实用网址:
汉字字符集编码查询: 汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode (qqxiuzi.cn)
字体编辑用中日韩汉字Unicode编码表: 字体编辑用中日韩汉字Unicode编码表 - 编著:中韩翻译网 金圣镇 (chi2ko.com)
代码页对应表格: Code Page Identifiers - Win32 apps | Microsoft Docs
本地编码查看和修改
一、在Windows平台下,cmd输入:chcp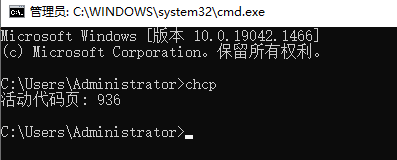
二、修改系统的默认编码
1.临时修改系统编码:直接输入“chcp 65001”,回车键(Enter键)执行,这时候该窗口编码已经是UTF-8编码了
2. 永久修改:win键+R,输入regedit
(1)按顺序找到HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Processor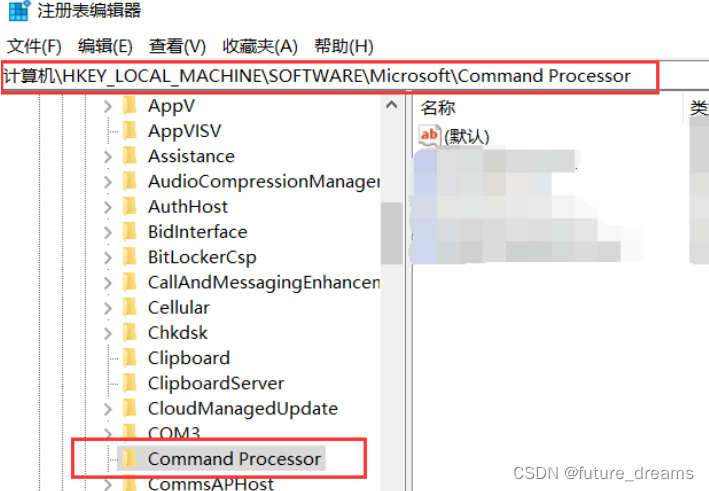
(2) 点击右键-新建,选择“字符串值”,命名为“autorun”, 点击右击修改,数值数据填写“chcp 65001”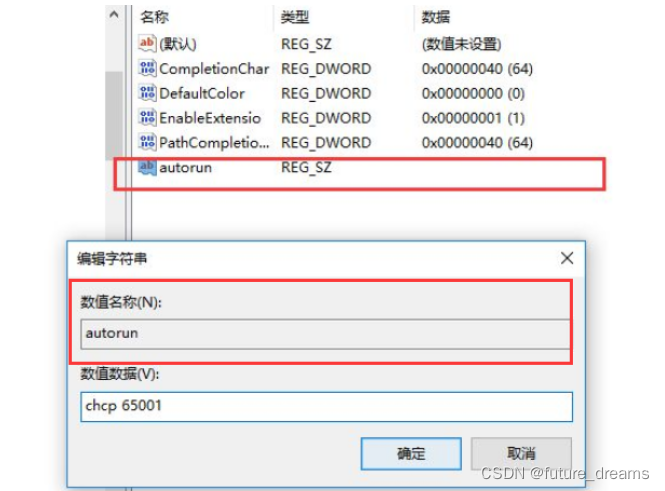
编码
ANSI编码
ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。
ASCII编码
ASCII 编码:使用1个字节(8位)来表示一个字符,一共规定了128个字符的编码。
• 0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)。
• 32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
• 65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
• ISO-8859-1:在 ASCII 码基础上,对 10000000(128) ~11111111(255)这一段进行了编码。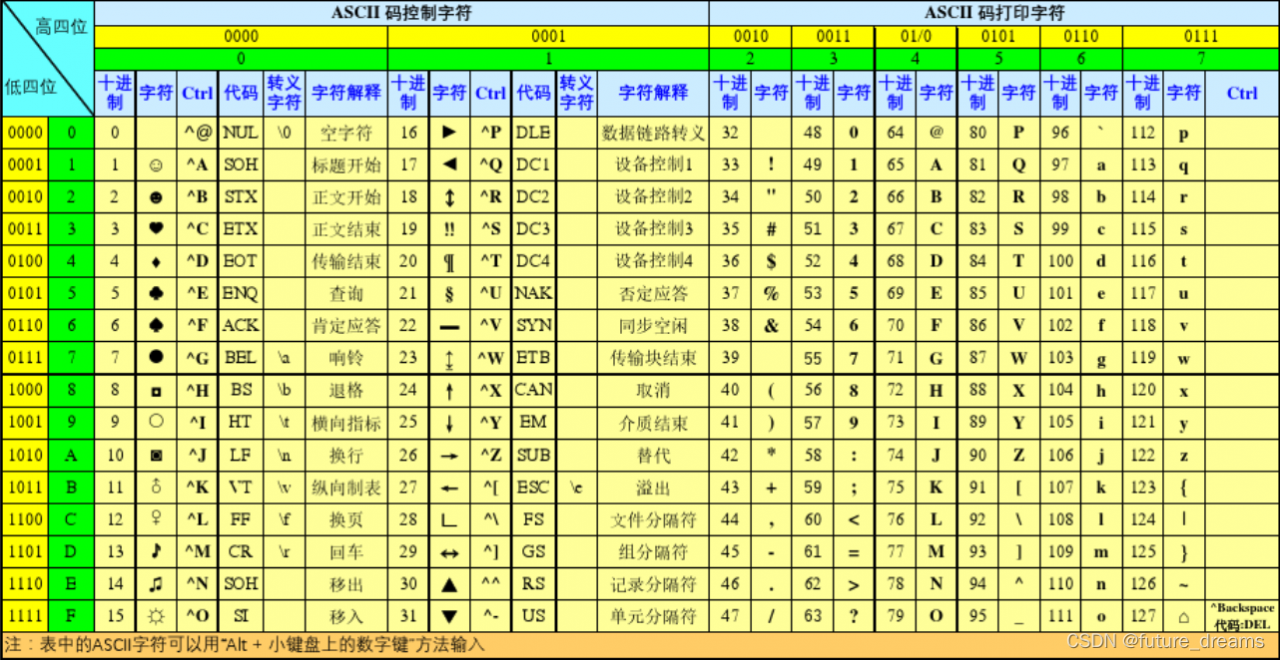
GB2312编码
GB2312编码范围:A1A1-FEFE,其中汉字编码范围:B0A1-F7FE。
GB2312编码是第一个汉字编码国家标准,由中国国家标准总局1980年发布,1981年5月1日开始使用。GB2312编码共收录汉字6763个,其中一级汉字3755个,二级汉字3008个。同时,GB2312编码收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
分区表示:
GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。这种表示方式也称为区位码。
01-09区收录除汉字外的682个字符。
10-15区为空白区,没有使用。
16-55区收录3755个一级汉字,按拼音排序。
56-87区收录3008个二级汉字,按部首/笔画排序。
88-94区为空白区,没有使用。
举例来说,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601。
双字节编码:
GB2312规定对收录的每个字符采用两个字节表示,第一个字节为“高字节”,对应94个区;第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。区号和位号分别加上0xA0就是GB2312编码。例如最后一个码位是9494,区号和位号分别转换成十六进制是5E5E,0x5E+0xA0=0xFE,所以该码位的GB2312编码是FEFE。
GB2312编码范围:A1A1-FEFE,其中汉字的编码范围为B0A1-F7FE,第一字节0xB0-0xF7(对应区号:16-87),第二个字节0xA1-0xFE(对应位号:01-94)。
查询方式:
(1)点击进入:汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode (qqxiuzi.cn)
(2)选择查询汉字,如:中,GB2312编码为D6D0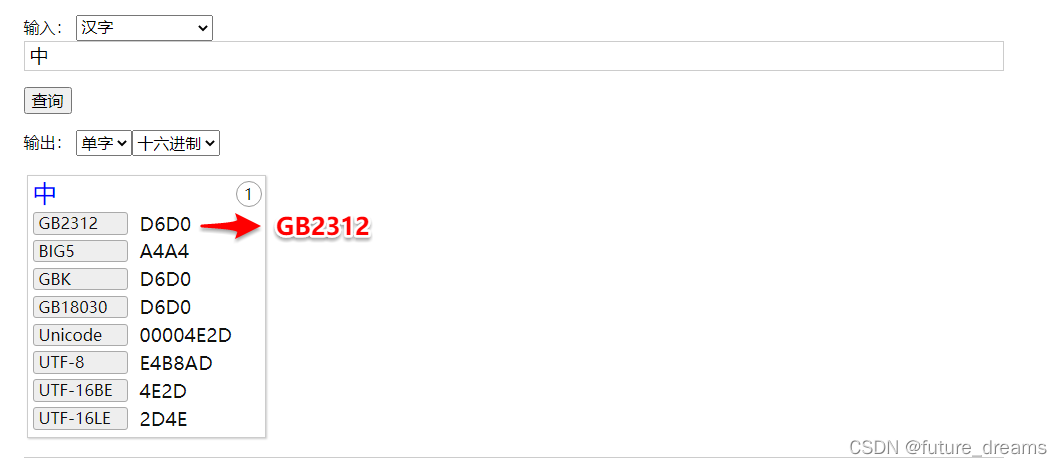
(3)计算该汉字的编码区号,D6D0中的D6是第一个字节也就是高字节,减去A0得到36的16进制数,转为10进制为54,54为该汉字的区位号,D0第二个字节为低字节,转为10进制数就是48,对照编码表中的第48位,行号4,列号8,点击进入GB2312编码表 GB2312 编码范围, GB2312 编码表 (qqxiuzi.cn)
(1)简单地说:Unicode属于字符集,不属于编码,UTF-8、UTF-16等是针对Unicode字符集的编码。
(2)UTF-8、UTF-16、UTF-32、UCS-2、UCS-4对比: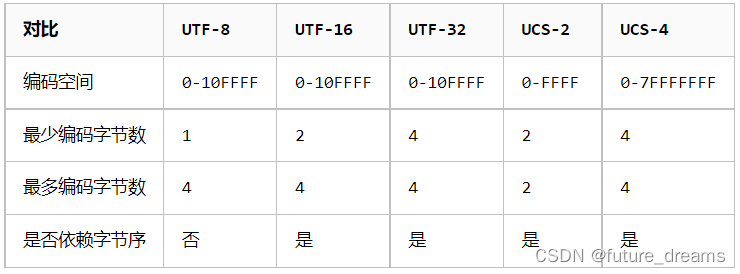
术语定义:
Unicode中的常用术语如下:
* 代码点(code point):Unicode中的每个数值都对应一个字符,这个数值就叫做代码点,通常使用十六进制表示,以“U+”开头,如U+0041表示英文字符A;
* 补充代码点:位于U+10000…U+10FFFF之间的代码点,对应的字符叫做补充字符。Unicode 2.0引入了补充字符,但直到3.1才为补充字符赋值;
* 代码空间(code space):代码点的合法范围,0至10FFFF16,即有1,114,112个代码点;
* 代码单元(code unit):能表示一个单元的编码文本的最小位的组合;
* 平面(plane):一个平面是65,536(1000016)个连续的Unicode代码点,第一个代码点是65536的整数倍。平面的编号从0至16,所以平面0包括U+0000…U+FFFF,平面1包括U+10000…U+1FFFF,…,平面16包括U+100000…U+10FFFF。平面0叫做基本多语言平面(BMP),其余平面叫做补充平面;
* 属性(property):字符的性质,如大写还是小写,是否是数字;
* 字母表(script):书写系统中字母和其他书写符号的集合,如俄语是西里尔字母表的子集;
* 区块(block):Unicode中的一组字符,如Tibetan区块包含U+0F00…U+0FFF共256个代码点。
组合字符:
Unicode中的每个代码点都对应一个字符,但是一个字符可以对应多个代码点,代码点与字符并不是一一映射。
以字符Á为例,它有两种表示方法:
* 单个代码点U+00C1;
* 两个代码点U+0041(A)与U+0301( ́)一起表示。
而对字符Ệ,则有三种表示方法:
* 单个代码点U+1EC6;
* 三个代码点U+0045(E)、U+0323( ̣)和U+0302( ̂)一起表示;
* 三个代码点U+0045(E)、U+0302( ̂)和U+0323( ̣)一起表示,注意与第二种顺序不同。
Unicode提供了许多组合字符(Combining Character或Combining Mark)修饰基本字符,正如Ệ所示,多个组合字符的顺序也可以不同。为什么会出现这样的情况呢?这是为了保证Unicode与其他字符集之间转换的简易型,如ISO 8859-1/2/3/4/9/10/14/15/16中Á的编码是C1,Unicode就使用单个代码点U+00C1表示该字符。
归一化:
组合字符为字符比较带来了问题,因为看着一样的字符实际可能是由不同代码点表示的,Unicode Standard Annex #15定义了两种相等:
* 规范相等(canonical equivalence):规范相等是一种字符或者序列间的基本相等形式,它们表示相同的抽象字符,当正确显示时总是应该有相同的外观或行为,如Ç与C和◌̧的组合;
* 兼容相等(compatibility equivalence):兼容相等则是一种较弱的相等形式,字符或者序列表示相同的抽象字符,但可以有不同的外观或行为。如ℌ与H。
Normalization FAQ指出程序总是应该使用规范相等执行比较相等的操作,最简单的方法就是归一化字符串:如果字符串被转换成了归一化形式,则规范相等的串会有完全相同的二进制表示。为了使用规范相等,可以使用Unicode标准提供的NFC与NFD归一化形式。Unicode标准一共定义了四种归一化(normalization)形式:
* Normalization Form D (NFD):规范分解;
* Normalization Form C (NFC):规范分解,接着规范组合,一般使用NFC;
* Normalization Form KD (NFKD):兼容分解;
* Normalization Form KC (NFKC):兼容分解,接着兼容组合。
组合字符对正则表达式的影响:如点号是匹配单个代码点,还是由基本字符和组合字符组成的整个代码点序列?在实践中,许多程序的点号匹配单个代码点,无论它代表基本字符还是组合字符,即Ệ(U+0045、U+0302和U+0323)由三个点号而不是一个点匹配。