对超分有兴趣的同学们可直接关注微信公众号,这个号的定位就是针对图像超分辨的,会不断更新最新的超分算法解读。
目录
正文开始
论文:Scene Text Telescope: Text-Focused Scene Image Super-Resolution
参考
复旦2021CVPR的一篇文字超分的文章,后续还有一篇(参考文献中),预计2022投AAAI的,做文字超分的同学们可以留意一下。
重点提要
- 图像对齐模块,解决双机位采集HR-LR数据集的问题。
- 新的网络映射模型,兼顾文字语义信息。替代BLSTM,采用了Self-attention+Position-Wise Feed-Forward机制。
- 文本位置监督,强化文本区域的生成,忽视非文本的背景区域。
- 引入文字识别网络,进行文本内容监督,强化文本内容清晰度。
数据集
TextZoom数据集,双机位拍摄,LR是真实图像,关于详细介绍请巴拉这篇论文。
网络结构
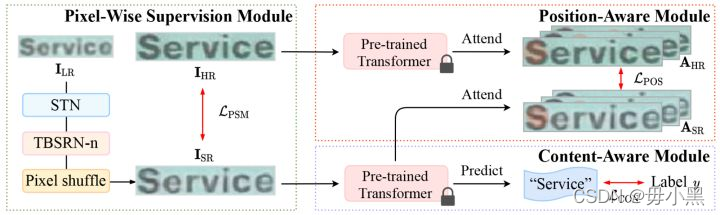
网络分为3个部分,分别为Pixel-Wise Supervision Module、Position-Aware Module、Content-Aware Module三块。
1. Pixel-Wise Supervision Module
1.1. STN
是中心对齐模块,是网络的对齐阶段。因为LR图像并不是生成的,而是直接用相机采集得到的,所以LR图像中心和HR图像中心并不一致,使用STN可以使二者中心对齐,对齐后的图像才能输入网络进行训练。
该模块仅在使用TextZoom数据集且在训练时才有用,在自己生成的数据集或网络推理阶段无效。
1.2. TBSRN-n
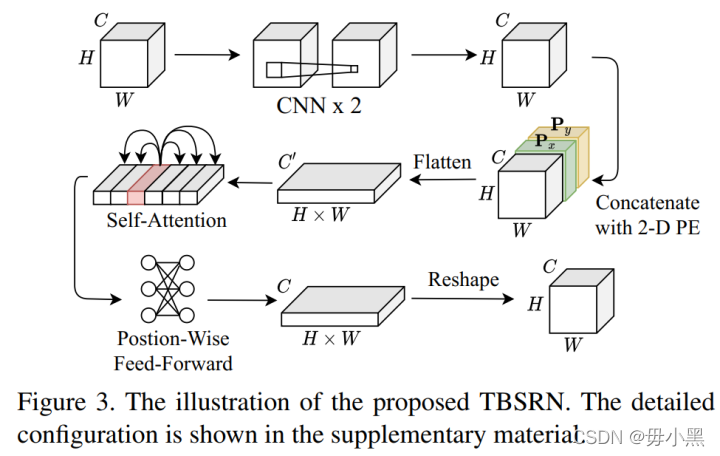
TBSRN-n是n个TBSRN模块进行堆叠得到,是网络的特征提取阶段。每一个TBSRN块如上图所示,实际上是一系列复杂的映射。输入首先经过2个连续的CNN映射,然后将映射后的特征图与Px和Py进行拼接,Px和Py的计算方式如下: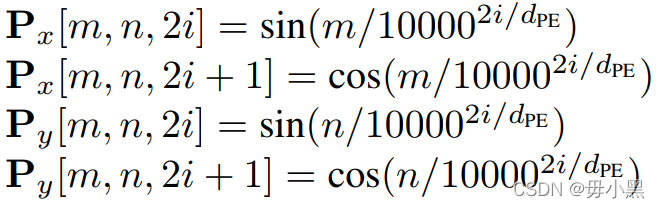
拼接后,进行展开,然后输入Self-Attention和Position-Wise Feed-Forward完成信息提取,之后重塑形状,恢复为输入时的特征图尺寸。
1.3. Pixel shuffle
是网络的上采样阶段。这是常见的上采样方式,最早应该是在EDSR中见过。在此不再描述。
之后通过L2损失计算HR和SR之间的像素级别损失得到Lpsm损失。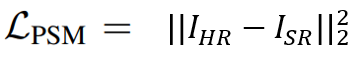
2. Position-Aware Module
为了突出文字区域的重要性而设计的,使网络更少的关注背景信息。首先训练一个基于识别模型的transformer,然后输入HR图像,该transformer将输出一系列attention maps,maps数量取决于文本lable长度。然后对SR图像也做同样的处理,可得到和HR图像对应的一系列attention maps。然后二者之间的maps通过L1损失进行计算得到损失Lpos。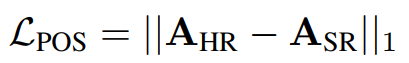
3. Content-Aware Module
这部分通过冻结刚才训练好的transformer,然后通过文字识别的方式,将识别结果与文本lable进行对比,计算损失函数,这部分的损失Lcon造成的梯度反向传播,不会影响transformer的参数(该部分参数已经被冻结),而是会影响生成网络的参数也就是Pixel-Wise Supervision Module,使其生成更逼真的文本图像。
对于低分图像中难以分辨的字符(例如c和e)作者通过训练一个变分自编码器,探索相似字符的潜在空间表征来解决。
损失函数
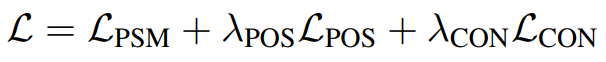
结语
这篇文章的相对复杂,有些内容需要根据代码和具体的数学推导才能弄明白,由于时间原因就不过多讲解。感兴趣的同学可以参考原论文。