编码解码知识

print('肥鼠'.encode('utf-8'))
print('肥鼠'.encode('gbk'))
print(b'\xe8\x82\xa5\xe9\xbc\xa0'.decode('utf-8'))
print(b'\xb7\xca\xca\xf3'.decode('gbk'))
打印出来的是下图
b'\xe8\x82\xa5\xe9\xbc\xa0'
b'\xb7\xca\xca\xf3'
肥鼠
肥鼠
如果出现报错SyntaxError: unexpected EOF while parsing,看看我们是否少打了括号之类的
print(b'\xe6\x88\x91\xe5\x96\x9c\xe6\xac\xa2\xe4\xbd\xa0'.decode('utf-8'))
print(b'\xce\xd2\xcf\xb2\xbb\xb6\xc4\xe3'.decode('gbk'))
哈哈哈,这是程序员的一种闷骚表白方式。
我喜欢你
我喜欢你
所谓的编码,其实本质就是把str(字符串)类型的数据,利用不同的编码表,转换成bytes(字节)类型的数据。
print(type('肥鼠'))
print(type(b'\xe8\x82\xa5\xe9\xbc\xa0'))
<class 'str'>
<class 'bytes'>
\x代表分隔符
$ python
Python 3.7.3 (default, Mar 27 2019, 22:11:17)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> open('/home/warmtree/文档/919.odt')
<_io.TextIOWrapper name='/home/warmtree/文档/919.odt' mode='r' encoding='UTF-8'>
>>> file=open('/home/warmtree/文档/919.odt','r',encoding='utf-8')
>>> filecont=file.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/warmtree/anaconda3/lib/python3.7/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc6 in position 15: invalid continuation byte
>>> print(file.read())
报错
f = open('./1.txt', 'a',encoding='utf-8')
f.write('难念的经\n')
fc=f.read()
print(fc)
f.close()
io.UnsupportedOperation: not readable
为什么不能直接在write()后面直接承接read()
f1 = open('./1.txt','a',encoding='utf-8')
#以追加的方式打开一个文件,尽管并不存在这个文件,但这行代码已经创建了一个txt文件了
f1.write('难念的经')
#写入'难念的经'的字符串
f1.close()
#关闭文件
f2 = open('./1.txt','r',encoding='utf-8')
#以读的方式打开这个文件
content = f2.read()
#把读取到的内容放在变量content里面
print(content)
#打印变量content
f2.close()
#关闭文件

新的知识点
为了避免打开文件后忘记关闭,占用资源或当不能确定关闭文件的恰当时机的时候,我们可以用到关键字with,之前的例子可以写成这样:
# 普通写法
file1 = open('abc.txt','a')
file1.write('张无忌')
file1.close()
# 使用with关键字的写法
with open('abc.txt','a') as file1:
#with open('文件地址','读写模式') as 变量名:
#格式:冒号不能丢
file1.write('张无忌')
#格式:对文件的操作要缩进
#格式:无需用close()关闭
小练习
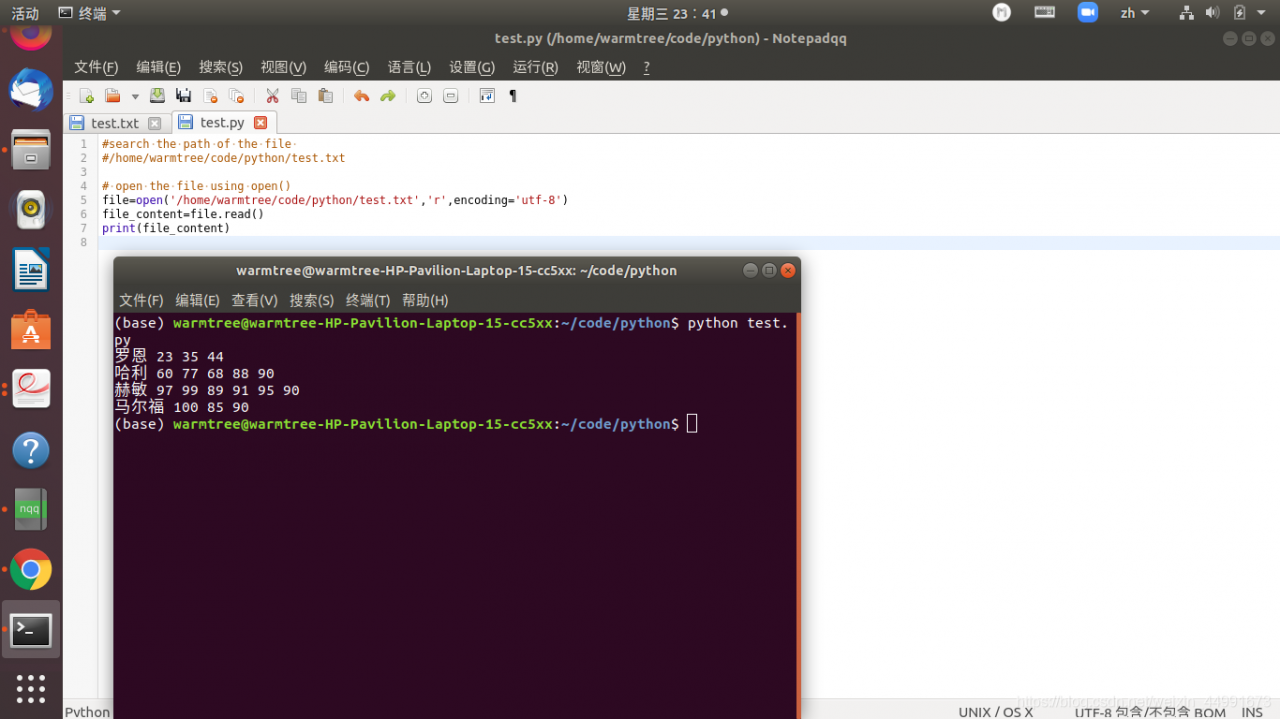 为什么这样的读取方式为空
为什么这样的读取方式为空
file=open('/home/warmtree/code/python/test.txt','r',encoding='utf-8')
file_content=file.read()
print('file.read()\n',file_content)
file_lines = file.readlines()
file.close()
print(file_lines)
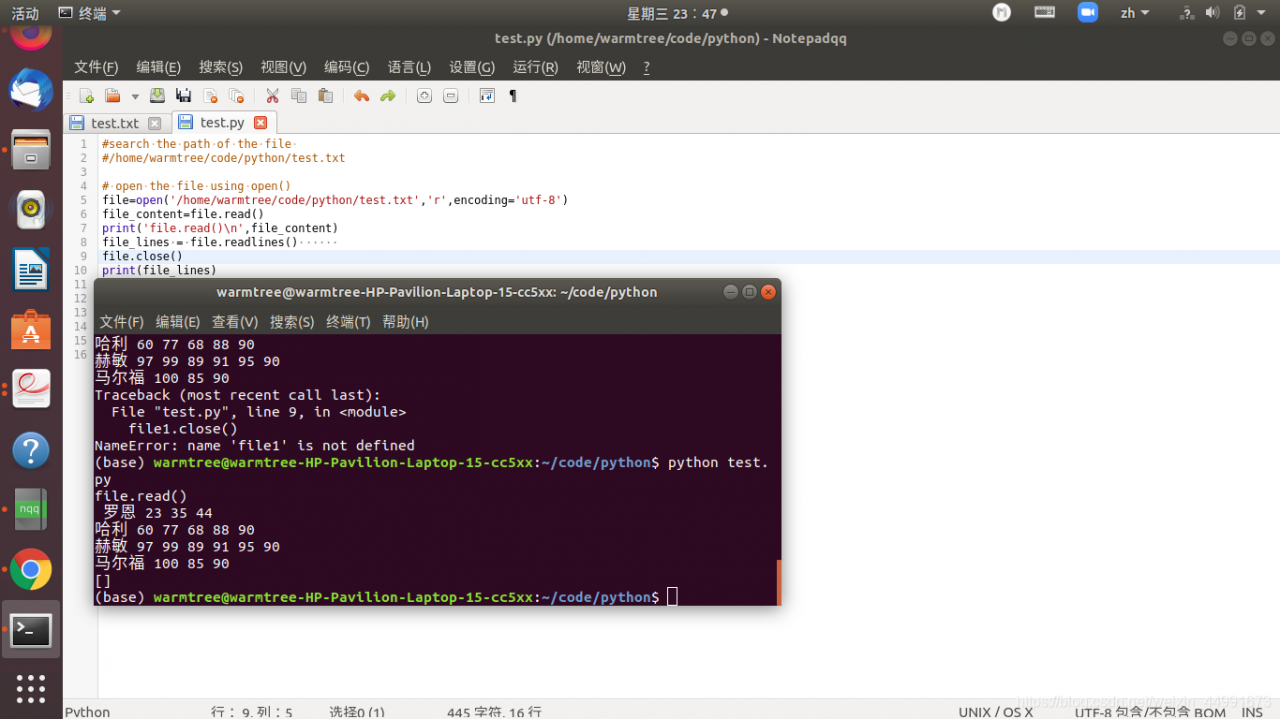 重新书写一遍文件open则可以逐行显示:
重新书写一遍文件open则可以逐行显示:
# open the file using open()
file=open('/home/warmtree/code/python/test.txt','r',encoding='utf-8')
file_content=file.read()
print('file.read()\n',file_content)
file.close()
'''
file_lines = file.readlines()
file.close()
print(file_lines)
'''
file1 = open('/home/warmtree/code/python/test.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
print(file_lines)
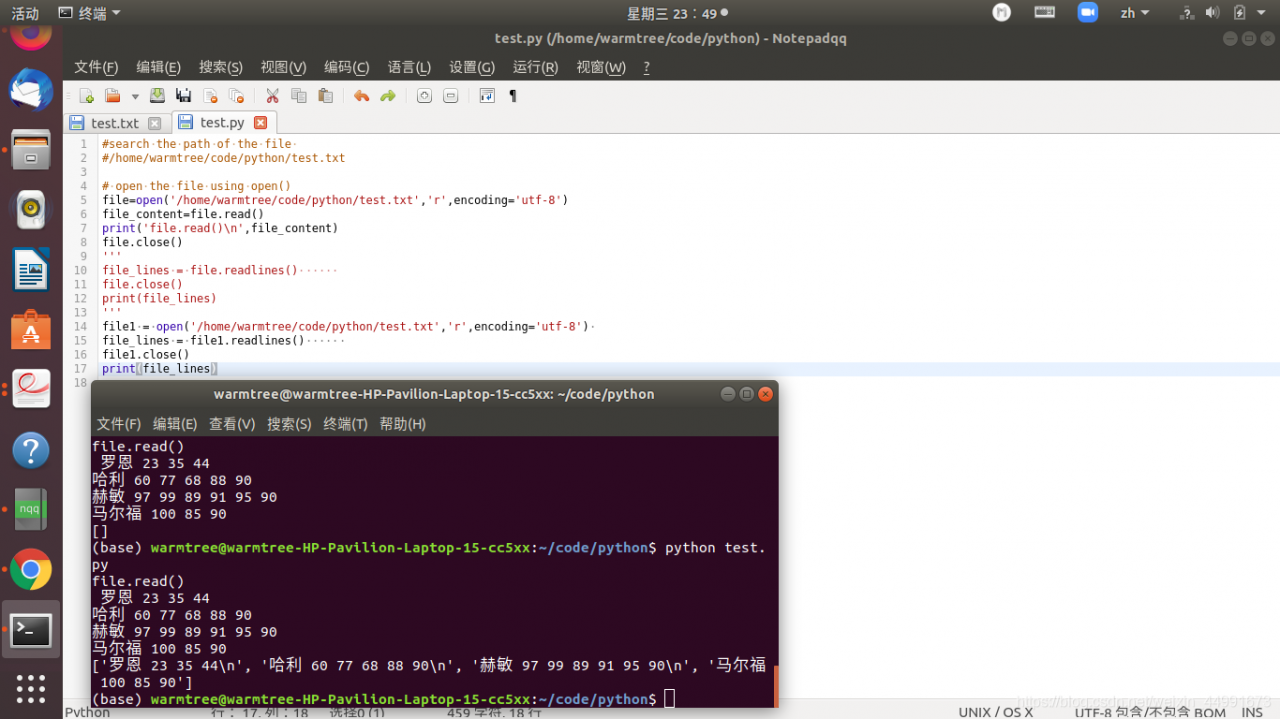
# open the file using open()
file=open('/home/warmtree/code/python/test.txt','r',encoding='utf-8')
file_content=file.read()
print('file.read()\n',file_content)
'''
file.read()
罗恩 23 35 44
哈利 60 77 68 88 90
赫敏 97 99 89 91 95 90
马尔福 100 85 90
'''
file.close()
'''
file_lines = file.readlines()
file.close()
print(file_lines)
'''
file1 = open('/home/warmtree/code/python/test.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
#readlines() 会从txt文件取得一个列表,列表中的每个字符串就是scores.txt中的每一行。而且每个字符串后面还有换行的\n符号
print(file_lines)
'''
['罗恩 23 35 44\n', '哈利 60 77 68 88 90\n', '赫敏 97 99 89 91 95 90\n', '马尔福 100 85 90']
'''
for i in file_lines: #用for...in...把每一行的数据遍历
print(i) #打印变量i
'''
罗恩 23 35 44
哈利 60 77 68 88 90
赫敏 97 99 89 91 95 90
马尔福 100 85 90
'''
#把这里每一行的名字、分数也分开,这时需要我们使用split()来把字符串分开,它会按空格把字符串里面的内容分开
for i in file_lines: #用for...in...把每一行的数据遍历
data =i.split() #把字符串切分成更细的一个个的字符串
print(data) #打印出来看看
'''
['罗恩', '23', '35', '44']
['哈利', '60', '77', '68', '88', '90']
['赫敏', '97', '99', '89', '91', '95', '90']
['马尔福', '100', '85', '90']
'''
Join()用于字符串的合并
a=['c','a','t']
b=''
print(b.join(a))
# c a t
c='-'
print(c.join(a))
#c-a-t
有些问题待处理
file1 = open('winner.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
print(file_lines)
dict_scores={}
list_scores = []
final_scores = []
for data in file_lines:
data.split()
print(data[0:3])
print(data[-4:])
list_scores.append(int(data[-4:]))
#del data[-4:]
print(data)
print(list_scores)
list_scores.sort()
print(list_scores)
版权声明:本文为weixin_44991673原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。