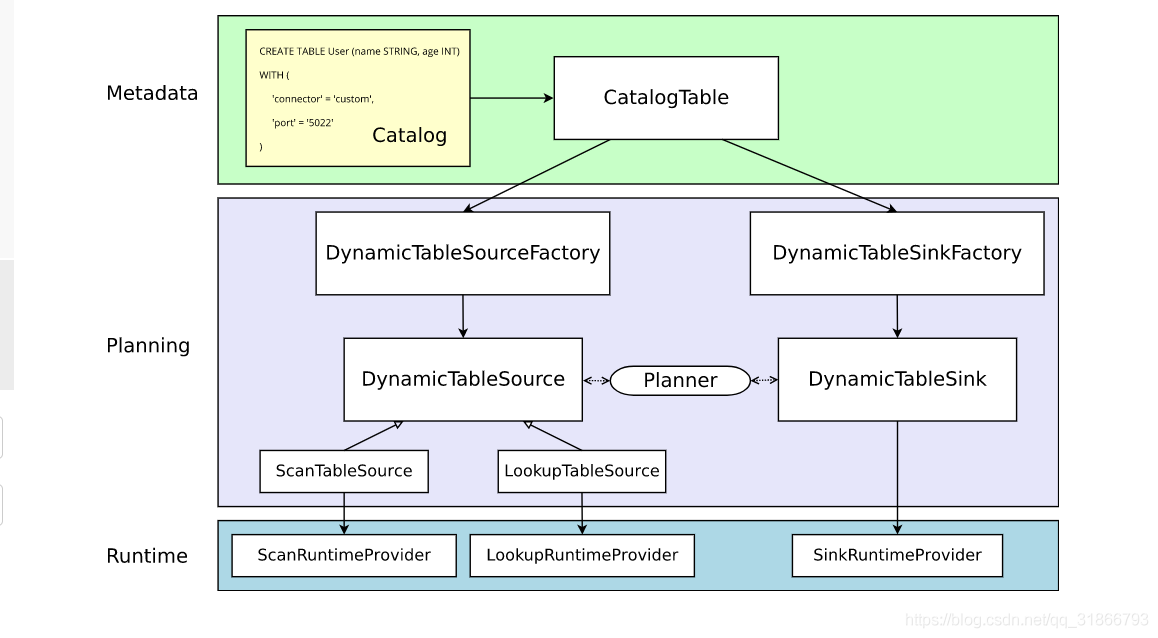
目标:在Flink代码里面支持对doris的读写操作,Flink sql on doris,将flink sql作为计算引擎。
整个流程:
2,自己开发
1)创建解析和验证选项的工厂,
2)连接器,实现表
3)实现和发现自定义格式,
4)并使用提供的工具,如数据结构转换器和FactoryUtil。
doris sink的实现开发
1,先实现 DorisDynamicTableFactory:
package org.apache.flink.connector.doris.table;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.factories.DynamicTableSinkFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.utils.TableSchemaUtils;
import java.time.Duration;
import java.util.HashSet;
import java.util.Set;
/**
* @program: flink-neiwang-dev
* @description: 1
* @author: Mr.Wang
* @create: 2020-11-12 14:04
**/
public class DorisDynamicTableSourceFactory implements DynamicTableSinkFactory {
//todo 名称叫doris
public static final String IDENTIFIER = "doris";
public static final ConfigOption<String> URL = ConfigOptions
.key("url")
.stringType()
.noDefaultValue()
.withDescription("the jdbc database url.");
public static final ConfigOption<String> TABLE_NAME = ConfigOptions
.key("table-name")
.stringType()
.noDefaultValue()
.withDescription("the jdbc table name.");
public static final ConfigOption<String> USERNAME = ConfigOptions
.key("username")
.stringType()
.noDefaultValue()
.withDescription("the jdbc user name.");
public static final ConfigOption<String> PASSWORD = ConfigOptions
.key("password")
.stringType()
.noDefaultValue()
.withDescription("the jdbc password.");
private static final ConfigOption<String> DRIVER = ConfigOptions
.key("driver")
.stringType()
.noDefaultValue()
.withDescription("the class name of the JDBC driver to use to connect to this URL. " +
"If not set, it will automatically be derived from the URL.");
// read config options
private static final ConfigOption<String> SCAN_PARTITION_COLUMN = ConfigOptions
.key("scan.partition.column")
.stringType()
.noDefaultValue()
.withDescription("the column name used for partitioning the input.");
private static final ConfigOption<Integer> SCAN_PARTITION_NUM = ConfigOptions
.key("scan.partition.num")
.intType()
.noDefaultValue()
.withDescription("the number of partitions.");
private static final ConfigOption<Long> SCAN_PARTITION_LOWER_BOUND = ConfigOptions
.key("scan.partition.lower-bound")
.longType()
.noDefaultValue()
.withDescription("the smallest value of the first partition.");
private static final ConfigOption<Long> SCAN_PARTITION_UPPER_BOUND = ConfigOptions
.key("scan.partition.upper-bound")
.longType()
.noDefaultValue()
.withDescription("the largest value of the last partition.");
private static final ConfigOption<Integer> SCAN_FETCH_SIZE = ConfigOptions
.key("scan.fetch-size")
.intType()
.defaultValue(0)
.withDescription("gives the reader a hint as to the number of rows that should be fetched, from" +
" the database when reading per round trip. If the value specified is zero, then the hint is ignored. The" +
" default value is zero.");
// look up config options
private static final ConfigOption<Long> LOOKUP_CACHE_MAX_ROWS = ConfigOptions
.key("lookup.cache.max-rows")
.longType()
.defaultValue(-1L)
.withDescription("the max number of rows of lookup cache, over this value, the oldest rows will " +
"be eliminated. \"cache.max-rows\" and \"cache.ttl\" options must all be specified if any of them is " +
"specified. Cache is not enabled as default.");
private static final ConfigOption<Duration> LOOKUP_CACHE_TTL = ConfigOptions
.key("lookup.cache.ttl")
.durationType()
.defaultValue(Duration.ofSeconds(10))
.withDescription("the cache time to live.");
private static final ConfigOption<Integer> LOOKUP_MAX_RETRIES = ConfigOptions
.key("lookup.max-retries")
.intType()
.defaultValue(3)
.withDescription("the max retry times if lookup database failed.");
// write config options
private static final ConfigOption<Integer> SINK_BUFFER_FLUSH_MAX_ROWS = ConfigOptions
.key("sink.buffer-flush.max-rows")
.intType()
.defaultValue(100)
.withDescription("the flush max size (includes all append, upsert and delete records), over this number" +
" of records, will flush data. The default value is 100.");
private static final ConfigOption<Duration> SINK_BUFFER_FLUSH_INTERVAL = ConfigOptions
.key("sink.buffer-flush.interval")
.durationType()
.defaultValue(Duration.ofSeconds(1))
.withDescription("the flush interval mills, over this time, asynchronous threads will flush data. The " +
"default value is 1s.");
private static final ConfigOption<Integer> SINK_MAX_RETRIES = ConfigOptions
.key("sink.max-retries")
.intType()
.defaultValue(3)
.withDescription("the max retry times if writing records to database failed.");
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
helper.validate();
ReadableConfig options = helper.getOptions();
TableSchema physicalSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
//todo 调用 DorisDynamicTableSink ,传入参数
return new DorisDynamicTableSink(options,physicalSchema);
}
@Override
public String factoryIdentifier() {
//todo 设置名称
return IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
/**
"WITH (\n" +
" 'connector' = 'jdbc',\n"+
" 'url' = 'jdbc:mysql://192.168.x.xx:3306/doris_test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC',\n"+
" 'driver' = 'com.mysql.jdbc.Driver',\n"+
" 'table-name' = 'flink_insert',\n"+
" 'username' = 'root',\n"+
" 'password' = '123456'\n"+
")";
*/
//todo 必要的参数
Set<ConfigOption<?>> requiredOptions = new HashSet();
requiredOptions.add(URL);
requiredOptions.add(TABLE_NAME);
requiredOptions.add(USERNAME);
requiredOptions.add(PASSWORD);
requiredOptions.add(DRIVER);
return requiredOptions;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
//todo 可选参数
Set<ConfigOption<?>> optionalOptions = new HashSet<>();
optionalOptions.add(DRIVER);
optionalOptions.add(USERNAME);
optionalOptions.add(PASSWORD);
optionalOptions.add(SCAN_PARTITION_COLUMN);
optionalOptions.add(SCAN_PARTITION_LOWER_BOUND);
optionalOptions.add(SCAN_PARTITION_UPPER_BOUND);
optionalOptions.add(SCAN_PARTITION_NUM);
optionalOptions.add(SCAN_FETCH_SIZE);
optionalOptions.add(LOOKUP_CACHE_MAX_ROWS);
optionalOptions.add(LOOKUP_CACHE_TTL);
optionalOptions.add(LOOKUP_MAX_RETRIES);
optionalOptions.add(SINK_BUFFER_FLUSH_MAX_ROWS);
optionalOptions.add(SINK_BUFFER_FLUSH_INTERVAL);
optionalOptions.add(SINK_MAX_RETRIES);
return optionalOptions;
}
}
2,然后再实现DorisDynamicTableSink
package org.apache.flink.connector.doris.table;
import doris.DorisStreamLoad;
import lombok.SneakyThrows;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.connector.jdbc.table.JdbcDynamicOutputFormatBuilder;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.connector.sink.SinkFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.RowKind;
import static org.apache.flink.util.Preconditions.checkState;
/**
* @program: flink-neiwang-dev
* @description:
* @author: Mr.Wang
* @create: 2020-11-12 12:59
**/
public class DorisDynamicTableSink implements DynamicTableSink {
private ReadableConfig options;
private TableSchema tableSchema;
public DorisDynamicTableSink(ReadableConfig options,TableSchema schema) {
this.options = options;
this.tableSchema = schema;
}
@Override
public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
//todo jdbc源码这里是做校验。
// validatePrimaryKey(requestedMode);
//todo 这里是使用模式,这里只做插入,
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
// .addContainedKind(RowKind.DELETE)
// .addContainedKind(RowKind.UPDATE_AFTER)
.build();
}
@SneakyThrows
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
//创建doris连接
String URL = options.get(DorisDynamicTableSourceFactory.URL);
String TABLE_NAME = options.get(DorisDynamicTableSourceFactory.TABLE_NAME);
final TypeInformation<RowData> rowDataTypeInformation = (TypeInformation<RowData>) context
.createTypeInformation(tableSchema.toRowDataType());
DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
SinkFunction dorisSinkFunction = new DorisSinkFunction2("", "", fieldDataTypes, tableSchema.getFieldNames());
return SinkFunctionProvider.of(dorisSinkFunction);
}
@Override
public DynamicTableSink copy() {
return new DorisDynamicTableSink(this.options,this.tableSchema);
}
@Override
public String asSummaryString() {
//todo jdbc里面是"JDBC:" + dialectName
return "doris_sink";
}
}
3,因为doris是支持的jdbc协议, 在实际测试中,发现通过jdbc协议写入doris太慢,我们需要修改插入方式,这里是实际就是stream 流写入,就是需要考虑的是
这里是单线程还是并发,在目前不确定的情况下,使用了队列,做到了单线程保证有序。
package org.apache.flink.connector.doris.table;
/**
* @program: flink-neiwang-dev
* @description:
* @author: Mr.Wang
* @create: 2020-11-12 15:25
**/
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import doris.DorisStreamLoad;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.RowKind;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.locks.ReentrantLock;
public class DorisSinkFunction2 implements SinkFunction<RowData> {
private final String job;
private final String metrics;
private final String[] fieldNames;
private final DataType[] fieldDataTypes;
private ReentrantLock reentrantLock = new ReentrantLock();
//todo 创建一个队列
public LinkedBlockingQueue<JSONObject> dorisQueue = new LinkedBlockingQueue<JSONObject>();
private List<JSONObject> jsonObjects = new ArrayList<>();
public static Long preTime = 0L;
public static Boolean firstInput = true;
private DorisStreamLoad dorisStreamLoad ;
public DorisSinkFunction2(String job, String metrics, DataType[] fieldDataTypes, String[] fieldNames) {
this.job = job;
this.metrics = metrics;
this.fieldDataTypes = fieldDataTypes;
this.fieldNames = fieldNames;
dorisStreamLoad = new DorisStreamLoad();
}
//todo 还需要考虑的问题是,如果一批数据失败了,怎么办。
@Override
public void invoke(RowData value, Context context) throws Exception {
//todo 初次进入赋值。
if (firstInput){
preTime = System.currentTimeMillis();
firstInput = false;
}
//todo 数据类型,我这里是有insert,不需要关心。
final RowKind rowKind = value.getRowKind();
//todo 这里是具体的数据发送逻辑,对接外部中间件
// RowData rowData = (RowData) value;
//todo 手动解析
// System.out.println("value = " + value);
// System.out.println("fieldNames = " + fieldNames);
// System.out.println("fieldDataTypes = " + fieldDataTypes);
JSONObject json = new JSONObject();
//
for (int i = 0; i < fieldNames.length; i++) {
String dataType = fieldDataTypes[i].toString();
String fieldName = fieldNames[i].toString();
//todo 这里写一个枚举
if ("INT".equals(dataType)) {
json.put(fieldName, value.getInt(i));
} else if ("STRING".equals(dataType)) {
//todo 这个地方一定要注意 .toString() 坑了我好久啊。
json.put(fieldName, value.getString(i).toString());
}
}
// jsonArray2.add(json);
//todo 放入队列
dorisQueue.add(json);
long timeMillis = System.currentTimeMillis();
long time = timeMillis - preTime;
if (dorisQueue.size() > 1000 || time > 1000) {
preTime = System.currentTimeMillis();
reentrantLock.lock();
try {
dorisQueue.drainTo(jsonObjects);
JSONObject [] v = new JSONObject[jsonObjects.size()];
jsonObjects.toArray( v);
dorisStreamLoad.sendData(JSON.toJSONString(v), "example_db", "join_test");
} catch (Exception ex) {
} finally {
reentrantLock.unlock();
}
}
}
}
4,doris stream load实现方式
import org.apache.commons.codec.binary.Base64; import org.apache.http.HttpHeaders; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpPut; import org.apache.http.entity.StringEntity; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.DefaultRedirectStrategy; import org.apache.http.impl.client.HttpClientBuilder; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import java.io.IOException; import java.nio.charset.StandardCharsets; public class DorisStreamLoad { private final static String DORIS_HOST = "dev-hadoop-ct7-6-143"; private final static String DORIS_DB = "stream_load"; // private final static String DORIS_TABLE = "join_test"; private final static String DORIS_USER = "root"; private final static String DORIS_PASSWORD = "root"; private final static int DORIS_HTTP_PORT = 8030; public void sendData(String content,String db ,String table) throws Exception { final String loadUrl = String.format("http://%s:%s/api/%s/%s/_stream_load", DORIS_HOST, DORIS_HTTP_PORT, db, table); // DORIS_TABLE); final HttpClientBuilder httpClientBuilder = HttpClients .custom() .setRedirectStrategy(new DefaultRedirectStrategy() { @Override protected boolean isRedirectable(String method) { return true; } }); try (CloseableHttpClient client = httpClientBuilder.build()) { HttpPut put = new HttpPut(loadUrl); StringEntity entity = new StringEntity(content, "UTF-8"); put.setHeader(HttpHeaders.EXPECT, "100-continue"); put.setHeader(HttpHeaders.AUTHORIZATION, basicAuthHeader(DORIS_USER, DORIS_PASSWORD)); put.setHeader("strip_outer_array", "true"); // the label header is optional, not necessary // use label header can ensure at most once semantics // put.setHeader("label", "39c25a5c-7000-496e-a98e-348a264c81de"); put.setHeader("format", "json"); put.setEntity(entity); try (CloseableHttpResponse response = client.execute(put)) { String loadResult = ""; if (response.getEntity() != null) { loadResult = EntityUtils.toString(response.getEntity()); } final int statusCode = response.getStatusLine().getStatusCode(); // statusCode 200 just indicates that doris be service is ok, not stream load // you should see the output content to find whether stream load is success if (statusCode != 200) { throw new IOException( String.format("Stream load failed, statusCode=%s load result=%s", statusCode, loadResult)); } System.out.println(loadResult); } } } private String basicAuthHeader(String username, String password) { final String tobeEncode = username + ":" + password; byte[] encoded = Base64.encodeBase64(tobeEncode.getBytes(StandardCharsets.UTF_8)); return "Basic " + new String(encoded); } public static void main(String[] args) throws Exception { int id1 = 1; int id2 = 10; String id3 = "ddddd"; int rowNumber = 100; String oneRow = id1 + "\t" + id2 + "\t" + id3 + "\n"; StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < rowNumber; i++) { stringBuilder.append(oneRow); } //in doris 0.9 version, you need to comment this line //refer to https://github.com/apache/incubator-doris/issues/783 stringBuilder.deleteCharAt(stringBuilder.length() - 1); String loadData = stringBuilder.toString(); DorisStreamLoad dorisStreamLoad = new DorisStreamLoad(); // dorisStreamLoad.sendData(loadData); } }
5,整合代码,优化格式.
不想整了 。。
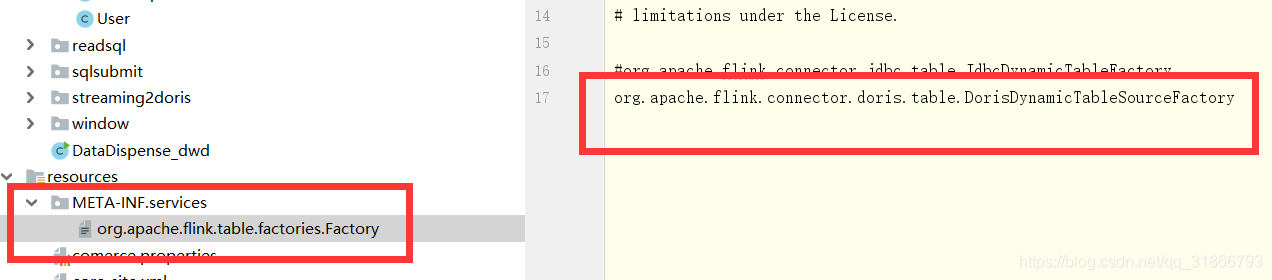
后面注意点,要加入services:
6,测试
public class DorisSqlTest2 {
private static final String DORIS_SQL = "CREATE TABLE doris_test (\n"+
" id STRING,\n" +
" name STRING\n"+
" ) WITH (\n"+
" 'connector' = 'doris',\n"+
" 'doris.host' = '192.168.6.143',\n"+
" 'doris.port' = '8030',\n"+
" 'database-name' = 'example_db',\n"+
" 'table-name' = 'test',\n"+
" 'username' = 'root',\n"+
" 'password' = 'root',\n"+
" 'window' = '10000',\n"+
" 'max.batch' = '500'\n"+
" )";
private static final String DATA_GEN = "CREATE TABLE datagen (\n" +
" id STRING,\n" +
" name STRING,\n" +
" user_age INT,\n" +
" user_other STRING,\n" +
" ts AS localtimestamp\n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='500',\n" +
" 'fields.id.length'='7',\n" +
" 'fields.user_age.min'='1',\n" +
" 'fields.user_age.max'='100',\n" +
" 'fields.name.length'='2',\n" +
" 'fields.user_other.length'='10'\n" +
")";
private static final String KAFKA_SQL ="CREATE TABLE kafkaTable (" +
" id STRING,\n" +
" name STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'test1',\n" +
" 'properties.bootstrap.servers' = 'dev-ct6-dc-worker01:9092,dev-ct6-dc-worker02:9092,dev-ct6-dc-worker03:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'json',\n" +
" 'scan.startup.mode' = 'earliest-offset'\n" +
")";
public static void main(String[] args) {
// System.out.println("DORIS_SQL = " + DORIS_SQL);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
// StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(env, bsSettings);
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(env);
bsTableEnv.executeSql(DORIS_SQL);
bsTableEnv.executeSql(DATA_GEN);
bsTableEnv.executeSql(KAFKA_SQL);
bsTableEnv.executeSql("insert into doris_test select id,name from datagen");
// bsTableEnv.executeSql("insert into kafkaTable select id,name from datagen");
}
}
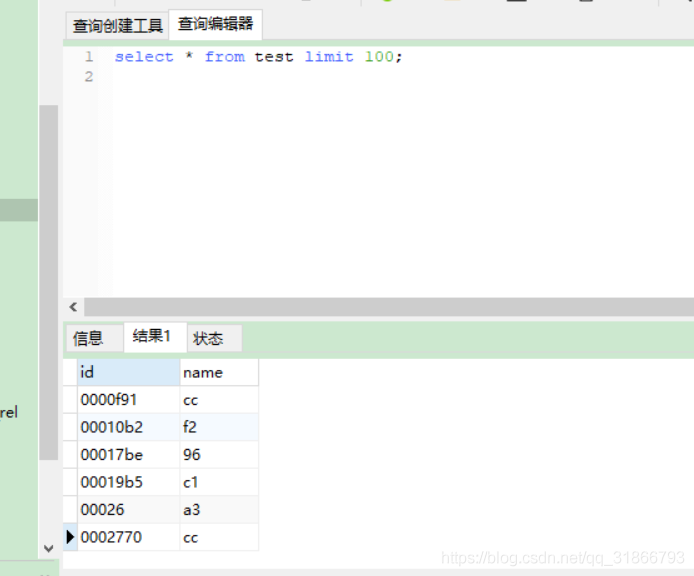
doris的表:
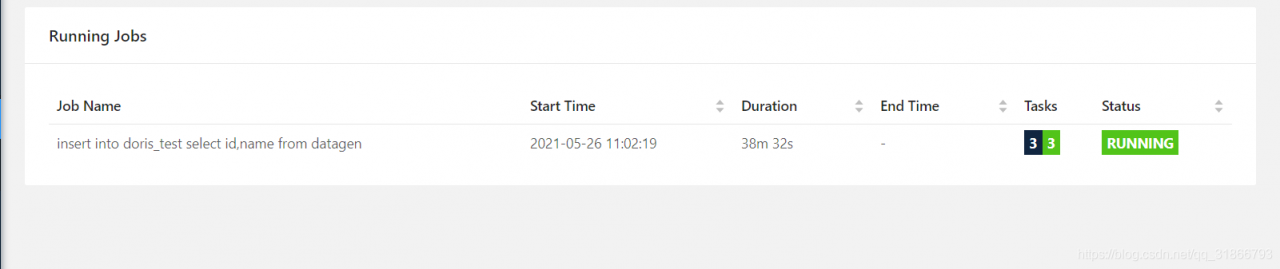
集群运行:
在zeppelin提交任务:
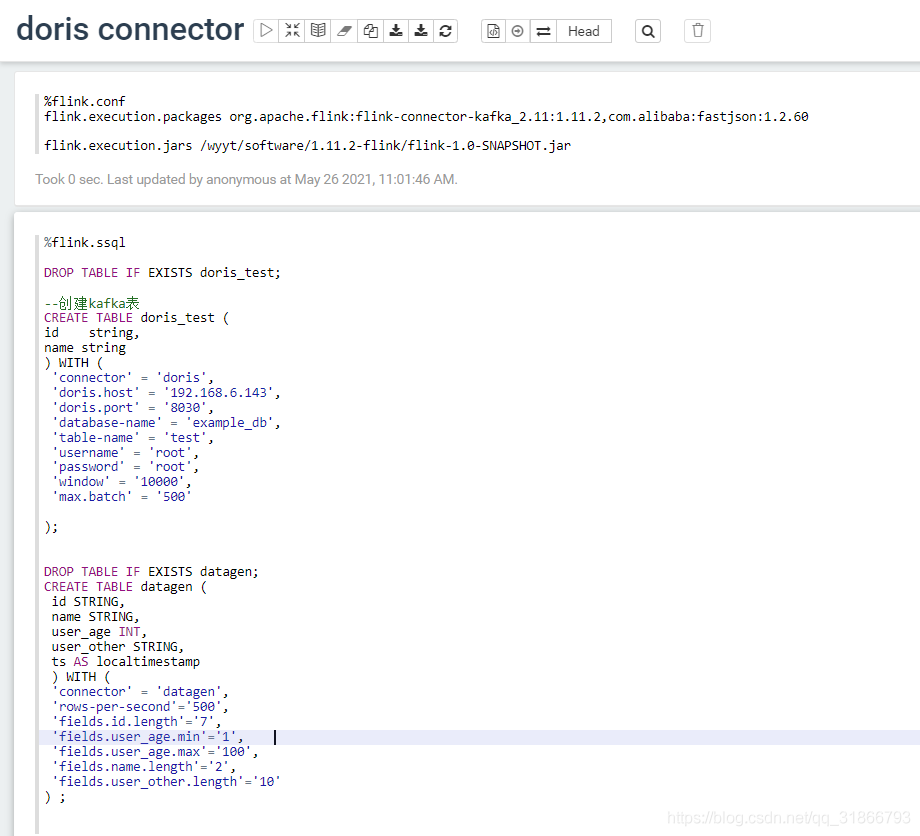
注意点:
在本地运行没问题,在集群运行报错的情况下,可能是因为打包的问题,在pom文件加上:
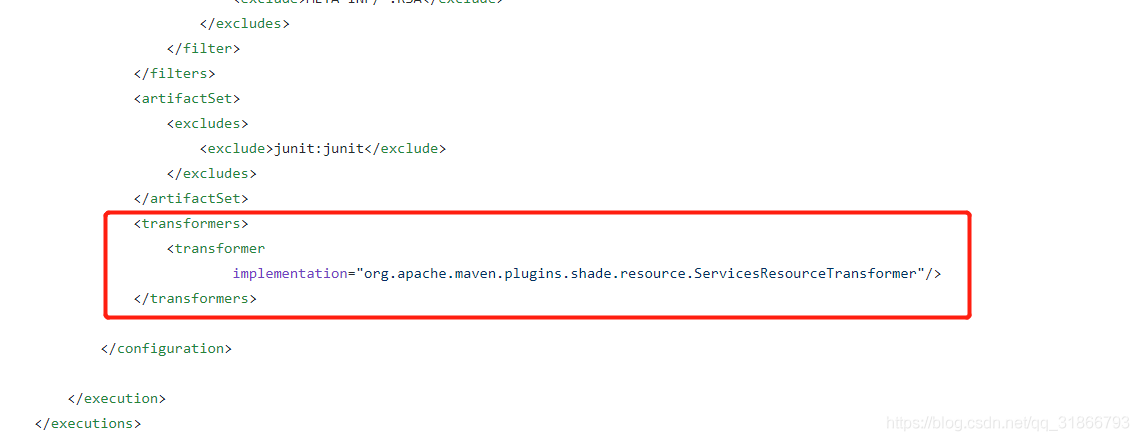
复制地址:
https://github.com/lonelyGhostisdog/flinksql/blob/master/pom.xml
最后要感谢:

博客地址:
https://blog.csdn.net/u010034713
版权声明:本文为qq_31866793原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。