学习手册:https://coggle.club/learn/dcic2020/task-prepare
赛事详情:https://data.xm.gov.cn/opendata-competition/index.html#/contest_explain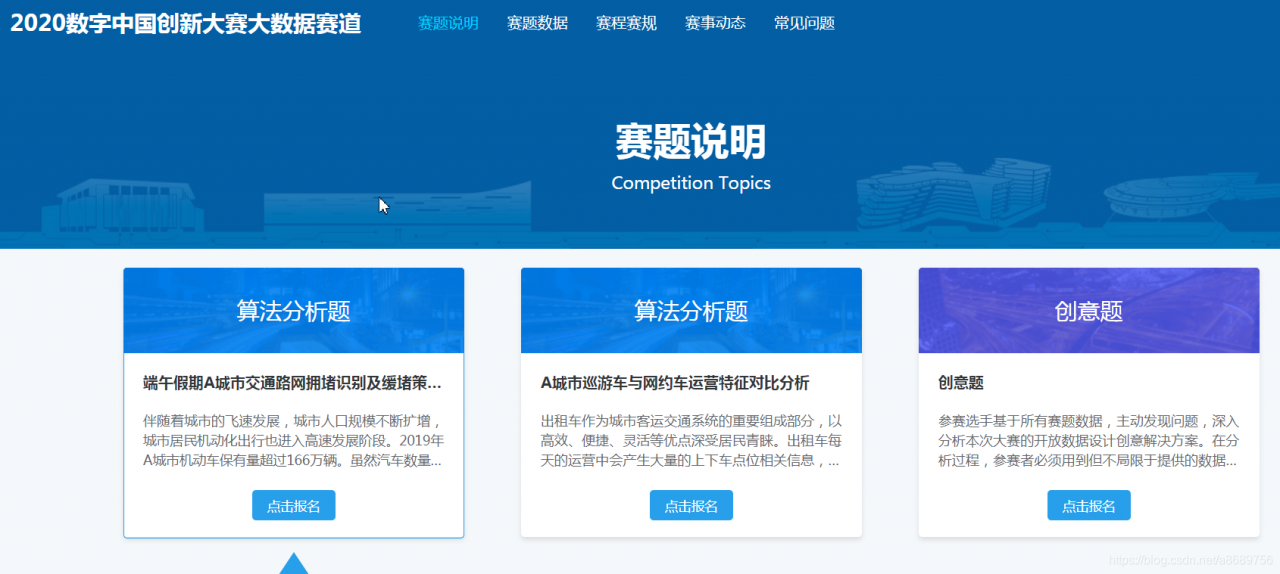
共有三个部分的竞赛
1)端午假期A城市交通网络拥堵识别及缓堵策略研究
需要具有从经纬度映射到路段的能力
2)A城市巡游车与网约车与运营特征对比分析
主要是对出租车和网约车的分布之类的对比,相对于第一个赛题难度稍小
3)创意题
学习内容介绍


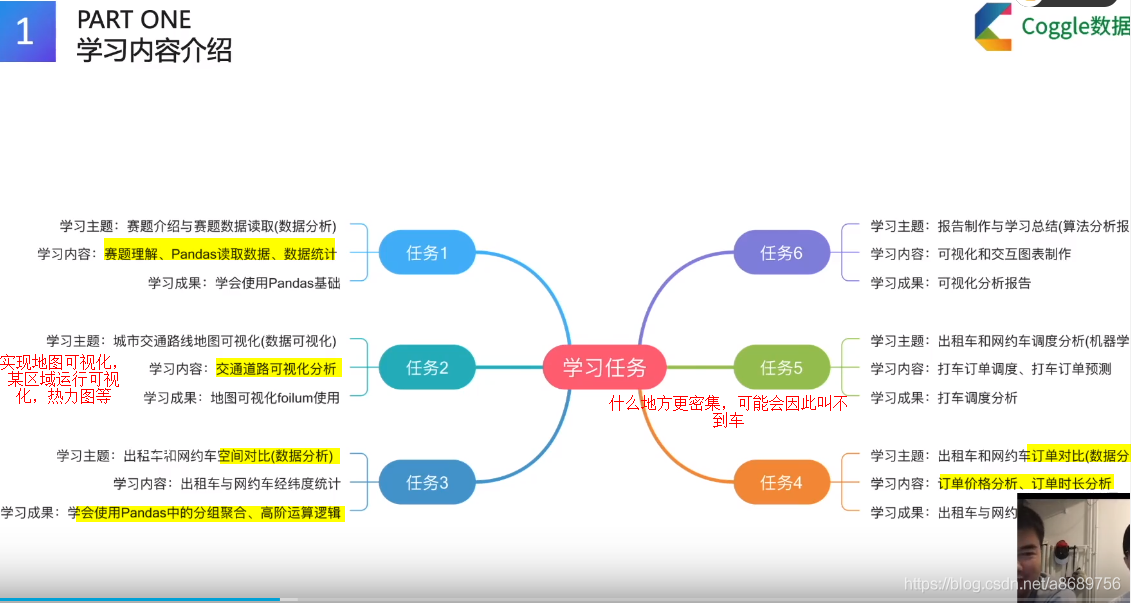
DCIC赛题介绍


【城市巡游车与网约车运营特征对比分析】
【赛题说明】
出租车作为城市客运交通系统的重要组成部分,以高效、便捷、灵活等优点深受居民青睐。出租车每天的运营中会产生大量的上下车点位相关信息,对这些数据进行科学合理的关联和挖掘,对比在工作日以及休息日、节假日的出租车数据的空间分布及其动态变化,对出租车候车泊位、管理调度和居民通勤特征的研究具有重要意义。
【赛题任务】
参赛者需依据赛事方提供的出租车(包括巡游车和网约车)GPS和订单数据,
- 一是综合应用统计分析方法分别对所提供的巡游车和网约车运营的时间、空间分布特征进行量化计算,包括
- 计算2年的每年工作日取日平均,非工作日取日平均和节假日取日平均
- 三种类型各自平均的时变分布变化
- 三种时间类型按网格划分的平均空间分布(网格划分颗粒度选手自选)
- 并分别对比分析所提供的网约车、巡游车,计算2年每年按工作日取日平均,非工作日取日平均和节假日取日平均三种类型的日均空驶率、订单平均运距、订单平均运行时长、上下客点分布密度等时变特性
- 二是根据巡游车和网约车的时空运营特征,并尝试对巡游车与网约车的融合发展提出相关建议。在分析过程,参赛者必须用到但不局限于提供的数据,可自行加入自有数据进行参赛,但需说明自带数据来源并保证数据合法合规使用。
数据分析准备工作
数据分析介绍

数据分析软件
在下面数据分析软件中,R、SAS、SPSS和Stata在数学领域使用的较多,SQL和Pyhton在计算机领域使用的较多。在互联网企业SQL和Python是最为常见的数据处理和分析软件。
由于本次赛题的数据字段众多,有经纬度、日期和订单等复杂类型,因此比较建议使用Python软件进行分析,实现起来比较快速。当然如果想使用R或者SQL来做数据处理也是可以的,但可能会更加费事一些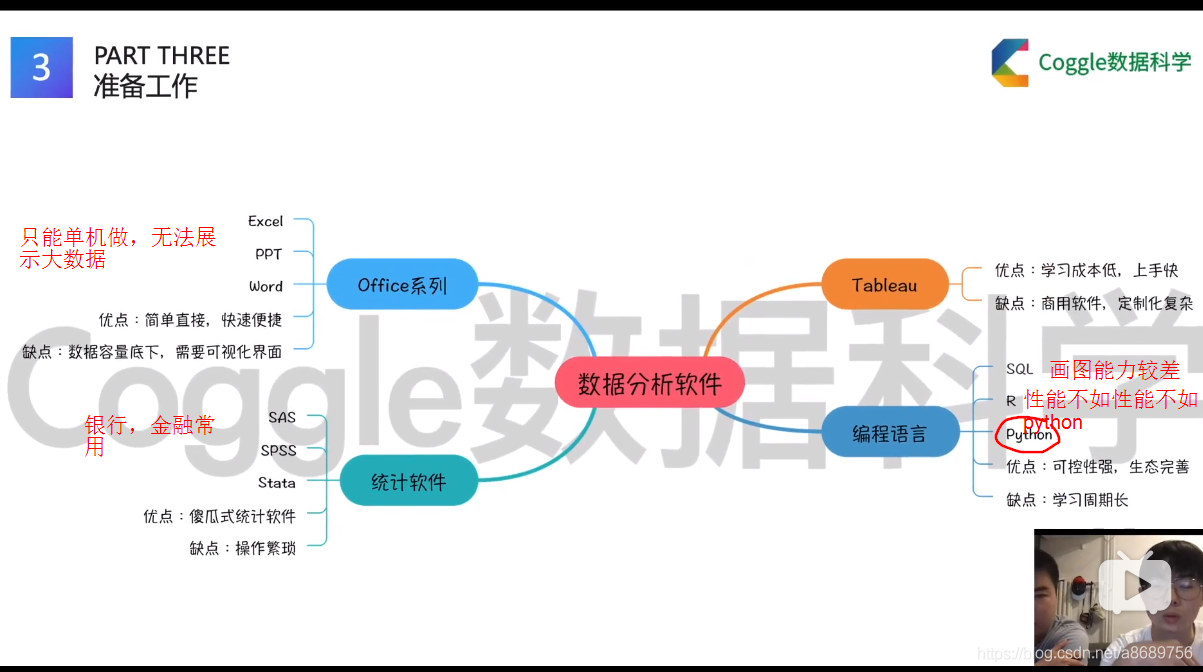
数据分析与数据类型
我们日常生活中充满了各类数据,也有多种数据类型划分方法:
- 定性数据与定量数据;
- 数据类型划分:可将统计数据分为布尔型、类别型、数值型和日期型数据;
不同类型的数据会有不同的数据存储方法和统计方法,也需要不同类型的可视化方法来完成。
数据分析与可视化方法
数据可视化方法有非常多种,具体可以根据数据类型、对比方法和展示方法进行细分:
- 各种图形介绍:https://datavizcatalogue.com/ZH/index.html
- 基于python的可视化代码:https://python-graph-gallery.com/
数据分析流程
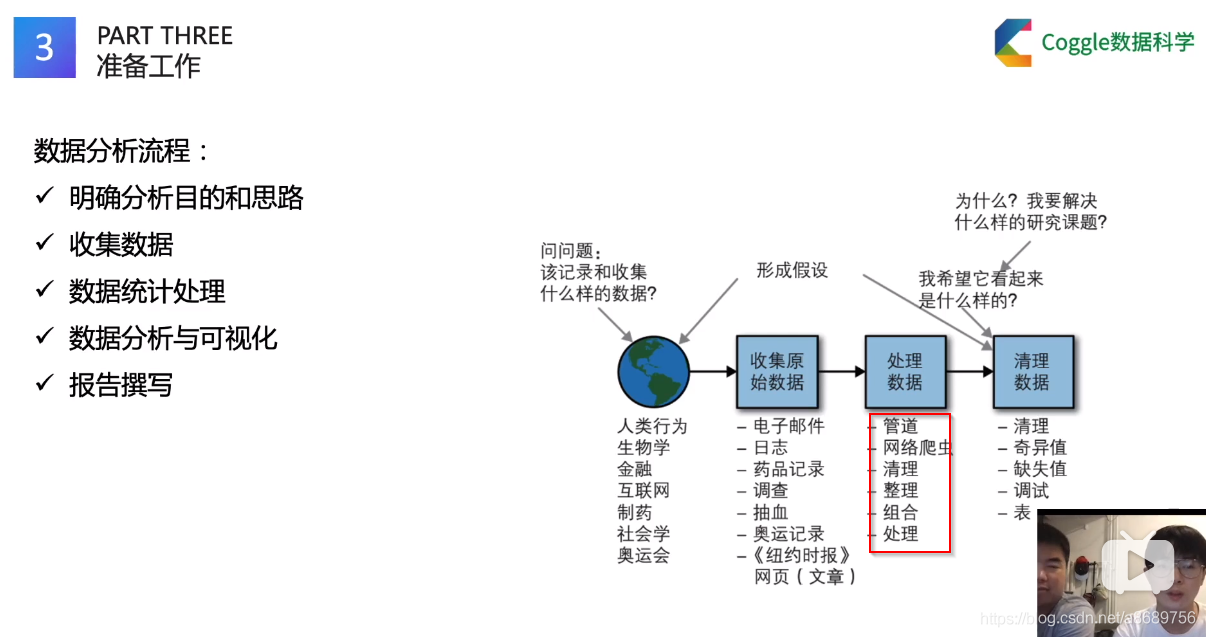
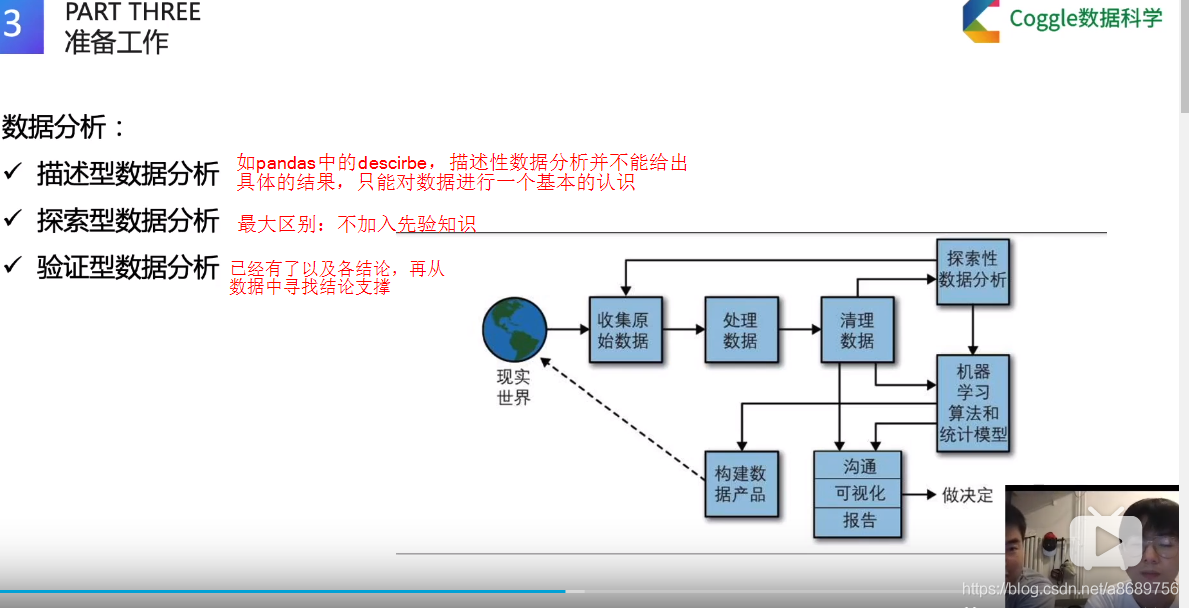
(1)描述性数据分析
描述性数据分析(Descriptive Data Analysis,DDA)属于比较初级的数据分析,常见的分析方法包括对比分析法、平均分析法、交叉分析法等。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。
- 集中趋势的描述性统计量
- 均值:是指一组数据的算术平均数,描述一组数据的平均水平,是
集中趋势中波动最小、最可靠的指标,但是均值容易受到极端值(极小值或极大值)的影响。 - 中位数:是指当一组数据按照顺序排列后,位于中间位置的数,
不受极端值的影响,对于定序型变量,中位数是最适合的表征集中趋势的指标。 - 众数:是指一组数据中出现次数最多的观测值,
不受极端值的影响,常用于描述定性数据的集中趋势。
- 均值:是指一组数据的算术平均数,描述一组数据的平均水平,是
- 离散程度的描述性统计量
- 最大值和最小值:是一组数据中的最大观测值和最小观测值
- 极差:又称全距,是一组数据中的最大观测值和最小观测值之差,记作R,一般情况下,
极差越大,离散程度越大,其值容易受到极端值的影响。 - 方差和标准差:是
描述一组数据离散程度的最常用、最适用的指标,值越大,表明数据的离散程度越大。
- 分布形态的描述性统计量
- 偏度:用来评估一组数据的分布呈先的对称程度,当偏度=0时,分布是对称的;当偏度>0时,分布呈正偏态;当偏度<0时,分布呈负偏态。
(2)探索型数据分析
探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
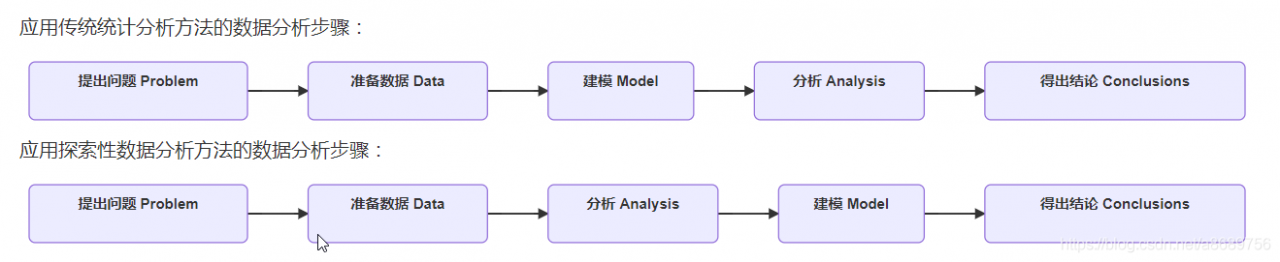
探索性数据分析(EDA)与传统统计分析(Classical Analysis)的区别:
传统的统计分析方法通常是先假设样本服从某种分布,然后把数据套入假设模型再做分析。但由于多数数据并不能满足假设的分布,因此,传统统计分析结果常常不能让人满意。
探索性数据分析方法注重数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。“探索性”是指分析者对待解问题的理解会随着研究的深入不断变化。
(3)验证型数据分析
验证型数据分析(Confirmatory Data Analysis, CDA)根据数据样本所提供的证据,肯定还是否定有关总体的声明。
假设验证的基本流程:
提出零假设(我们希望推翻的结论),及备择假设(我们希望证明的结论)
在零假设的前提下,推断目前样本统计量出现的概率 *统计量可符合不同分布,即对应不同的检验方法
设定一个拒绝零假设的阈值(常见5%,及统计学意义“显著”,significant),如果目前样本统计量在零假设下出现的概率小于阈值,则拒绝零假设,承认备择假设。
数据分析路线
- Python基础:语法、网络编程基础、爬虫;
- Pandas、Numpy等数据处理软件;
- Matplotlib、Searborn和foilum等数据可视化软件;