count].... 如:0:8,1:7,2:7,3:8}格式记录。 - 消息offset:= 消费偏移量 + 1
- 消费偏移量:消费进度,即消费到该queue的第几条消息。broker会将这个偏移量的信息存储到config目录下的consumerconfig文件中。并按照
- consumer向broker发起请求,请求包含,queueid,offset,tag
- broker计算consumqueue文件中的offset,并从此位置向后查找到第一个复合tag的索引
- 根据索引的前八位,从commitlog中读取数据,并发送给consumer
性能优化
- rockermq对文件的读写都是通过mmap进行的,比一般读写少一次拷贝,大大加速了读写性能,但是mmap会带来内存问题,大文件存储问题。
- consumqueue中的数据是顺序存放的,并且采用了pagecache预读取机制,对文件的读取性能接近内存。有消息堆积也不影响性能。
indexfile
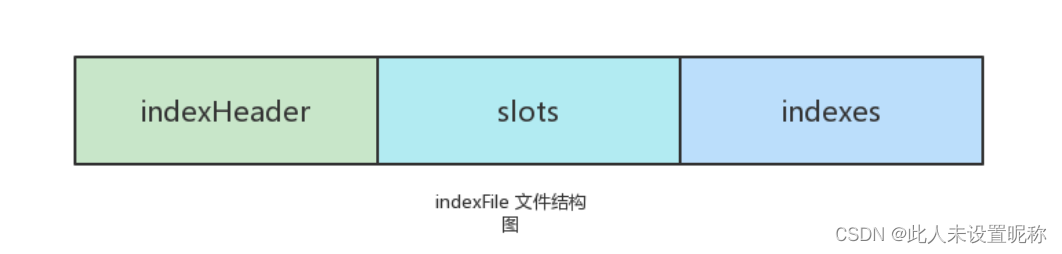
除了通过指定Topic进行消息消费外,RocketMQ还提供了根据Key进行消息查询的功能。该查询通过store/index/infdexFile进行索引实现的快速查询。这个indexFile中的索引数据是包含Key的消息被发送到Broker时写入的。如果消息中没有Key,不会被写入。
- 每个Broker包含一组indexFile,每个indexFile都是以该indexFile被创建时的时间戳进行命名的。
- 每个indexFile由三部分组成:indexHeader(索引头),Slots(槽位),indexes(索引数据)。
- 每个indexFile包含500万个slot,每个slot有可能会挂载很多index索引单元
消息的消费
推拉方式
- 方式一:pull
- 方式二:push
分配方式
- 广播消费:每个consumer group中的每个consumer都收到topic的全量消息,消费进度由consumer记录
- 集群消费:一个consumer group中的consumer会负载均衡的接受消息,消费进度由broker记录
rebalance
即重均衡,当一个topic的消费者数量小于queue时,如果消费者数量有变化,怎讲queue与消费者的关系重平衡。
原因
为了提高消息的并发消费能力。
危害
- 消费暂停:在只有一个consomer时,如果新增一个consomer,基于rebalance机制,会暂停一些queue的消费,直到新的consomer开始消费这些queue。
- 消费重复:在默认的情况下,消息的offset提交是异步的。所以发生rebalance时,会导致新的消费者看到的消息的offset和实际不一致。这个差值会导致重复消费。
- 消费突刺:因为消费暂停,或者重复消费的问题,新的消费者在开始消费消息时,可能会突然收到大量待消费的消息。
queue分配算法
假设有10的queue 0…10,四个消费者A,B,C,D
- 平均分配策略 A(0,1,2) B(3,4,5) C(6,7) D(8,9)
- 环形平均策略 A(0,4,8) B(1,5,9) C(2,6) D(3,7)
- 一致性hash策略: 将consumer的hash值和queue的hash值放入到hash环中,按顺时针方向,将距离queue放入距离其最近的consumer中。
- 同机房策略: 将queue放入与其同机房的consumer中,如果没有同机房的queue,则进行平均分配或环形分配。
至少一次原则
每个消息必须被成功消费一次
重试队列
当rockermq对消息的消费出现异常时,会将发生异常的消息的offset放入到broker的重试队列中。系统会为该topic创建一个重试队列topic@group,该队列以%RETRY%,达到重试时间后开始重试。
offset的提交
在集群消费模式下,consumer消费一批消息后,会提交这个消息的offset给broker,broker记录这些内容,并向consumer返回一个ACK,内容是当前消费队列的最小minOffset,最大MaxOffset,下次消费的起始位置nextBeginOffset。
offset有两种提交方式:
- 同步提交:consumer在消费完一批消息时,提交这些消息的offset,如果成功,则继续消费下一批,如果提交失败,则不断重试。
- 异步提交:consumer在消费完一批消息后,异步提交消息offset,无需等待broker响应,同时立刻开始消费下一批消息。此时,nextBeginOffset需要从broker中获取。
消费幂等
一般来说,消费者对消息的处理应该是幂等的。即消费同一个消息得到的结果相同,并且不会对系统或业务产生不良影响。如果不具备幂等性,则无法保证系统或业务的可用于稳定。
消息不幂等的原因
- 发送的消息重复
- 消费时消息重复
- rebalance时消息重复
通用解决方案
两要素:
- 幂等令牌:生产者和消费者约定的业务或消息的唯一标识
- 唯一性处理:消费者采用一定的算法或策略,保证同一个业务逻辑不会被多次执行。
方案:
- 缓存方案:先进行缓存判断,在缓存中已存在幂等令牌,则说明操作重复,否则进行下一步操作。
- 数据库方案:在唯一性处理之前,先在实体存储中确认幂等令牌是否被使用,若被使用则说明操作重复,反之进行下一步操作。
实际的场景中可以这样解决幂等问题,通常在一个事务中完成这些操作:接收到一个消息后,对幂等令牌进行锁占用,然后判断是否操作重复,重复则返回,反之进行业务处理,完成后,标记幂等令牌已被消费,解除锁占用。
应用
消息发送的方式
- 同步发送
- 异步发送
- 单向发送:producer仅负责消息的发送,不关心发送结果,mq也不会返回ack
顺序消息
在一个queue中的消息通常是顺序消费的。
全局有序:原理是只有一个queue,可以再创建topic时指定queue数量为1
分区有序:一个topic有多个queue,则每个queue的消息是有序的。通常在发送消息时用取模算法指定queue。
延迟消息
发送消息时,可以设置延迟等级,以便一段时间后再处理这个消息。时间间隔和对应等级依次如下:
1s、 5s、 10s、 30s、 1m、 2m、 3m、 4m、 5m、 6m、 7m、 8m、 9m、 10m、 20m、 30m、 1h、 2h;
如果需要自定义时间,需要在broker的conf目录下的配置文件中增加。
延迟队列原理
broker在收到一条消息后,先判断是否设置延时,如果没有,则进行正常操作,否则需要进行如下操作:
- 变更消息的topic为SCHEDULE_TOPIC_XXXX,根据延时等级,在consumequeue目下创建SCHEDULE_TOPIC_XXXX主题下创建出相应的queueid目录和consumequeue文件(如果这些目录和文件没有的话)。所以并不是所有的延时queue都会被创建,只有在用到这个时间等级的时候才会被创建,另外
该延时主题的queue id = 延时等级 - 1 - 修改该消息索引的后八位
tag hash code为该消息的投递时间,投递时间 = 消息发送到broker的时间 + 延时等级对应的时间,将索引添加到对应的consumequeue文件中 - broker内部有一个延时消息服务类。该类会定期消费SCHEDULE_TOPIC_XXXX主题中的消息,并将消息的延时等级设置为0,即一个普通消息,然后重新投递。
- 此时broker收到一条普通信息,进行正常操作。
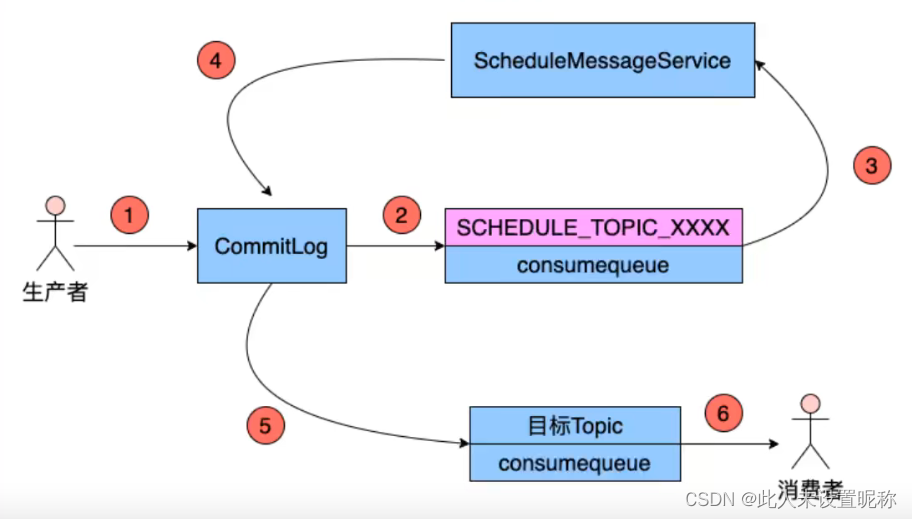
其中 SCHEDULE_TOPIC_XXXX 会按照延迟等级分成若干个consumequeue,所以时间间隔是固定的,而不能随意指定。
事务消息
rocketmq提供了类似于X/Open XA的分布式事务功能。
半事务消息
暂不能投递的消息,发送方已经成功将消息发送到了broker,但broker未收到最终确认指令,此时该消息被标记为"暂不能投递"状态,即不能给消费者看到,处在该状态下的消息为半事务消息。
XA
参考另一篇博文:https://blog.csdn.net/qq_25490573/article/details/123730796?spm=1001.2014.3001.5502
批量发送消息
限制
- 批量发送的消息必须具有相同的topic
- 批量发送的消息必须具有相同的刷盘策略
- 批量发送的消息不能是延时消息或事务消息
大小
默认情况下,一次批量发送的消息总大小不能超过4mb,如果超出,则有两种解决方案:
- 方案一:将信息拆分成若干小于等于4mb的多批次消息,然后逐批发送
- 方案二:producer和broker上修改最大限制
- producer端发送前修改maxMessageSize
- broker修改配置文件中的maxMessageSize
批量接收消息
默认情况下,consumer每次只会接收到一条消息,如果需要批量接收消息,需要设置consumer的consumeMessageBatchMaxSize属性,不过这个值不能超过32。因为默认情况下每次拉取消息最大为32,若一定要超过这个值,可以修改Consumer的pullBatchSize属性。
批量消费不是越大越好:
- 设置pullBatchSize越大拉取的时间就越长,且传输出问题的可能性就越高,影响范围也越大。
- consumeMessageBatchMaxSize 设置越大,并发消费能力越低。如果这批消息里面有一个消息消费异常,整批都要重新消费。
消息过滤
在消费消息时,出来可以指定topic外,还可以通过指定tag或者写sql来进行过滤。
1. tag过滤
在订阅topic时指定tag,如果有多个tag需要指定,则使用||分割开。
2. sql过滤
sql过滤能够实现更复杂的过滤。是通过特殊表达式对事先埋入消息中的用户属性进行筛选来实现的。所以只能在push模式下使用。
默认情况下,该功能是未开启的,需要在broker的配置中设置enablePropertyFilter 为true
支持的常量数据:数值,字符串,布尔(TRUE FALSE),NULL
支持的运算符有:
- 数值比较: > >= < <= BETWEEN =
- 字符比较:= <> IN
- 逻辑运算:AND OR NOT
- NULL判断:IS NULL 或者 IS NOT NULL
消息重发机制
producer对于发送失败的消息会重新发送,即消息冲投。需要注意一下几点:
- 生产者同步或者异步发送消息失败时,会重试。但oneway(单向)消息发送失败没有重试机制。
- 普通消息发送失败会重试,顺序消息是不会重试的。
- 重试机制会保证消息尽可能发送成功,但会带来消息重复的问题,该问题在rockermq中无法避免。
- 消息重复一般不会发生,在网络质量较差,消息量大,消息重复会成为大概率事件。
- 消息发送重试有三种策略可以选择如下:
同步发送失败策略
消息默认采用轮询策略给到队列,如果发送失败,默认重试两次,但重试时不会选择失败过得broker。
同时,rockermq具有失败隔离功能,producer会尽力向未发送失败过得broker上发送消息。
超过重试次数会抛出异常
异步发送失败策略
异步发送失败重试时,不会选择其他broker,仅在同一个broker上进行重试,所以该策略无法保证消息不丢。
消息刷盘失败策略
消息刷盘超时或者不可用(返回状态非SEND_OK)时,默认是不会将消息发送给其他broker的。不过对于重要消息,可以通过设置broker配置文件中的retryAnotherBrokerWhenNotStoreOk属性为true来开启。
消息消费的重试机制
消息重试机制是通过延时消息机制实现的。
1. 顺序消息的消费重试
对于顺序消息,消费失败后会不断重试,直到成功,后面的消息会被阻塞
2. 无序消息的消费重试
(普通消息,延时消息,事务消息)可以通过设置返回状态来达到重试的效果,且只在集群消费模式下生效,广播模式下不提供重试功能。
3. 消费重试次数与间隔
- 每条消息默认最多重试16次
- 每次间隔会逐渐变长,
- 可以在consumer设置重试次数,小于16次,则按照原时间间隔发送,超过16次则多出来的次数,间隔2h。一个consumer设置,则整个消费者组生效。
- 超过最大次数仍旧失败,则消息进入死信队列。
4. 重试队列
当rockermq对消息的消费出现异常时,会将发生异常的消息的offset放入到broker的重试队列中。系统会为该topic创建一个重试队列topic@group,该队列以%RETRY%,达到重试时间后开始重试。
5. 消息重试配置
集群模式下,消费失败后,如果需要进行消息消费重试,需要明确返回内容,如下三种 - 返回状态为
RECONSUME_LATER - 返回NULL
- 抛出异常
6. 消息不重试配置
如果消费失败,不需要重试则返回CONSUME_SUCCESS状态
死信队列
当消息消费超过重试次数时,会进入死信队列,并且消费者不会再消费死信队列中的内容。其是一个特殊的topic:%DLQ%consumerGroup@consumerGroup 在未产生死信消息时,不会为topic创建死信队列。
未完待续。。。。。