Elastic Search原理知识点梳理
1、基础组成
1.1 Node 与 Cluster
- Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
- 单个 Elastic 实例称为一个节点(node),一组节点构成一个集群(cluster)。
1.2、Index:基本单位
- Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index),查找数据的时候,直接查找该索引。
- 所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词(相当于mysql中一张表),每个 Index (即数据库)的名字必须是小写。
1.3、Document:表中的一行
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示
{ "user": "张三", "title": "工程师", "desc": "数据库管理" }同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率 。
field: 每个 document 有多个 field,每个 field 就代表了这个 document 中的一个字段的值。
1.4、Type
- Document 可以分组,比如
weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。 - 不同的 Type 应该有相似的结构(schema),举例来说,
id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。 - 一般一个index中只有一个type
- mapping: mapping 就是这个 type 的表结构定义 ,比如里面有哪些字段,每个字段什么类型。
- Document 可以分组,比如
2、 es 的分布式架构原理(es 是如何实现分布式的啊)?
shard:每个索引可以拆分成多个shard,每个 shard 存储部分数据。好处:
一:拆分多个 shard 是有好处的,一是支持横向扩展,比如你数据量是 3T,3 个 shard,每个 shard 就 1T 的数据,若现在数据量增加到 4T,怎么扩展,很简单,重新建一个有 4 个 shard 的索引,将数据导进去;
二是提高性能,数据分布在多个 shard,即多台服务器上,所有的操作,都会在多台机器上并行分布式执行,提高了吞吐量和性能。接着就是这个 shard 的数据实际是有多个备份,就是说每个 shard 都有一个
primary shard,负责写入数据,但是还有几个replica shard–在其他机器上。primary shard写入数据之后,会将数据同步到其他几个replica shard上去。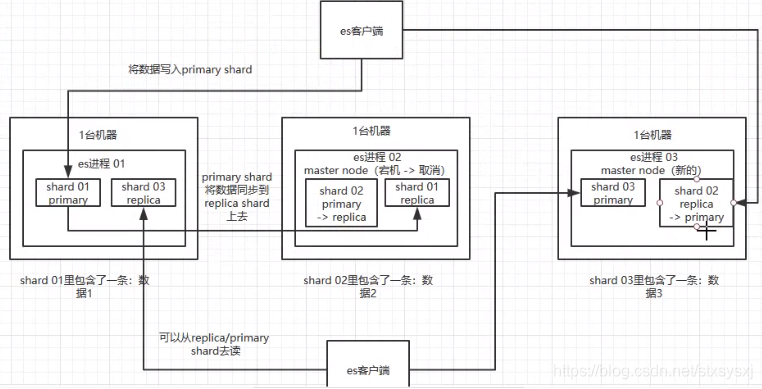
主从机制:高可用
- 通过 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,还有别的数据副本在别的机器上。
- es 集群多个节点,会自动选举一个节点为 master 节点
- 这个 master 节点维护索引元数据、负责切换 primary shard 和 replica shard 身份:要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。
- 非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard(将其他机器上的此台上的primary shard的副本replica shard切换为primary shard)。接着你要是修复了那个宕机机器,重启了之后,master 节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据,让集群恢复正常 。
3、 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗?
1、写数据过程简介:
客户端选择一个 node 发送请求过去,这个 node 就是
coordinating node(协调节点)。coordinating node对 document 进行路由(hash),将请求转发给对应的 node(有 primary shard)。实际的 node 上的
primary shard处理请求,然后将数据同步到replica node。coordinating node如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。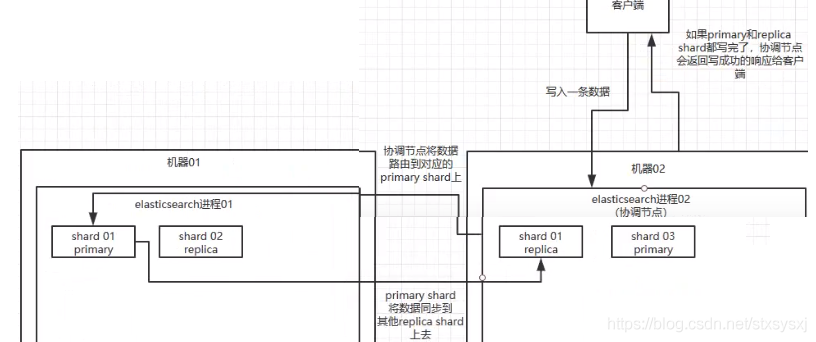
2、写数据详细过程(底层原理)
- 2.1、es写流程有4个概念:refresh、flush、translog、merge
- 2.2、es的准实时:
NRT,全称near real-time。默认是每隔 1 秒 refresh 一次的,所以 es 是准实时的,因为写入的数据 1 秒之后才能被看到。可以通过 es 的restful api或者java api,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入os cache中,让数据立马就可以被搜索到。只要数据被输入os cache中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在translog里面已经持久化到磁盘去一份 。 - 2.3、流程:
refresh- 1、先写入内存 buffer,在 buffer里的时候数据是搜索不到的;同时将数据写入
translog日志文件 。 - 2、如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据
refresh到一个新的segment file中,但是此时数据不是直接进入segment file磁盘文件,而是先进入os cache(进入OS Cache就可以被搜索到了) 。这个过程就是refresh。- 什么是os cache: 操作系统里面,磁盘文件其实都有一个东西,叫做
os cache,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。只要buffer中的数据被 refresh 操作刷入os cache中,这个数据就可以被搜索到了。
- 什么是os cache: 操作系统里面,磁盘文件其实都有一个东西,叫做
- 3、 每隔 1 秒钟,es 将 buffer(这一秒必须是有数据的) 中的数据写入一个新的
segment file,每秒钟会产生一个新的磁盘文件segment file,这个segment file中就存储最近 1 秒内 buffer 中写入的数据。 - 4、 重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将
buffer数据写入一个又一个新的segment file中去,每次refresh完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发commit操作
- 1、先写入内存 buffer,在 buffer里的时候数据是搜索不到的;同时将数据写入
- 2.4、流程:
flush- 1、 commit 操作发生第一步,就是将 buffer 中现有数据
refresh到os cache中去,清空 buffer。然后,将一个commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。最后清空 现有 translog 日志文件,重启一个 translog,此时commit操作完成 。 - 2、 这个 commit 操作叫做
flush。默认 30 分钟自动执行一次flush,但如果 translog 过大,也会触发flush。flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache 中的数据 fsync 强刷到磁盘上去
- 1、 commit 操作发生第一步,就是将 buffer 中现有数据
- 2.5、translog的作用:
- 1、执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器宕机,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件
translog中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。 - translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接
fsync到磁盘,但是性能会差很多
- 1、执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器宕机,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件
- 2.6、总结:
- 1、数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache
- 2、到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。
- 3、每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失)
- 4、translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
- 5、 数据写入 segment file 之后,同时就建立好了倒排索引。
3、删除和更新
- buffer 每 refresh 一次,就会产生一个
segment file,所以默认情况下是 1 秒钟一个segment file,这样下来segment file会越来越多 - 3.1、流程:merge(用作整合segment file和物理删除doc)
- 此时会定期执行
merge。每次 merge 的时候,会将多个segment file合并成一个,同时这里会将标识为deleted的 doc 给物理删除掉,然后将新的segment file写入磁盘,这里会写一个commit point,标识所有新的segment file,然后打开segment file供搜索使用,同时删除旧的segment file
- 此时会定期执行
- 3.2、删除:如果是删除操作,会生成一个
.del文件,里面将某个 doc 标识为deleted状态,那么搜索的时候根据.del文件就知道这个 doc 是否被删除了。 - 3.3、更新:如果是更新操作,就是将原来的 doc 标识为
deleted状态,然后新写入一条数据。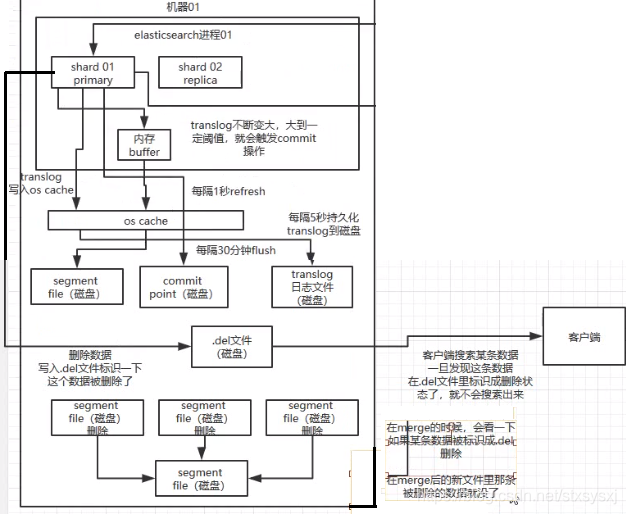
- buffer 每 refresh 一次,就会产生一个
4、es 读数据过程
可以通过
doc id来查询,会根据doc id进行 hash,判断出来当时把doc id分配到了哪个 shard 上面去,从那个 shard 去查询。客户端发送请求到任意一个 node,成为
coordinate node(协调节点)。coordinate node对doc id进行哈希路由,将请求转发到对应的 node,此时会使用round-robin随机轮询算法,在primary shard以及其所有 replica 中随机选择一个,让读请求负载均衡。接收请求的 node 返回 document 给
coordinate node。coordinate node返回 document 给客户端。写请求是写入 primary shard,然后同步给所有的 replica shard; 读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
5、es搜索过程
- 客户端发送请求到一个
coordinate node。 - 协调节点将搜索请求转发到所有的 shard 对应的
primary shard或replica shard,都可以。 - query phase:每个 shard 将自己的搜索结果(其实就是一些
doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - fetch phase:接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
- 客户端发送请求到一个
4、 es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
1、filesystem cache:容纳总数据量的一半
首先:往 es 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到
filesystem cache里面。方法一:加内存,加到一半
方法二:
- 仅仅在 es 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给
filesystem cache的是 100G,那么你就将索引数据控制在100G以内。 - 将其他字段全部存入mysql/hbase
- 流程就是从es中查询到
doc id,然后拿着id去数据库中查询。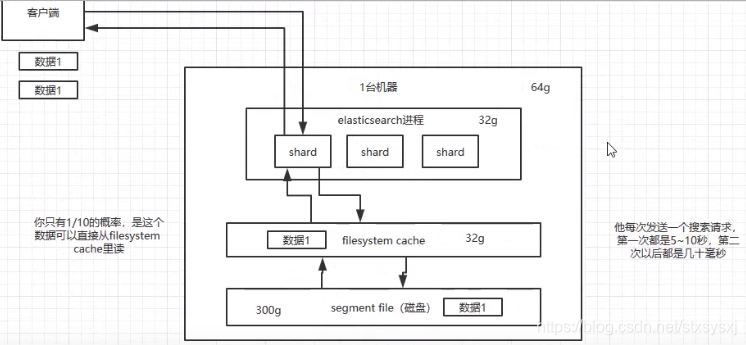
- 仅仅在 es 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给
2、数据预热:
- 经常会有人访问的热数据,最好做一个专门的缓存预热子系统,就是对热数据每隔一段时间,就提前访问一下,让数据进入
filesystem cache里面去 。
- 经常会有人访问的热数据,最好做一个专门的缓存预热子系统,就是对热数据每隔一段时间,就提前访问一下,让数据进入
2、冷热分离
- es 做水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在
filesystem os cache里,别让冷数据给冲刷掉 。
- es 做水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在
3、document模型设计:尽量别用复杂的关联查询
- 先在Java 系统里就完成关联,将关联好(比如join)的数据直接写入 es 中,搜索的时候,就不需要利用 es 的搜索语法来完成 join 之类的关联搜索了 。
4、分页性能优化
- 情况: 每页是 10 条数据,你现在要查询第 100 页,实际上是会把每个 shard 上存储的前 1000 条数据都查到一个协调节点上,如果你有个 5 个 shard,那么就有 5000 条数据,接着协调节点对这 5000 条数据进行一些合并、处理,再获取到最终第 100 页的 10 条数据。
- 解决方法:
- 不允许深度分页
- 下拉类型的分页:用
scroll api- scroll 会一次性给你生成所有数据的一个快照,然后每次滑动向后翻页就是通过游标
scroll_id移动,获取下一页、下一页。 - 初始化时必须指定
scroll参数,告诉 es 要保存此次搜索的上下文多长时间。 - 缺点:不能随意跳页
- scroll 会一次性给你生成所有数据的一个快照,然后每次滑动向后翻页就是通过游标
5、 es 生产集群的部署架构是什么?每个索引的数据量大概有多少?每个索引大概有多少个分片?
es 生产集群部署5 台机器,每台机器是 6 核 64G 的,集群总内存是 320G。
es 集群的日增量数据大概是 2000 万条,每天日增量数据大概是 500MB,每月增量数据大概是 6 亿,15G。目前系统已经运行了几个月,现在 es 集群里数据总量大概是 100G 左右。
索引大概有多少个分片?es 生产集群部署5 台机器,每台机器是 6 核 64G 的,集群总内存是 320G。
es 集群的日增量数据大概是 2000 万条,每天日增量数据大概是 500MB,每月增量数据大概是 6 亿,15G。目前系统已经运行了几个月,现在 es 集群里数据总量大概是 100G 左右。
目前线上有 5 个索引(这个结合你们自己业务来,看看自己有哪些数据可以放 es 的),每个索引的数据量大概是 20G,所以这个数据量之内,我们每个索引分配的是 8 个 shard,比默认的 5 个 shard 多了 3 个 shard。
参考文章:https://github.com/doocs/advanced-java