在这里不想去介绍,什么是卷积?什么是池化?
本文关注以下四个问题:
- 卷积层的作用?
- 池化层的作用?
- 卷积层的卷积核的大小选取?
- 池化层的参数设定?
引出的另外两个问题:
- 全链接层的作用?
- 1*1的卷积核的作用?
- 卷积神经网络为什么效果这么好?
卷积层的作用?
总结如下:
- 提取图像的特征,并且卷积核的权重是可以学习的,由此可以猜测,在高层神经网络中,卷积操作能突破传统滤波器的限制,根据目标函数提取出想要的特征
2.
“局部感知,参数共享”的特点大大降低了网络参数,保证了网络的稀疏性,防止过拟合
之所以可以“参数共享”,是因为样本存在局部相关的特性。
池化层的作用?
对于这个问题,魏秀参博士在CNN_book一书中做了很好的解答,现引用如下:
1. 特征不变性(feature invariant)
汇合操作使模型更关注是否存在某些特征而不是特征具体的位置
可看作是一种很强的先验,使特征学习包含某种程度自由度,能容忍一些特征微小的位移
2. 特征降维
由于汇合操作的降采样作用,汇合结果中的一个元素对应于原输入数据的一个子区域(sub-region),因此汇合相当于在空间范围内做了维度约减(spatially dimension reduction),从而使模型可以抽取更广范围的特征
同时减小了下一层输入大小,进而减小计算量和参数个数
3. 在一定程度上能防止过拟合的发生
卷积层的卷积核的大小的选取?
首先放结论,实践中推荐使用
产生这种结论的原因是:卷积神经网络的感受野机制,引用一段话
卷积核大小为3×3,步长为1的卷积操作,同单层卷积操作一样,相邻两层中后层神经元在前层的感受野仅为3 × 3,但随着卷积操作的叠加,第L + 3 层的神经元在第L 层的感受野可扩增至7 × 7。
// 关于感受野这个东西我知道这里写的很不清楚,所以在更新二中又写了一些,希望能更详细一点
小卷积核相对于大卷积核的优势:
- 增强网络容量和模型复杂度
- 减少卷积参数个数
具体解释如下:
第一,由于小卷积核需多层叠加,加深了网络深度进而增强了网络容量(model capacity)和复杂度(model complexity)
第二,增强网络容量的同时减少了参数个数
若假设上述示例中卷积核对应的输入输出特征张量的深度均为
而三层
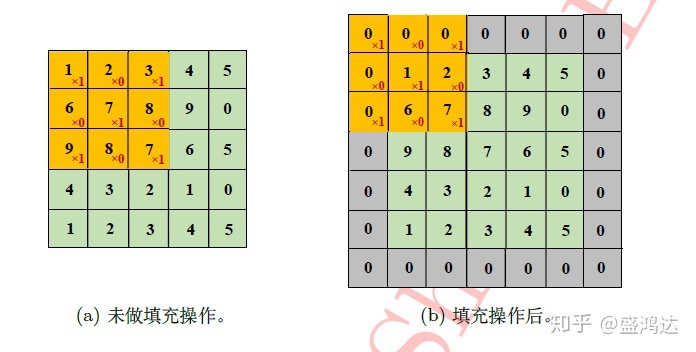
另外在卷积层中通常会用到填充操作(padding),0填充,1填充都是比较常见的手段
该操作有两层功效:
- 可充分利用和处理输入图像(或输入数据)的边缘信息(如下图所示)
- 搭配合适的卷积层参数可保持输出与输入同等大小,而避免随着网络深度增加,输入大小的急剧减小
加一个公式
对公式的简单说明:
无论经过卷积层还是池化层后的特征图都可以用这个公式,区别是:
卷积层之后的话,是向下取整
池化层之后的话,是向上取整
给出一个典型例题(阿里19秋招算法真题):
帐号登录blog.csdn.net池化层的参数设定?
与卷积层的参数设定规则相同,常用的参数设定为
全链接层的作用?
对于这个问题,魏秀参博士也在一个回答中给了详细的解释
全连接层的作用是什么?www.zhihu.com
魏博士的这个回答需要细细研读的
给自己总结下:
- 全链接层相当于一个分类器
如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到 将学到的“分布式特征表示”映射到样本标记空间的作用。
2.
目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。
3.
特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处。)
关于此问题众说纷纭,我尝试回答下:
我认为以下两点:
- 降维或者升维,也可以当成“实现跨通道的交互和信息整合”
- 以较少的参数的代价加深加宽了深度学习网络的层数,加入了更多的非线性信息
在此引用一个知乎文章,以计算的方式说明,1*1的卷积核在降维方面的作用,也能更好地理解跨通道的信息整合的含义
Michael Yuan:CNN中卷积层的计算细节zhuanlan.zhihu.com
卷积神经网络为什么如此有效?
本专栏中最高规格的引用~~~
Yann LeCun在IJCAI 2018上的演讲
那么为什么卷积神经网络在计算机视觉任务上如此高效?
Yann LeCun 随后就对深度卷积网络的表征方式做了介绍
他表明对于图像数据来说,数据的信息与结构在语义层面上都是组合性的,整体图像的语义是由局部抽象特征组合而成
因此深度网络这种层级表征结构能依次从简单特征组合成复杂的抽象特征,如下我们可以用线段等简单特征组合成简单形状,再进一步组合成图像各部位的特征
还有一点要强调的是,卷积神经网络也是“分布式表示”的
神经网络中的“分布式表示” 指“语义概念”(concept)到神经元(neuron)是一个多对多映射,直观来讲, 即每个语义概念由许多分布在不同神经元中被激活的模式(pattern)表示;而每个神经元又可以参与到许多不同语义概念的表示中去
试着说一下“分布式表示”的表现:
对于同一张图像,以最后一层的输出来说,不同的神经元对于图像的响应部位是不相同的。
而对于不同的图像来说,相同的神经元的响应部位也是不相同的的。
-----------------------------
更新一
半年前写的内容现在看起来真的很肤浅,最近也在学习稍微深入的一些内容
贴一个关于卷积的python实现吧,主要参考链接为:
yizt/numpy_neural_networkgithub.com
代码如下:
import numpy as np
def conv_forward( z, K, b, padding=(1,1), strides=(2,2) ):
'''
mutli channel conv forward
:param z: input matrix, shape is (N, C, H, W), N is batch_size, C is channels
:param K: kernel, shape is (C, D, k1, k2), C is input channel numbers, D is output channel numbers
:param b: bias, shape is (D,)
:param padding: padding
:param strides: strides
:return: the result of conv
'''
padding_z = np.lib.pad( z, ( (0, 0), (0, 0) , ( padding[0], padding[0] ), ( padding[1], padding[1] ) ), 'constant', constant_values=0 )
N, _, height, width = padding_z.shape
C, D, k1, k2 = K.shape
assert (height - k1) % strides[0] == 0
assert (width - k2) % strides[1] == 0
conv_z = np.zeros( (N, D, 1 + (height - k1) // strides[0], 1 + (width - k2) // strides[1]) )
for n in np.arange(N):
for d in np.arange(D):
for h in np.arange(height - k1 + 1)[::strides[0]]:
for w in np.arange(width - k2 + 1)[::strides[1]]:
conv_z[n, d, h // strides[0], w // strides[1]] = np.sum( padding_z[n, :, h: h + k1, w: w + k2] * K[:, d] ) + b[d]
return conv_z
z = np.ones( (1, 1, 5, 5) )
K = np.ones( (1, 1, 3, 3) ) - 0.5
b = np.ones( (1,) )
print conv_forward( z, K, b )
注:本次卷积可以实现,batch_size,channel,以及padding,strides等参数的设置,都是有效的
但是针对于,如果遇到
更新二
半年前,对感受野机制不是很了解,还出来瞎写,后来慢慢看了一些资料,就把心得跟大家分享下
普通卷积以及池化层的某一层感受野计算公式为:
其中:
具体的推导思想请看
蓝荣祎:深度神经网络中的感受野(Receptive Field)zhuanlan.zhihu.com
而更多的关于感受野的叙述以及有效感受野的一点概念请看
mileistone:关于感受野的总结zhuanlan.zhihu.com
这只是最普通的卷积以及池化的计算感受野的方式,在涉及到各种卷积的变形以及有效感受野的时候,上面的方法就不在适用。同时,因为自己在做的检测领域,anchor的一些参数也跟感受野机制息息相关,期待我进一步的学习以及更新。