第一章
信息化浪潮
第一次:1980年前后,个人计算机开始普及,解决了信息处理。(Intel、AMD、IBM等)
第二次:1995年前后,进入互联网时代,解决了信息传输。(雅虎、谷歌、阿里巴巴等)
第三次:2010年前后,大数据、云计算、物联网快速发展,解决了信息爆炸的问题。(亚马逊、阿里云等)
数据存储单位换算
1Byte=8bit
1ZB=1024EB=1024^2PB=1024^3TB=1024*4GB=1024^5MB=1024^6KB=1024^7Byte
大数据计算模式
批处理计算:针对大规模数据的批量处理(MapReduce、Spark等)
流计算:针对流数据的实时计算(Flink、Storm、S4等)
图计算:针对大规模数据结构的处理(Pregel、GraphX等)
查询分析:大规模数据的存储管理和查询分析(Dremel、Hive等)
云计算服务模式
模式:软件即服务(应用层)、平台即服务(平台层)、基础设施即服务(基础设施层)
类型:公有云、私有云、混合云
第二章
Hadoop基本概念
Hadoop是一个开源的、可运行于大规模集群上的分布式计算平台,它实现了MR计算模型和HDFS等功能。
Hadoop简介、HDFS+MR
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,它可以使用户在不了解分布式底层细节的情況下开发分布式程序,充分利用集群的威力进行高速运算和存储。从其定义就可以发现,它解決了两大问题:大数据存储、大数据分析。
Hadoop 的两大核心:HDFS:是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
MapReduce:为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
Hadoop 生态系统,常见的组件
HDFS:是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBase 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。
MapReduce:为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
Hive: 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Pig: 是一个基于 Hadoop 的大规模数据分析平台,它提供的 SQL-LIKE 语言叫作 Pig Latin。该语言的编译器会把类 SQL 的数据分析请求转换为一系列经过优化处理的 Map-Reduce 运算。
Mahout:是ASF旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,可以有效地将 Mahout 扩展到云中。
ZooKeeper: 是一个开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Flume: 是 Cloudera 提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume 提供对数据进行简单处理并写到各种数据接受方(可定制)的能力。
Sqoop:是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(MySQL、post-gresql等)间进行数据的传递,可以将一个关系型数据库中的数据导入 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导入关系型数据库中。
Ambari:是一种基于Web的工具,支持AH集群的安装、部署、配置和管理。Ambari目前支持大多数Hadoop组件。
伪分布式安装的相关操作
伪分布式安装:是指在一台机器上模拟一个小的集群,但是集群中只有一个节点。在采用伪分布式模式时,Hadoop的存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在用一台机器上
执行文件系统初始化:1. $cd /usr/local/hadoop 2.$./bin/hdfs namenode -format
启动HDFS:1.$cd /usr/local/hadoop 2.$./bin/start-dfs.sh
启动成功后输入$jps查看所有的java进程
在HDFS中创建hadoop用户的用户目录:1. $cd /usr/local/hadoop 2.$./bin/hdfs -mkdir -p/user/hanoop
在HDFS的“/user/hadoop"目录下创建input目录,命令如下:$./bin/hdfs -mkdir input
将“/etc/hadoop”中的本地文件传到“/input”文件夹下:$./bin/hdfs dfs -put ./etc/hadoop/*.xml input
接着运行如下命令来执行测试样例程序Grep
在计算完成后,输入命令查看结果:$./bin/hdfs dfs -cat output/*
重新运行程序时,先删除output:$./bin/hdfs dfs -rm -r output
停止运行HDFS:1. $cd /usr/local/hadoop 2.$./sbin/stop-dfs.sh
第三章
HDFS简介
目标
HDFS要实现以下目标:1、兼容廉价的硬件设备;2、流数据读写;3、大数据集;4、简单的文件模型;5、强大的跨平台兼容性;6、不适合低延迟数据访问;7、无法高效存储大量小文件;8、不支持多用户写入及任意修改文件。
简单的文件模型
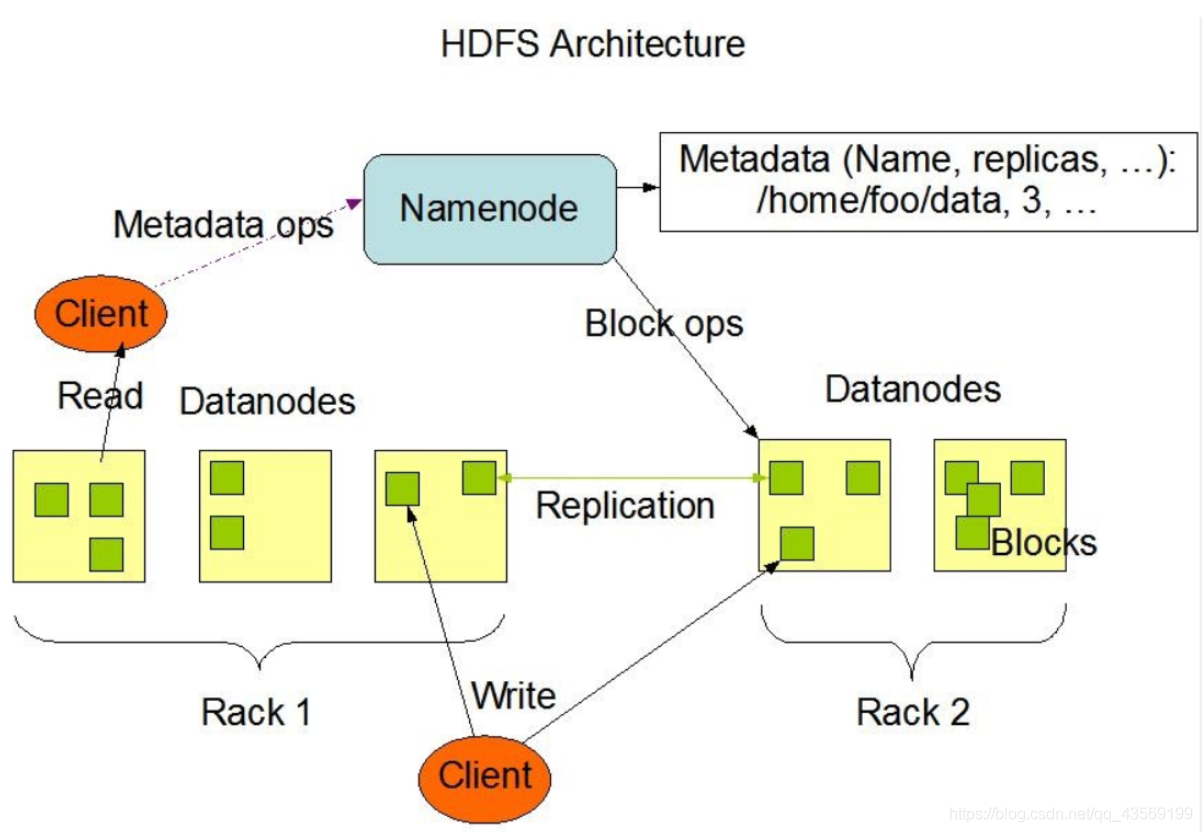 图3-5
图3-5
基础概念
块:HDFS采用了块的概念,默认一个块的大小是64MB。在HDFS中的文件会被拆分成多个块,每个块作为独立的单元进行存储。
HDFS采用抽象的概念块带来的好处:1、支持大规模文件存储;2、简化系统设计;3、适合数据备份。
名称节点:在HDFS中,名称节点负责管理分布式文件系统的命名空间,保存了两个核心的数据结构。FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据,操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作。名称节点记录了每个文件中各个块所在的数据节点的位置信息,但是并不持久化地存储这些信息,而是在系统每次启动时扫描所有数据节点并重构,得到这些信息。
数据节点:是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者名称节点的调度来进行数据的存储和检索,并向名称节点定期发送自己所存储的块的列表信息。
第二名称节点:为了有效解决EditLog逐渐变大带来的问题,HDFS在设计中采用了第二名称节点。功能:1、EditLog与FsImage的合并操作;2、作为名称节点的“检查点”。
MN = PQ M: 数据节点数目 N:每个节点上的Block数目 P: 文件被划分的数据块数目 Q:每个数据块冗余存储的份数
Master/Slave 结构:HDFS采用了主从结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的。
PS:R/W先经过NameNode。当客户端需要访问一个文件时,首先把文件名发送给名称节点,名称节点根据文件名找到对应的数据块,再找到各个数据块的数据节点的位置,并把数据节点位置发送给客户端,客户端直接访问这些数据节点获取数据。
冗余存储:为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上。这种多副本存储方式具有3个优点,1、加快数据传输速度;2、容易检查数据错误;3、保证数据的可靠性。
存储策略:数据存取策略包括数据存放、数据读取和数据复制等方面,它在很大程度上会影响到整个分布式文件系统的读写性能,是分布式文件系统的核心内容。
第四章
HBase简介
Hbase是针对谷歌BigTable的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用存储非结构化和半结构化的松散数据。
列式:Hbase是一个“列式数据库”,采用列式存储模型,目的是最小化无用的I/O。DSM以关系数据库中的属性或列为单位进行存储,关系中多个元组的同一属性值会被存储在一个,而一个元组中不同属性值通常会被分别存放于不同的磁盘页中。
Hbase基于HDFS,BigTable
Hbase和BIgTable的底层技术对应关系
| 项目 | BigTable | HBase |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | ZooKeeper |
数据模型
Hbase实际上就是一个稀疏、多维、持久化存储的映射表,它采用行键、列族、列限定符和时间戳进行索引,每个值都是未经解释的字节数组byte[]。
行键:每个Hbase表都由若干行组成,每个行由行键来标识。
列族:一个Hbase表被分组成许多“列族”的集合,它是基本的访问控制单元。列族可以包含任意多个列。
列限定符:列族里的数据通过列限定符(或列)来定位。
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
数据坐标:Hbase使用坐标来定位表中的数据。Hbase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,即“四维坐标”,["行键",“列族”,“列限定符”,“时间戳”]。
功能组件
库函数:链接到每个客户端。
Master:负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡。
RegionSever:Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求
Ps:1、客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据。
2、客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小。
Hbase的三层结构中各层次的名称和作用:
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息 -ROOT-表只能有一个Region。通过-ROOT-表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息 |
Region Sever工作原理:P80页
Hlog的工作原理:P81页
第五章
web2.0特性
1、Web 2.0网站系统通常不要求严格的数据库事务;
2、Web 2.0并不要求严格的读写实时性;
3、Web 2.0通常不包含大量复杂的SQL查询。
NoSQL四大类型
1、键值数据库:键值数据库会使用一个哈希表,这个表中有一个特定的key和一个指针指向特定的Value。
2、列族数据库:列族数据库一般采用列族数据模型,数据库由多个行构成,每行数据包含多个列族,不同的行可以具有不同数量的列族,属于同一列族的数据就会被存放在一起。
3、文档数据库:在文档数据库中,文档是数据库的最小单位。
4、图数据库:图数据库以图论为基础,一个图是一个数字概念,用来表示一个对象集合,包括顶点以及连接顶点的边。
CAP、BASE的理解
C(一致性)
A(可用性)
P(分区容忍性)

BASE:即Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)。
基本可用:指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现。
软状态:指状态可以有一段时间不同步,具有一定的滞后性。
强一致性:当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据。
弱一致性:如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。
最终一致性:允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,用户必须读到更新后的数据。