使用多层感知机完成MNIST手写字体识别
# -*-coding = utf-8
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 256)
self.l2 = torch.nn.Linear(256, 128)
self.l3 = torch.nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
return self.l3(x)
# because we use cross-entropy as loss
# so we needn't to do softmax and binary entropy
def train(epochs):
running_loss = 0.0
for index, (x, y) in enumerate(train_loader):
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
running_loss = running_loss + loss.item()
print(f"epoch:{epochs}\nloss:{running_loss}")
def test():
correct = 0
tot = 0
# because we don't need to calculate the gradient in test,
# so we use this structure
with torch.no_grad():
for data in test_loader:
image, label = data
output = model(image)
tot += label.size(0)
_, pred = torch.max(output, dim=1)
correct = correct + (label == pred).sum().item()
print(f"Accuracy:{correct / tot * 100}%")
if __name__ == "__main__":
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01, momentum=0.5)
# momentum is a advanced tricky which speak "冲量"
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
# why use these two numbers?
])
train_dataset = datasets.MNIST(root=r"dataset\mnist/",
download=True,
train=True,
transform=transform)
# if the atrribute train is true, the data will be splited into train and test
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root=r"dataset\mnist",
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
for index in range(50):
train(index)
test()
- 神经网络的计算偏爱小数,在喂数据的时候可以进行一些线性变换,转化为( 0 , 1 ) (0,1)(0,1)内的小数。(更不容易过拟合)
- 使用transforms把变换的类型进行封装。
- 使用全连接网络,只能提取一些比较简单的特征,大概在准确率95%左右就会过拟合。
构建简单CNN网络
# -*-coding = utf-8
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# define a graphic card
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 5, (5, 5))
self.conv2 = torch.nn.Conv2d(5, 10, (5, 5))
self.pool = torch.nn.MaxPool2d((2, 2))
self.linear = torch.nn.Linear(160, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pool(self.conv1(x)))
x = F.relu(self.pool(self.conv2(x)))
x = x.view(batch_size, -1)
return self.linear(x)
# because we use cross-entropy as loss
# so we needn't to do softmax and binary entropy
def train(epochs):
running_loss = 0.0
for index, (x, y) in enumerate(train_loader):
# x,y = x.to(device),y.to(device)
# graphic card
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
running_loss = running_loss + loss.item()
print(f"epoch:{epochs}\nloss:{running_loss}")
def test():
correct = 0
tot = 0
# because we don't need to calculate the gradient in test,
# so we use this structure
with torch.no_grad():
for data in test_loader:
image, label = data
# image, label = image.to(device),label.to(device)
output = model(image)
tot += label.size(0)
_, pred = torch.max(output, dim=1)
correct = correct + (label == pred).sum().item()
print(f"Accuracy:{correct / tot * 100}%")
if __name__ == "__main__":
model = Net()
# model.to(device=device)
# if need train on graphic card
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01, momentum=0.5)
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
# why use these two numbers?
])
train_dataset = datasets.MNIST(root=r"dataset\mnist/",
download=True,
train=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root=r"dataset\mnist",
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
for index in range(10):
train(index)
test()
- 事实上只需要修改MyModel对类的定义即可
- 关于显卡上的使用也是比较简单的
使用Inception Model
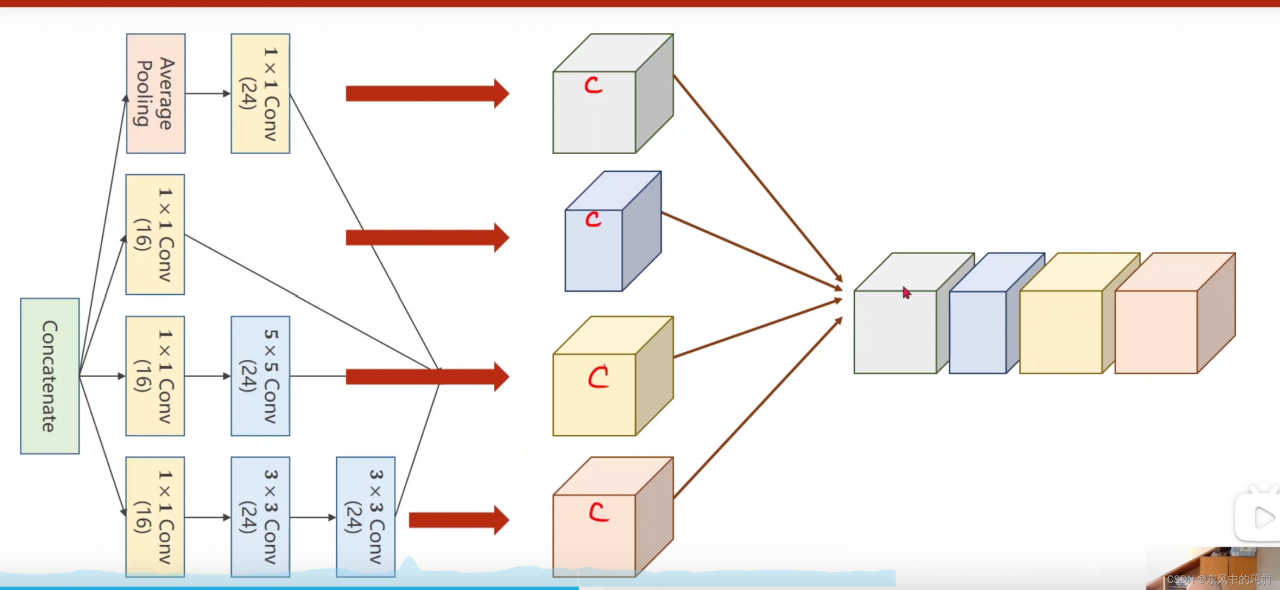
# -*-coding = utf-8
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# define a graphic card
class Inception(torch.nn.Module):
def __init__(self, in_channels):
super(Inception, self).__init__()
# these are different branches in the picture
self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
pool = self.branch_pool(pool)
out = [branch1x1, branch3x3, branch5x5, pool]
return torch.cat(out, dim=1)
# cat the channels
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.Conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.Conv2 = torch.nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = Inception(in_channels=10)
self.incep2 = Inception(in_channels=20)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.Conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.Conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
# show the structure of the model
# because we use cross-entropy as loss
# so we needn't to do softmax and binary entropy
def train(epochs):
running_loss = 0.0
for index, (x, y) in enumerate(train_loader):
# x,y = x.to(device),y.to(device)
# graphic card
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
running_loss = running_loss + loss.item()
print(f"epoch:{epochs}\nloss:{running_loss}")
def test():
correct = 0
tot = 0
# because we don't need to calculate the gradient in test,
# so we use this structure
with torch.no_grad():
for data in test_loader:
image, label = data
# image, label = image.to(device),label.to(device)
output = model(image)
tot += label.size(0)
_, pred = torch.max(output, dim=1)
correct = correct + (label == pred).sum().item()
print(f"Accuracy:{correct / tot * 100}%")
if __name__ == "__main__":
model = Net()
# model.to(device=device)
# if need train on graphic card
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01, momentum=0.5)
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
# why use these two numbers?
])
train_dataset = datasets.MNIST(root=r"dataset\mnist/",
download=True,
train=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root=r"dataset\mnist",
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
for index in range(10):
train(index)
test()
- 感觉inception模型就是让网络自动选择那种卷积方式最好。
- 通过这个模型,可以达到目前最高的识别率(98.6%)
- 直接堆3x3的卷积网络会遇到梯度消失等各种困难。
Residual 模型(残差神经网络)
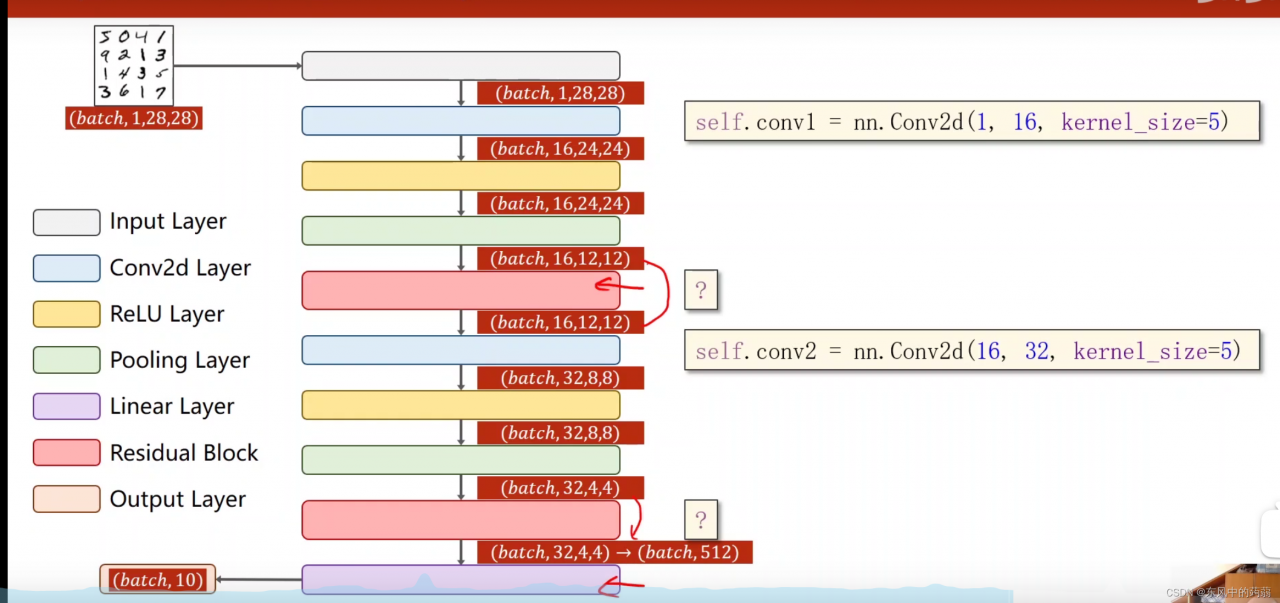
- 里面最重要的是residual block,他的输入和输出的channels是一样的,这样的话梯度才能在他们之间传播。
# -*-coding = utf-8
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# define a graphic card
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.Conv1 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.Conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.Conv1(x))
y = self.Conv2(y)
return F.relu(x+y)
# this is the structure of the residual model
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.Conv1 = torch.nn.Conv2d(1, 16, kernel_size=5)
self.Conv2 = torch.nn.Conv2d(16, 32, kernel_size=5)
self.mp = torch.nn.MaxPool2d(2)
self.rb1 = ResidualBlock(16)
self.rb2 = ResidualBlock(32)
self.fc = torch.nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.Conv1(x)))
x = self.rb1(x)
x = F.relu(self.mp(self.Conv2(x)))
x = self.rb2(x)
x = x.view(in_size, -1)
return self.fc(x)
# because we use cross-entropy as loss
# so we needn't to do softmax and binary entropy
def train(epochs):
running_loss = 0.0
for index, (x, y) in enumerate(train_loader):
# x,y = x.to(device),y.to(device)
# graphic card
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
running_loss = running_loss + loss.item()
print(f"epoch:{epochs}\nloss:{running_loss}")
def test():
correct = 0
tot = 0
# because we don't need to calculate the gradient in test,
# so we use this structure
with torch.no_grad():
for data in test_loader:
image, label = data
# image, label = image.to(device),label.to(device)
output = model(image)
tot += label.size(0)
_, pred = torch.max(output, dim=1)
correct = correct + (label == pred).sum().item()
print(f"Accuracy:{correct / tot * 100}%")
if __name__ == "__main__":
model = Net()
# model.to(device=device)
# if need train on graphic card
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01, momentum=0.5)
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
# why use these two numbers?
])
train_dataset = datasets.MNIST(root=r"dataset\mnist/",
download=True,
train=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root=r"dataset\mnist",
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
for index in range(10):
train(index)
test()
- 在残差神经网络中,准确率可以达到99%以上
- 最重要的是残差神经网络的梯度的解决技巧,通过跳跃传播
版权声明:本文为m0_50089378原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。