python爬取图片然后保存在文件夹中
直接上代码:
import os
import requests
import re
def getimg(soup,i):
print('http:'+ soup[0])
root = "D://tu//tu" # 保存的根目录
j=1
for k in soup:
print(k)
path = root + str(j) + ".jpg" # 保存的地址
if not os.path.exists(path): # 如果文件不存在就爬取并保存
mun='http:'+ k
r=requests.get(mun)
j=j+1
with open(path, 'wb') as f: # 'wb'以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
f.write(r.content) # content返回二进制数据,所以使用'wb'
f.close()
print("文件保存成功")
else:
print("文件已存在")
def main():
url = 'https://s.taobao.com/search?q=%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20201126&ie=utf8'
file = open('C:/Users/YHAA-1ED2A3/Desktop/taobao_product.txt','w',encoding='utf-8')
cookie_str = r't=e62fc3896f26735342c795d27a369781; c83ebeb; xlly_s=1; '
cookies = {}
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
r = requests.get(url, headers = headers, cookies = cookies)
r.encoding = r.apparent_encoding
demo = r.text
soup = re.findall(r'"pic_url":"([^"]+)"',r.text,re.I)
getimg(soup,1)
main()
结果: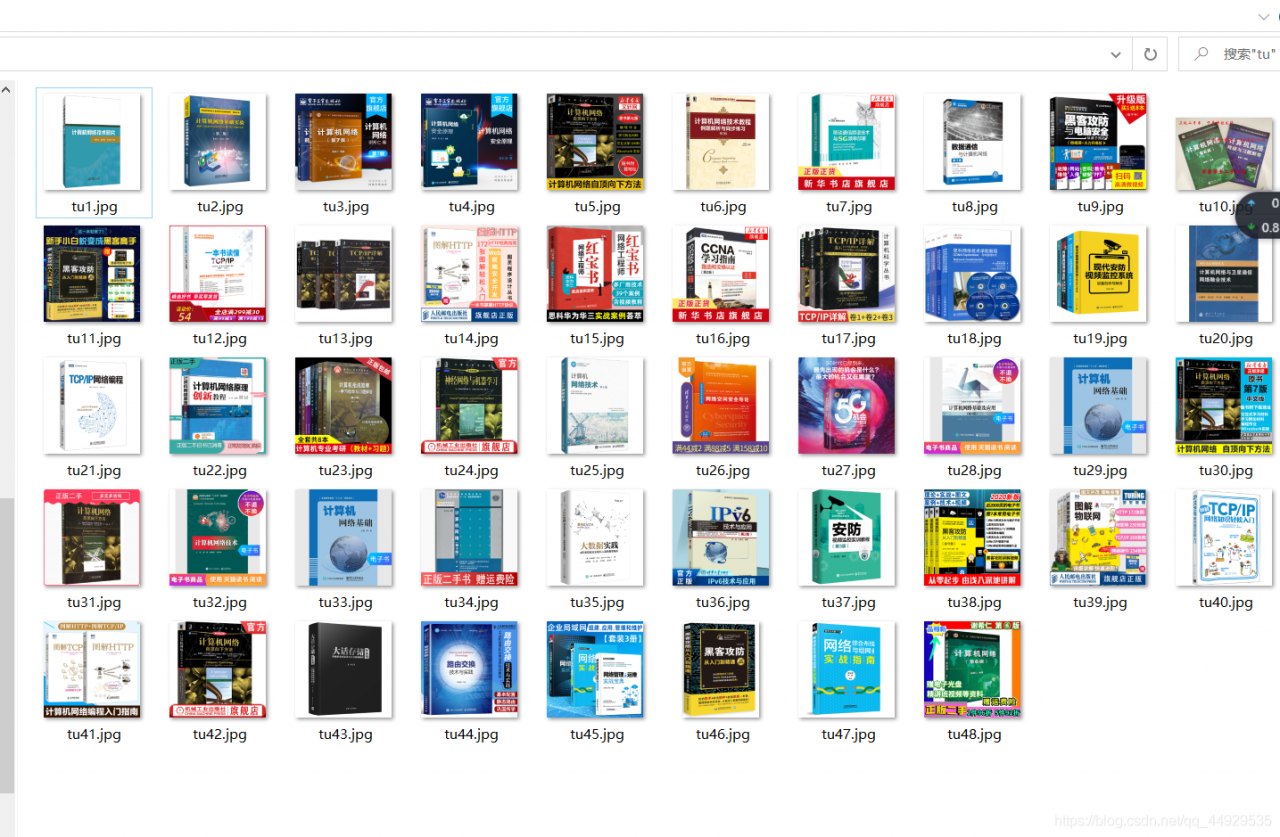
版权声明:本文为qq_44929535原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。