算法背景
过拟合的原因:
在使用深度学习算法进行预测时,为了训练出powerful的神经网络,通常需要设计带有大量参数的神经网络。
- 但若神经网络结构复杂,同时训练数据量小时,容易造成过拟合;
- 样本噪声
- 训练集与测试集特征分布不一致
- 迭代次数过多
常用解决过拟合现象的方法:
- 数据增强
- dropout
- BN(使用BN后就不需要使用dropout)
- L1/L2,soft weight sharing
- early stop train(难以控制时间)
- 降低模型复杂度
算法原理
dropout算法就是在训练过程中,随机移除部分隐藏层的神经元,同时移除掉对应的所有输入与输出。但只是暂时移除,在下一次训练时,又在所有的神经元中随机移除固定比例的神经元。
若隐藏层含有N个神经元,总共有2N种可能的组合,但由于所有的神经网络共享参数,因此参数数量与原来相同,甚至更少。
优点:
- 在训练阶段,dropout之后神经网络会变“瘦”,这样可以避免神经网络结构太复杂,从而导致过拟合。
- 同时在预测过程中,相当于对带有更小参数的处理之后的神经网络的预测结果进行取平均值的效果,会使预测结果更准确。
算法详解
dropout结构: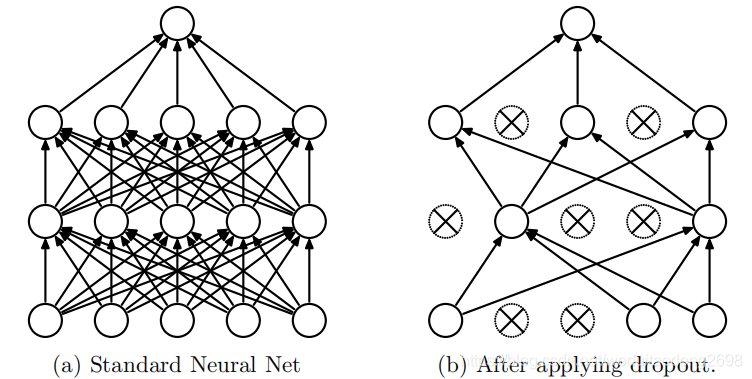
- 随机移除部分神经元;
- 移除dropout的神经元的所有输入与输出;
在训练时,只对未移除的部分采用随机梯度下降进行前向与反向传播,更行未移除部分的参数,而移除部分的参数保持不变。
原始前向传播: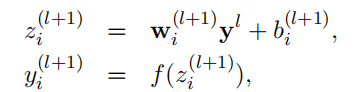
添加dropout之后的前向传播: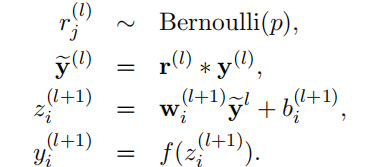
对比图: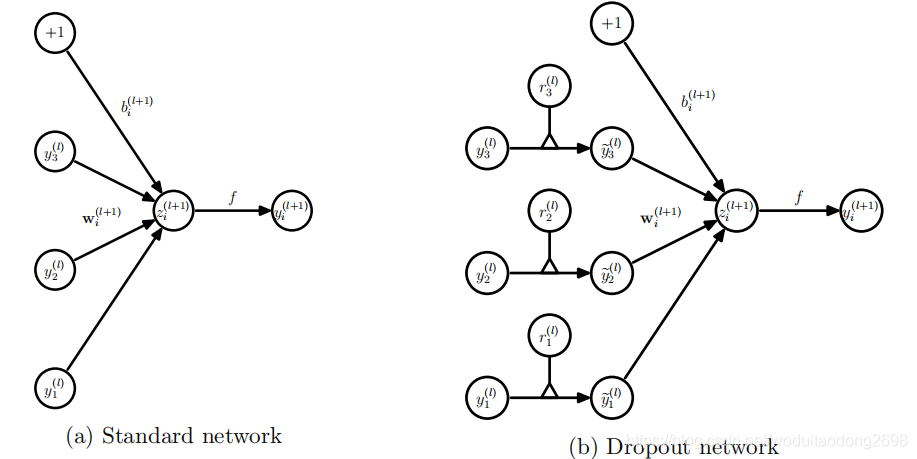
p值的选取:
r服从伯努利分布: x~B(1,p)
隐藏层会以概率p移除部分神经元,p在整个训练过程中都是固定的, 一般通过验证集确定p值的大小。
通常,p取值为0.5,最优的取值通常在0~0.5。
训练与测试
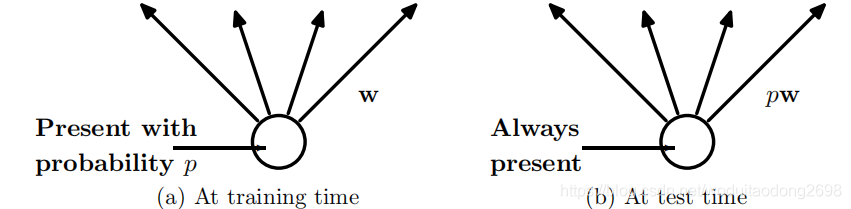
在训练与测试阶段,使用的神经网络不同:
- 在训练阶段,使用dropout训练神经网络,移除部分的神经元;
- 在测试阶段,使用完整的神经网络,但是所有的test权重参数均由train权重参数乘以p, test权重参数是train权重参数的缩小版本。
反向传播
神经网络在训练过程中使用stochastic gradient descent(SGD),使用mini-batch进行训练,前馈与反馈过程均不使用丢弃的参数,所有丢弃的参数的梯度都为0,最后每一个参数的梯度都是每一次mini-batch训练的值取平均值。
提升dropout神经网络的方法:
- 使用momentum;
- annealed learning rates;
- L2 weight decay。
- max-norm regularization
max-norm regularization
将每个隐藏单元的输入权向量的范数约束为由固定常数c限定的上界。
如果w表示任意隐藏单元上的权值向量,则神经网络在约束条件 ||w||2 ≤ c 下得到最优。
c是一个可调超参数,有验证集确定其值大小。
实验
在MNIST数据集上: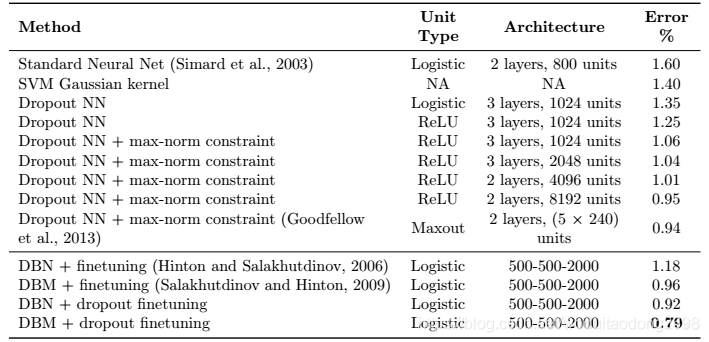
参考文献:《Dropout: A Simple way to prevent neural networks from overfitting》