原理
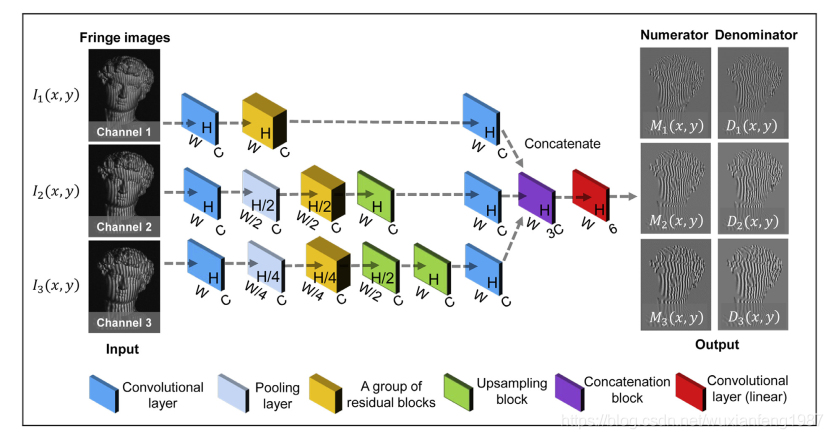
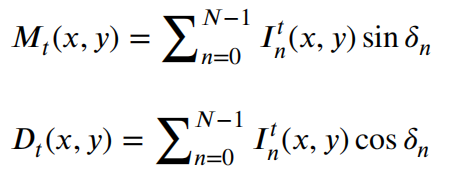
监督集构造
由12步相移获得的包裹相位如下图所示:

存在两个情况:
一是右上角质量比较差,出现很多噪点;二是相位截断处的质量不高,边界不整齐。
调整思路1:
1)增强亮度
2)换成32步相移(实验感觉12步已经足够了)
3)找到合适的波长
---------------------------------------------------------------------------------------
出现噪点的原因很大概率是由于景深导致的周边模糊,我调节了镜头焦距,发现不能使整个场景都清晰,因为相机是倾向放置的,景深范围不够确实会导致这样的问题。
光圈越大,景深越小;光圈越小,景深越大
调整思路2:
调小光圈,使用白光
---------------------------------------------------------------------------------------
深度学习框架复现
参数
W,H为原始图像的宽,高
convolutional layers:kernel:3 × 3, stride:1,Zero-padding,C = 50
max-pooling layer: 2 × 2 or 4 × 4
激活函数:Relu
损失函数:![]()
优化:Adam Optimizer
初始学习率:10^-4,如果验证损失在10个时期内停止改善,我们将其减少2倍
原始条纹图像{ I 1 ( x,y),I 2 ( x,y),I 3 ( x,y )}被除以255进行归一化,这可以使网络的学习过程更容易
卷积层
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False, padding_mode='replicate')池化层
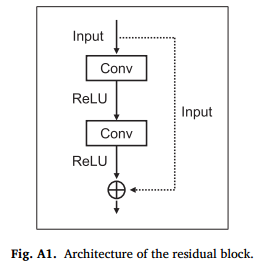
残差Block
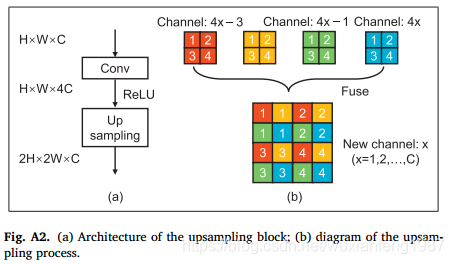
上采样层
数据首先通过一个带有ReLU激活的卷积层。然后我们使用四重滤波器从输入中提取特征,为后续的上采样提供丰富的信息
连接层
import os
import cv2
import numpy as np
import random
def load_img(labelfile, imagesdir):
with open(labelfile, "r") as f:
lines = f.readlines()
lines = [line.replace("\n", "") for line in lines]
files = []
for index, line in enumerate(lines):
filesRelativePath = line.split(" ")
filesAbsolutePath = [f"{imagesdir}/{frp}" for frp in filesRelativePath]
files.append(filesAbsolutePath)
return files
def imread(path):
return cv2.imdecode(np.fromfile(path, dtype=np.uint8), 1)
def mkdirs_from_file_path(path):
try:
path = path.replace("\\", "/")
p0 = path.rfind('/')
if p0 != -1:
path = path[:p0]
if not os.path.exists(path):
os.makedirs(path)
except Exception as e:
print(e)
def randrf(low, high):
return random.uniform(0, 1) * (high - low) + lowimport torch
import torch.nn as nn
import torchvision.transforms.functional as T
import numpy as np
class mseLoss(nn.Module):
def forward(self, fringe1Real, fringe1Image, fringe2Real,fringe2Image,fringe3Real,fringe3Image,
pred1Real, pred1Image, pred2Real, pred2Image, pred3Real, pred3Image):
metric_loss = torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
loss1 = metric_loss(fringe1Real, pred1Real)
loss2 = metric_loss(fringe1Image, pred1Image)
loss3 = metric_loss(fringe2Real, pred2Real)
loss4 = metric_loss(fringe2Image, pred2Image)
loss5 = metric_loss(fringe3Real, pred3Real)
loss6 = metric_loss(fringe4Image, pred4Image)
loss = loss1 + loss2 + loss3 + loss4 + loss5 + loss6
return loss/6import torch
import torch.nn as nn
import random
import numpy as np
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False, padding_mode='replicate')
class conv(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(conv, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU(inplace=False)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.act(out)
return out
# Up Sample Module
# 双线性插值Bilinear+Conv+BN+Activation的上采样模块,优于用反卷积、最近邻插值等,所以比较推荐
class UpModule(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=2, stride=2, bias=False, mode="UCBA"):
super(UpModule, self).__init__()
self.mode = mode
if self.mode == "UCBA":
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
self.conv = CBAModule(in_channels, out_channels, 3, padding=1, bias=bias)
elif self.mode == "DeconvBN":
self.dconv = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, bias=bias)
self.bn = nn.BatchNorm2d(out_channels)
elif self.mode == "DeCBA":
self.dconv = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, bias=bias)
self.conv = CBAModule(out_channels, out_channels, 3, padding=1, bias=bias)
else:
raise RuntimeError(f"Unsupport mode: {mode}")
def forward(self, x):
if self.mode == "UCBA":
return self.conv(self.up(x))
elif self.mode == "DeconvBN":
return F.relu(self.bn(self.dconv(x)))
elif self.mode == "DeCBA":
return self.conv(self.dconv(x))
# SENet SANet
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.se = nn.Sequential(
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size),
HSigmoid()
)
def forward(self, x):
return x * self.se(self.pool(x))
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=False)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
residual = out
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = out + residual
out = self.relu(out)
return out
class ResidualBlockUp(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlockUp, self).__init__()
self.conv1 = conv3x3(in_channels, 2 * out_channels, stride)
self.bn1 = nn.BatchNorm2d(2 * out_channels)
self.relu = nn.ReLU(inplace=False)
self.conv2 = conv3x3(2 * out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
residual = out
out = self.bn1(out)
out = self.relu(out)
out += residual
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class UDLP(torch.nn.Module):
def __init__(self):
super(UDLP, self).__init__()
self.conv_3x3_1 = conv(1, 50)
self.conv_3x3_2 = conv(50, 50)
self.head = nn.Conv2d(150, 6, 1)
self.max_pool_2x2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.max_pool_4x4 = nn.MaxPool2d(kernel_size=4, stride=4)
self.Resblock1 = ResidualBlock(50, 50)
self.up_trans_1 = nn.ConvTranspose2d(
in_channels=50,
out_channels=50,
kernel_size=2,
stride=2)
def forward(self, image):
# ch1
x1_1 = self.conv_3x3_1(image[:,0,:,:].unsqueeze(0))
x1_2 = self.Resblock1(x1_1)
x1_3 = self.conv_3x3_2(x1_2)
# ch2
x2_1 = self.conv_3x3_1(image[:,1,:,:].unsqueeze(0))
x2_2 = self.max_pool_2x2(x2_1)
x2_3 = self.Resblock1(x2_2)
x2_4 = self.up_trans_1(x2_3)
x2_5 = self.conv_3x3_2(x2_4)
# ch3
x3_1 = self.conv_3x3_1(image[:,2,:,:].unsqueeze(0))
x3_2 = self.max_pool_4x4(x3_1)
x3_3 = self.Resblock1(x3_2)
x3_4 = self.up_trans_1(x3_3)
x3_5 = self.up_trans_1(x3_4)
x3_6 = self.conv_3x3_2(x3_5)
x = torch.cat([x1_3, x2_5, x3_6], 1) # 150*W*H
x = self.head(x) # 6*W*H
return x
if __name__ == "__main__":
image = torch.rand((1, 3, 256, 256))
model = UDLP()
print(model(image).size())
from torch.utils.data import Dataset
import torch
import torch.nn as nn
import torchvision.transforms.functional as T
import UDLP
import common
import loss
import loger
class MyDataset(Dataset):
def __init__(self, labelfile, imagesdir):
self.items = load_img(labelfile, imagesdir)
def __getitem__(self, index):
imgs = self.items[index]
fringe1 = common.imread(imgs[0])
fringe2 = common.imread(imgs[1])
fringe3 = common.imread(imgs[2])
fringe1Real = common.imread(imgs[3])
fringe1Image = common.imread(imgs[4])
fringe2Real = common.imread(imgs[5])
fringe2Image = common.imread(imgs[6])
fringe3Real = common.imread(imgs[7])
fringe3Image = common.imread(imgs[8])
fringe1 = (fringe1 / 255.0)
fringe2 = (fringe2 / 255.0)
fringe3 = (fringe3 / 255.0)
fringe1Real = (fringe1Real / 255.0)
fringe1Image = (fringe1Image / 255.0)
fringe2Real = (fringe2Real / 255.0)
fringe2Image = (fringe2Image / 255.0)
fringe3Real = (fringe3Real / 255.0)
fringe3Image = (fringe3Image / 255.0)
return T.to_tensor(fringe1), T.to_tensor(fringe2), T.to_tensor(fringe3), \
T.to_tensor(fringe1Real), T.to_tensor(fringe1Image), T.to_tensor(fringe2Real), \
T.to_tensor(fringe2Image),T.to_tensor(fringe3Real), T.to_tensor(fringe3Image)
def __len__(self):
return len(self.items)
class App(object):
def __init__(self, labelfile, imagesdir):
self.batch_size = 18
self.lr = 1e-4
self.gpus = [0, 1, 2, 3] # [0, 1, 2, 3]
self.gpu_master = self.gpus[0]
self.model = UDLP()
self.model.init_weights() # how to init weights?
self.model.cuda(device=self.gpu_master)
self.model.train()
self.mse_loss = losses.mseLoss()
self.train_dataset = MyDataset(labelfile, imagesdir)
self.train_loader = DataLoader(dataset=self.train_dataset, batch_size=self.batch_size, shuffle=True, num_workers=24)
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr)
self.per_epoch_batchs = len(self.train_loader)
self.iter = 0
self.epochs = 150
def set_lr(self, lr):
self.lr = lr
log.info(f"setting learning rate to: {lr}")
for param_group in self.optimizer.param_groups:
param_group["lr"] = lr
def train_epoch(self, epoch):
for indbatch, (fringe1, fringe2, fringe3, fringe1Real, fringe1Image, fringe2Real,fringe2Image,fringe3Real,fringe3Image) in enumerate(self.train_loader):
self.iter += 1
batch_size = self.batch_size
images = torch.cat([fringe1, fringe2, fringe3], 0)
pred1Real, pred1Image, pred2Real, pred2Image, pred3Real, pred3Image = self.model(images)
loss = mse_loss(fringe1Real, fringe1Image, fringe2Real,fringe2Image,fringe3Real,fringe3Image,
pred1Real, pred1Image, pred2Real, pred2Image, pred3Real, pred3Image)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
epoch_flt = epoch + indbatch / self.per_epoch_batchs
if indbatch % 10 == 0:
log.info(f"iter: {self.iter}, lr: {self.lr:g}, epoch: {epoch_flt:.2f}, loss: {loss.item():.2f}")
def train(self):
lr_scheduer = {
1: 1e-3,
2: 2e-3,
3: 1e-3,
60: 1e-4,
120: 1e-5
}
# train
self.model.train()
for epoch in range(self.epochs):
if epoch in lr_scheduer:
self.set_lr(lr_scheduer[epoch])
self.train_epoch(epoch)
file = f"{jobdir}/models/{epoch + 1}.pth"
common.mkdirs_from_file_path(file)
torch.save(self.model.module.state_dict(), file)
trial_name = "uDLP"
jobdir = f"jobs/{trial_name}"
log = logger.create(trial_name, f"{jobdir}/logs/{trial_name}.log")
app = App("webface/train/label.txt", "webface/WIDER_train/images")
app.train()